Modelo ARIMA
ARIMA(\(p,d,q\)) extiende ARMA(\(p,q\)) a series no estacionarias diferenciando \(d\) veces. Las \(d\) diferencias eliminan las tendencias estocásticas (raíces unitarias), dejando una serie estacionaria a la que se aplica el ARMA(\(p,q\)). Es la clase de modelos más ampliamente utilizada para la predicción univariante de series de tiempo.
Definición
Una serie \(y_t\) sigue un ARIMA(\(p,d,q\)) si \(w_t = \Delta^d y_t = (1-L)^d y_t\) sigue un ARMA(\(p,q\)) estacionario:
\[\Phi(L)(1-L)^d y_t = \Theta(L)\varepsilon_t\]
\[\Phi(L) = 1 - \phi_1 L - \cdots - \phi_p L^p, \qquad \Theta(L) = 1 + \theta_1 L + \cdots + \theta_q L^q\]
Los tres parámetros:
- \(p\): orden AR (número de retardos autorregresivos).
- \(d\): grado de diferenciación (orden de integración). \(d=0\) da ARMA; \(d=1\) es el caso más habitual.
- \(q\): orden MA (número de términos de media móvil).
Casos especiales: ARIMA(1,0,0) = AR(1); ARIMA(0,1,0) = paseo aleatorio; ARIMA(0,1,1) = media móvil ponderada exponencialmente (EWMA).
La metodología Box-Jenkins
El procedimiento sistemático para identificar y ajustar modelos ARIMA, propuesto por Box y Jenkins (1970):
Paso 1: Identificación. Representar la serie gráficamente. Aplicar logaritmo o Box-Cox si la varianza no es constante. Contrastar raíces unitarias (ADF, KPSS). Diferenciar \(d\) veces hasta lograr estacionariedad. Examinar la ACF y la PACF de la serie diferenciada para identificar candidatos a \(p\) y \(q\).
Paso 2: Estimación. Ajustar el ARIMA(\(p,d,q\)) candidato por MV. Comparar modelos por AIC y BIC.
Paso 3: Diagnóstico. Comprobar que los residuos son ruido blanco: ACF de residuos, test de Ljung-Box. Si los residuos muestran autocorrelación, revisar \(p\) o \(q\).
Paso 4: Predicción. Usar el modelo ajustado para obtener predicciones puntuales e intervalos de predicción.
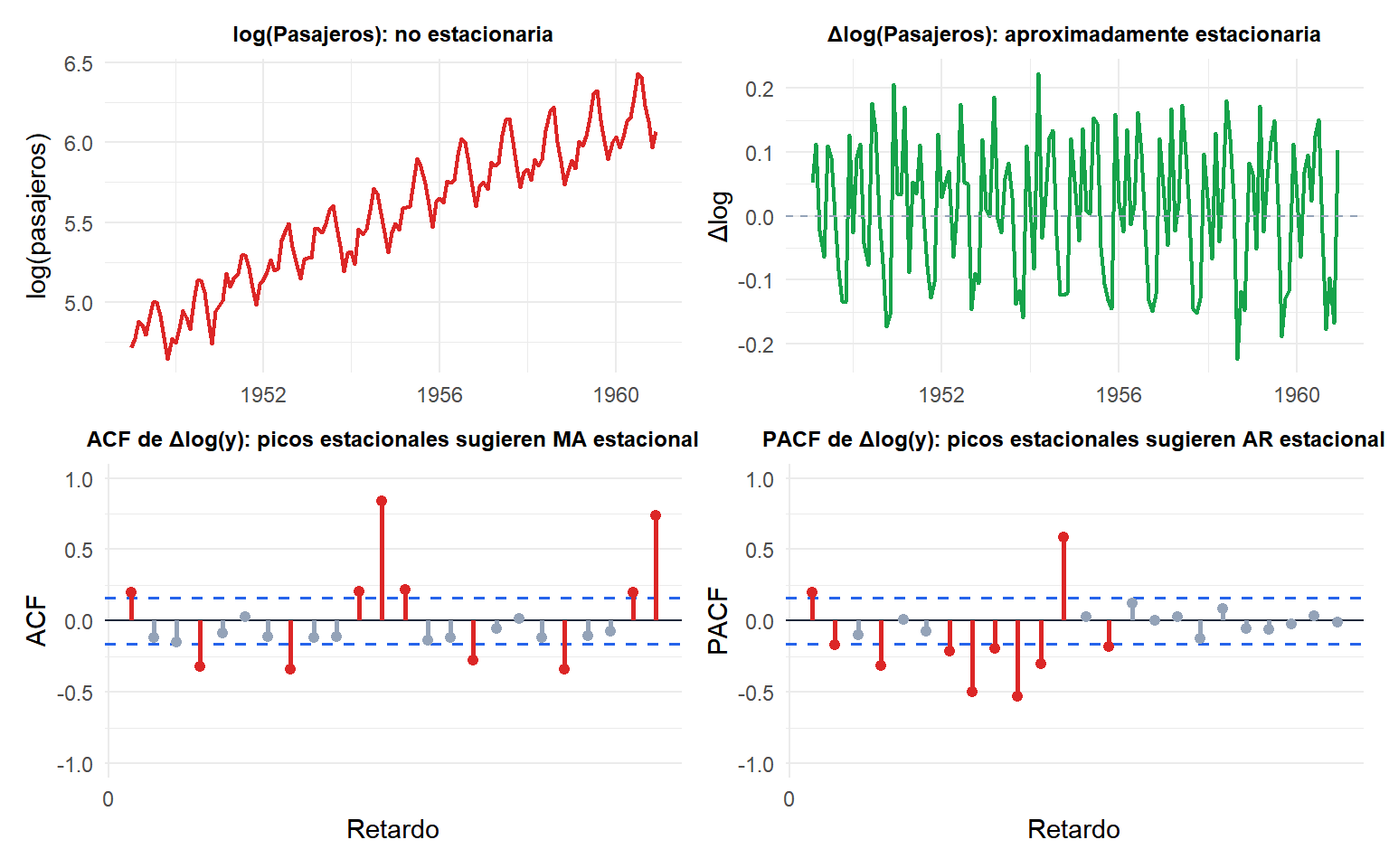
La serie logarítmica original es no estacionaria (tendencia ascendente). Tras una diferenciación es aproximadamente estacionaria. La ACF y la PACF de \(\Delta\log(y)\) siguen mostrando picos estacionales en los retardos 12 y 24, lo que sugiere que se necesita una extensión estacional (SARIMA).
Elección de d
\(d\) se determina mediante contraste de raíces unitarias:
- Aplicar ADF y KPSS a la serie original.
- Si es no estacionaria, diferenciar una vez y volver a contrastar.
- Detenerse cuando ambos tests coincidan en que la serie es estacionaria.
- Para la mayoría de series económicas y financieras, \(d = 1\) es suficiente. \(d = 2\) es infrecuente y a menudo indica sobrediferenciación.
En R: forecast::ndiffs(y) automatiza esto usando tests ADF secuenciales.
⚠️ La sobrediferenciación empeora las predicciones
Aplicar \(d = 2\) cuando \(d = 1\) es suficiente introduce una raíz unitaria en el polinomio MA, produciendo estimaciones de parámetros inestables y predicciones que se dispersan excesivamente. Señales de sobrediferenciación: la ACF de \(\Delta^d y_t\) comienza con un valor negativo grande en el retardo 1.
La infradiferenciación (usar \(d = 0\) para una serie que necesita \(d = 1\)) produce residuos no estacionarios con media errante y varianza creciente.
Ejemplo: ARIMA(1,1,1)
Ajustamos un ARIMA(1,1,1) a la tasa de desempleo mensual de EE.UU. (una serie económica no estacionaria clásica).
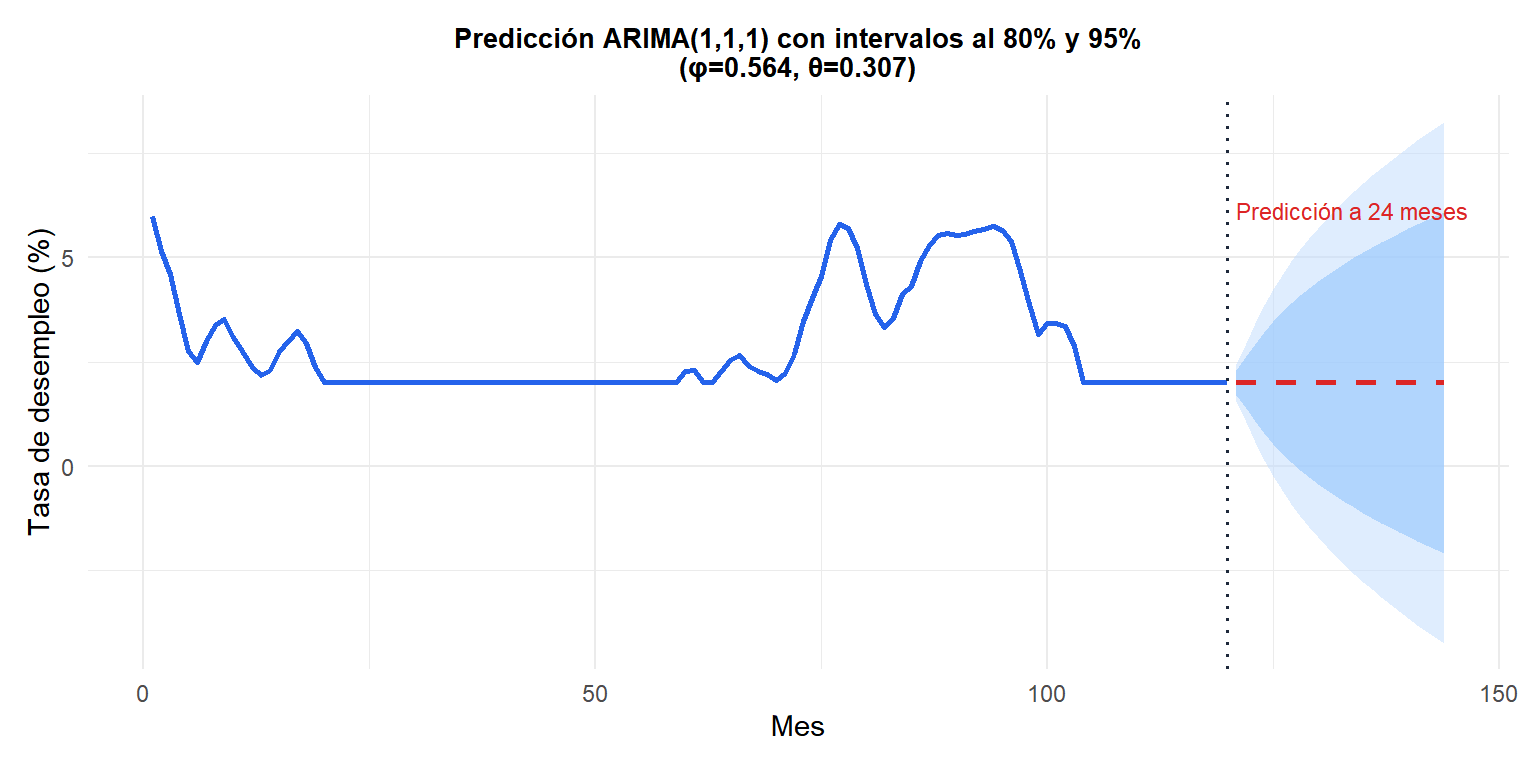
Los intervalos de predicción se ensanchan con el horizonte: las predicciones del ARIMA(1,1,1) siguen la tendencia reciente, con una incertidumbre que crece linealmente en varianza. Las bandas al 80% (más oscuro) y al 95% (más claro) reflejan esto.
ARIMA vs ARMA
| ARMA(\(p,q\)) | ARIMA(\(p,d,q\)) | |
|---|---|---|
| Requiere estacionariedad | Sí | No (gestiona series \(I(d)\)) |
| Maneja tendencias | No | Sí (mediante diferenciación) |
| Predicción a largo plazo | Revierte a media constante | Sigue una tendencia estocástica |
| Caso especial \(d = 0\) | Sí (ARIMA = ARMA) | - |
💡 ARIMA en R
# Especificación manual
arima(y, order = c(1, 1, 1))
# Selección automática por AIC (Box-Jenkins automatizado)
library(forecast)
auto.arima(y)
# Diagnóstico de residuos
checkresiduals(fit)
# Predicción 12 periodos adelante
forecast(fit, h = 12)auto.arima() aplica la metodología Box-Jenkins automáticamente: contrasta raíces unitarias para elegir \(d\) y busca en el espacio \((p, q)\) por AIC. Es el punto de partida recomendado para cualquier análisis ARIMA.

