Suavizado exponencial
El suavizado exponencial asigna pesos que decrecen exponencialmente a las observaciones pasadas: los valores recientes importan más que los lejanos. Es uno de los métodos de predicción más utilizados en la práctica por su sencillez, adaptabilidad y buen rendimiento empírico, especialmente en horizontes a corto plazo.
Suavizado exponencial simple (SES)
Se usa para series sin tendencia ni estacionalidad. El valor suavizado \(\hat{y}_{t+1}\) es una media ponderada de la observación actual y la predicción anterior:
\[\hat{y}_{t+1} = \alpha y_t + (1-\alpha)\hat{y}_t, \qquad 0 < \alpha \leq 1\]
Expandiendo de forma recursiva:
\[\hat{y}_{t+1} = \alpha y_t + \alpha(1-\alpha)y_{t-1} + \alpha(1-\alpha)^2 y_{t-2} + \cdots\]
Cada observación pasada recibe un peso \(\alpha(1-\alpha)^j\) en el retardo \(j\). Los pesos decrecen geométricamente: la observación de hace 5 periodos recibe un peso \(\alpha(1-\alpha)^5\).
El parámetro de suavizado \(\alpha\):
- \(\alpha\) cercano a 1: mucho peso sobre la observación más reciente, poca memoria. Reacciona rápido pero es ruidoso.
- \(\alpha\) cercano a 0: adaptación lenta, suavizado intenso. Reacciona despacio a los cambios.
- El \(\alpha\) óptimo se estima minimizando la suma de cuadrados de los errores de predicción a un paso.
Las predicciones del SES son planas: \(\hat{y}_{T+h} = \hat{y}_{T+1}\) para todo \(h > 1\). No puede extrapolar una tendencia.
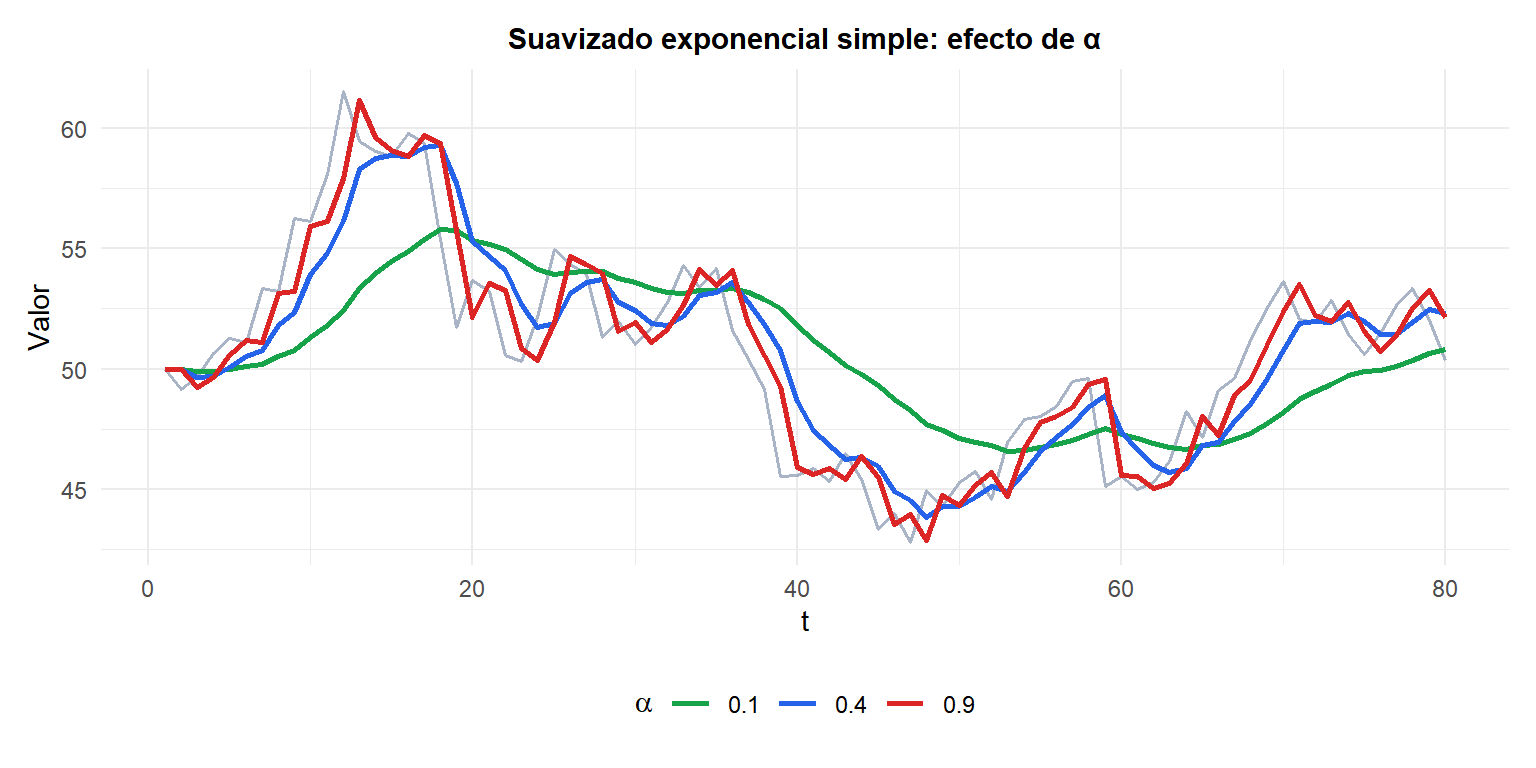
Un \(\alpha\) alto (rojo) sigue de cerca los datos pero es ruidoso. Un \(\alpha\) bajo (verde) es más suave pero más lento para adaptarse a cambios reales.
Suavizado exponencial doble (método de Holt)
Extiende el SES a series con tendencia pero sin estacionalidad. Dos ecuaciones de suavizado: una para el nivel \(\ell_t\) y otra para la tendencia \(b_t\):
\[\ell_t = \alpha y_t + (1-\alpha)(\ell_{t-1} + b_{t-1})\]
\[b_t = \beta(\ell_t - \ell_{t-1}) + (1-\beta)b_{t-1}\]
\[\hat{y}_{t+h} = \ell_t + h \cdot b_t\]
\(\alpha \in (0,1)\) suaviza el nivel; \(\beta \in (0,1)\) suaviza la tendencia. La predicción a \(h\) pasos extrapola linealmente la tendencia estimada desde el último nivel suavizado.
El método de Holt asume una tendencia aditiva constante: las predicciones a largo plazo divergen linealmente. Para tendencias amortiguadas (que suelen predecir mejor), se añade un parámetro de amortiguamiento \(\phi \in (0,1)\): \(\hat{y}_{t+h} = \ell_t + (\phi + \phi^2 + \cdots + \phi^h)b_t\).
Suavizado exponencial triple (Holt-Winters)
Añade un componente estacional al método de Holt. Dos variantes:
Aditiva (amplitud estacional constante):
\[\ell_t = \alpha(y_t - s_{t-m}) + (1-\alpha)(\ell_{t-1} + b_{t-1})\]
\[b_t = \beta(\ell_t - \ell_{t-1}) + (1-\beta)b_{t-1}\]
\[s_t = \gamma(y_t - \ell_{t-1} - b_{t-1}) + (1-\gamma)s_{t-m}\]
\[\hat{y}_{t+h} = \ell_t + h \cdot b_t + s_{t+h-m}\]
Multiplicativa (amplitud estacional proporcional al nivel): reemplaza las operaciones aditivas por multiplicativas. Se usa cuando las oscilaciones estacionales crecen con el nivel.
\(m\) es la longitud de la estación (12 para datos mensuales, 4 para trimestrales). Se trata con más detalle en el artículo sobre Holt-Winters.
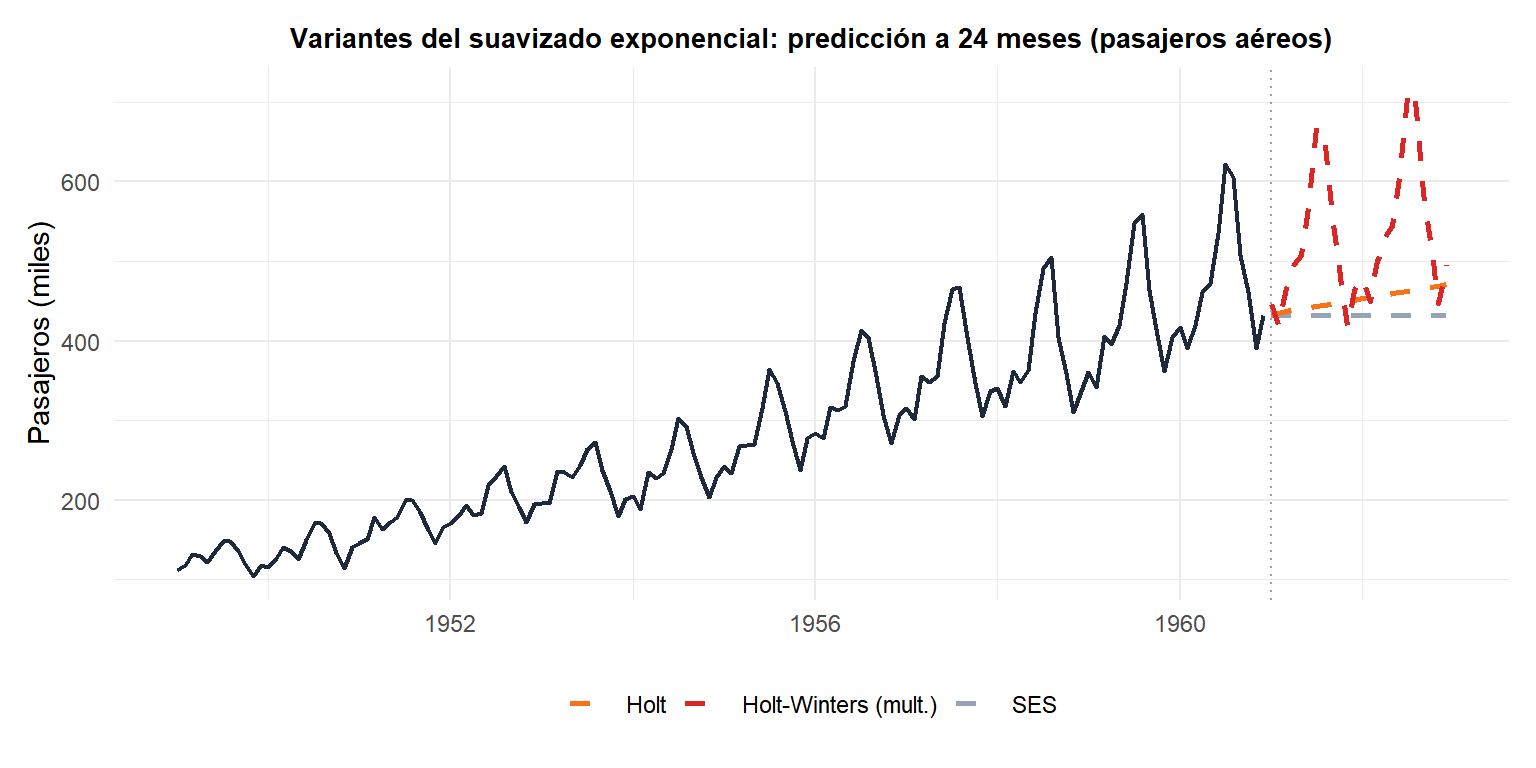
El SES (gris) produce una predicción plana. Holt (naranja) captura la tendencia pero no la estacionalidad. Holt-Winters multiplicativo (rojo) captura tanto la tendencia como la amplitud estacional creciente: el más preciso para esta serie.
El marco ETS
Todos los métodos de suavizado exponencial son casos especiales del marco ETS (Error, Tendencia, Estacionalidad), que proporciona una representación unificada en espacio de estados:
- Error: aditivo (A) o multiplicativo (M).
- Tendencia: ninguna (N), aditiva (A), aditiva amortiguada (Ad).
- Estacionalidad: ninguna (N), aditiva (A), multiplicativa (M).
Ejemplos: ETS(A,N,N) = SES; ETS(A,A,N) = método de Holt; ETS(M,A,M) = Holt-Winters multiplicativo.
El marco ETS permite la selección del modelo por AIC y proporciona intervalos de predicción adecuados mediante la representación en espacio de estados. Se implementa en la función ets() de R, que selecciona automáticamente el mejor modelo.
⚠️ El suavizado exponencial no es adecuado para todas las series
El suavizado exponencial funciona mejor para series con una estructura estable (nivel, tendencia, estacionalidad) que cambia lentamente. Puede rendir peor en:
- Series con cambios estructurales o variaciones bruscas de tendencia.
- Series cuyo comportamiento futuro depende de variables externas (usa ARIMAX o regresión en su lugar).
- Series con patrones de autocorrelación complejos que requieren modelización AR/MA explícita.
Para series con factores externos claros (p. ej., ventas influidas por promociones, demanda influida por la temperatura), los modelos de regresión o ARIMAX son más apropiados.
💡 Suavizado exponencial en R
library(forecast)
# Suavizado exponencial simple
ses(y, h = 12)
# Método de Holt (tendencia, sin estacionalidad)
holt(y, h = 12, damped = TRUE) # la tendencia amortiguada suele predecir mejor
# Holt-Winters
hw(y, h = 12, seasonal = "multiplicative") # o "additive"
# Selección automática del modelo ETS
fit <- ets(y)
summary(fit)
forecast(fit, h = 12)La función ets() selecciona el mejor modelo ETS por AIC, eligiendo entre todas las combinaciones de componentes de error, tendencia y estacionalidad.

