Teorema de Bayes
El teorema de Bayes indica cómo actualizar una probabilidad cuando llega nueva evidencia. Conecta lo que sabías antes (la distribución a priori) con lo que dicen los datos (la verosimilitud) para producir una creencia actualizada (la distribución a posteriori). Es el fundamento matemático del razonamiento racional bajo incertidumbre.
Definición
Para dos eventos \(A\) y \(B\) con \(P(B) > 0\):
\[P(A \mid B) = \frac{P(B \mid A) \cdot P(A)}{P(B)}\]
Cada componente tiene un nombre y un papel:
| Término | Notación | Significado |
|---|---|---|
| A priori | \(P(A)\) | Probabilidad de \(A\) antes de observar \(B\) |
| Verosimilitud | \(P(B \mid A)\) | Probabilidad de observar \(B\) si \(A\) es cierto |
| A posteriori | \(P(A \mid B)\) | Probabilidad actualizada de \(A\) tras observar \(B\) |
| Verosimilitud marginal | \(P(B)\) | Probabilidad total de observar \(B\) (constante normalizadora) |
Cuando el espacio de hipótesis tiene múltiples alternativas \(A_1, \ldots, A_n\) formando una partición, el denominador se expande mediante la ley de la probabilidad total:
\[P(A_i \mid B) = \frac{P(B \mid A_i) \cdot P(A_i)}{\displaystyle\sum_{j=1}^{n} P(B \mid A_j) \cdot P(A_j)}\]
Actualización bayesiana: de la distribución a priori a la a posteriori
La idea clave del teorema de Bayes es que describe un proceso de actualización de creencias. Empiezas con una distribución a priori, observas evidencia y llegas a una distribución a posteriori. La a posteriori de una observación se convierte en la a priori de la siguiente.
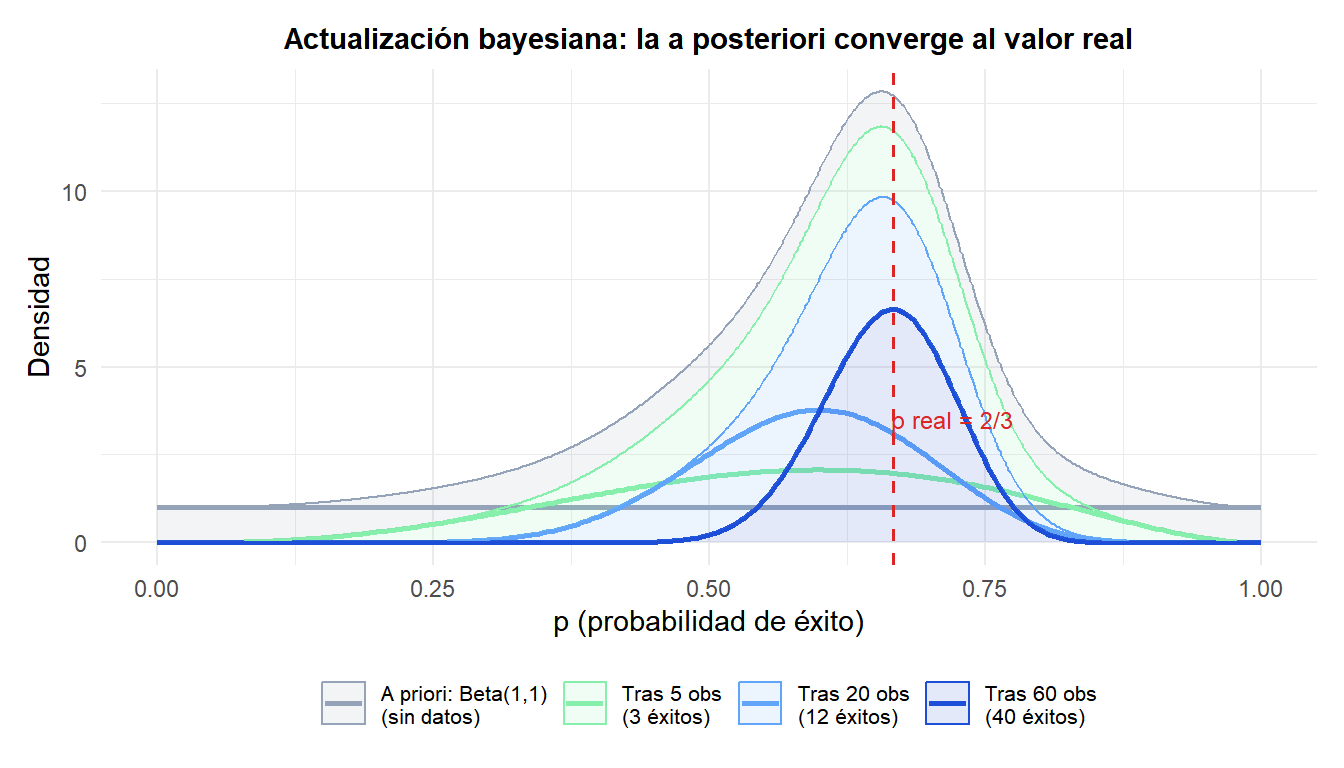
Con una distribución a priori plana (todos los valores de \(p\) igualmente plausibles), cada lote de observaciones desplaza y estrecha la a posteriori. Tras 60 observaciones, la distribución está concentrada alrededor del valor real de \(2/3\).
Ejemplos paso a paso
Ejemplo 1: diagnóstico médico
Una enfermedad rara afecta al 0,5% de la población. Un test de cribado tiene:
- Sensibilidad: \(P(+ \mid E) = 0{,}92\)
- Tasa de falsos positivos: \(P(+ \mid E^c) = 0{,}04\)
Un paciente da positivo. ¿Cuál es la probabilidad de que tenga la enfermedad?
A priori: \(P(E) = 0{,}005\), \(P(E^c) = 0{,}995\)
Verosimilitud marginal mediante la ley de la probabilidad total:
\[P(+) = 0{,}92 \times 0{,}005 + 0{,}04 \times 0{,}995 = 0{,}0046 + 0{,}0398 = 0{,}0444\]
A posteriori:
\[P(E \mid +) = \frac{0{,}92 \times 0{,}005}{0{,}0444} = \frac{0{,}0046}{0{,}0444} \approx 0{,}104\]
Solo el 10,4% de las personas que dan positivo tienen realmente la enfermedad. El test es bastante preciso, pero la enfermedad es tan rara que los falsos positivos dominan.
De 10.000 personas:
- 50 tienen la enfermedad. De ellas, \(50 \times 0{,}92 = 46\) dan positivo (verdaderos positivos).
- 9.950 están sanas. De ellas, \(9950 \times 0{,}04 = 398\) dan positivo (falsos positivos).
Total de positivos: \(46 + 398 = 444\).
\[P(E \mid +) = \frac{46}{444} \approx 0{,}104 \checkmark\]
Las frecuencias naturales hacen el resultado intuitivo: de 444 tests positivos, solo 46 son casos reales.
Ejemplo 2: filtro de spam con múltiples palabras
Un filtro de spam parte de la distribución a priori \(P(\text{spam}) = 0{,}30\). La palabra “urgente” aparece en:
- El 45% de los correos spam: \(P(\text{urgente} \mid \text{spam}) = 0{,}45\)
- El 3% de los correos legítimos: \(P(\text{urgente} \mid \text{legít.}) = 0{,}03\)
Tras observar “urgente”:
\[P(\text{urgente}) = 0{,}45 \times 0{,}30 + 0{,}03 \times 0{,}70 = 0{,}135 + 0{,}021 = 0{,}156\]
\[P(\text{spam} \mid \text{urgente}) = \frac{0{,}45 \times 0{,}30}{0{,}156} \approx 0{,}865\]
La a posteriori (86,5%) se convierte en la nueva a priori para la siguiente palabra. Si el correo también contiene “ganador”:
- \(P(\text{ganador} \mid \text{spam}) = 0{,}60\), \(P(\text{ganador} \mid \text{legít.}) = 0{,}01\)
\[P(\text{spam} \mid \text{urgente, ganador}) = \frac{0{,}60 \times 0{,}865}{0{,}60 \times 0{,}865 + 0{,}01 \times 0{,}135} \approx \frac{0{,}519}{0{,}519 + 0{,}00135} \approx 0{,}997\]
Prácticamente certeza de spam tras solo dos palabras sospechosas. Esta actualización secuencial es el núcleo de los clasificadores Naive Bayes.
Ejemplo 3: tres hipótesis en competencia
Un analista de calidad encuentra un componente defectuoso. Vino de uno de tres proveedores:
- El proveedor X suministra el 50% de las piezas, con una tasa de defectos del 2%.
- El proveedor Y suministra el 30%, con una tasa de defectos del 5%.
- El proveedor Z suministra el 20%, con una tasa de defectos del 8%.
A priori: \(P(X) = 0{,}50\), \(P(Y) = 0{,}30\), \(P(Z) = 0{,}20\)
Verosimilitud marginal:
\[P(\text{defecto}) = 0{,}02 \times 0{,}50 + 0{,}05 \times 0{,}30 + 0{,}08 \times 0{,}20 = 0{,}010 + 0{,}015 + 0{,}016 = 0{,}041\]
A posteriori:
\[P(X \mid \text{defecto}) = \frac{0{,}02 \times 0{,}50}{0{,}041} \approx 0{,}244\]
\[P(Y \mid \text{defecto}) = \frac{0{,}05 \times 0{,}30}{0{,}041} \approx 0{,}366\]
\[P(Z \mid \text{defecto}) = \frac{0{,}08 \times 0{,}20}{0{,}041} \approx 0{,}390\]
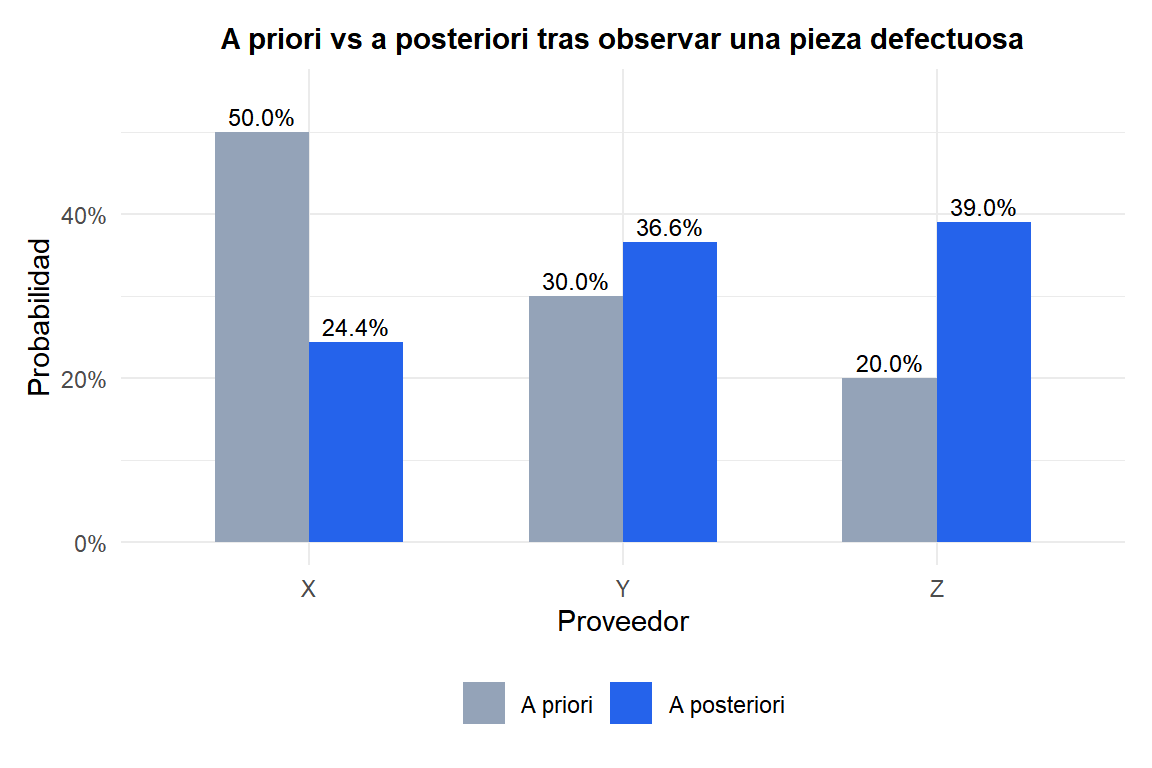
El proveedor Z salta de un 20% a priori a un 39% a posteriori: aunque suministra la menor cantidad de piezas, su alta tasa de defectos lo convierte en el origen más probable de cualquier defecto encontrado.
La falacia del fiscal
⚠️ P(evidencia | inocente) no es P(inocente | evidencia)
La falacia del fiscal consiste en confundir la verosimilitud \(P(E \mid H)\) con la a posteriori \(P(H \mid E)\). Un ejemplo clásico:
- Una prueba de ADN coincide con el sospechoso con probabilidad \(P(\text{coincidencia} \mid \text{inocente}) = 1/1{.}000{.}000\).
- Un fiscal afirma: “Hay solo una probabilidad de 1 entre un millón de que el sospechoso sea inocente.”
Esto es incorrecto. \(P(\text{coincidencia} \mid \text{inocente})\) no es \(P(\text{inocente} \mid \text{coincidencia})\). El cálculo correcto requiere la probabilidad a priori de que el sospechoso sea culpable, el tamaño de la población y la probabilidad de una coincidencia fortuita. En una ciudad de un millón de habitantes, cabría esperar que también una persona inocente coincidiera con el perfil de ADN. La probabilidad a posteriori de inocencia dada la coincidencia podría ser del 50%, no de 1 entre un millón.
Este error ha contribuido a condenas erróneas. El teorema de Bayes es la herramienta correcta para evaluar la evidencia forense.
Interpretación frecuentista vs bayesiana
El teorema de Bayes en sí es matemáticamente incuestionable: se deriva directamente de la definición de probabilidad condicionada. El debate es sobre cómo usarlo:
- Los frecuentistas aceptan el teorema de Bayes como regla de probabilidad, pero rechazan la idea de asignar probabilidades a priori a hipótesis (que consideran fijas, no aleatorias). Solo lo usan cuando \(A\) es un evento aleatorio con una frecuencia bien definida.
- Los bayesianos usan el teorema de Bayes como la regla general para actualizar cualquier grado de creencia, incluidas las creencias sobre parámetros fijos pero desconocidos. La distribución a priori codifica el conocimiento o los supuestos previos, y la a posteriori resume lo que se sabe tras ver los datos.
En la práctica, los métodos bayesianos se usan en machine learning (Naive Bayes, redes bayesianas), diseño de ensayos clínicos, tests A/B y cualquier ámbito donde incorporar conocimiento previo sea valioso.
💡 La receta en tres pasos para aplicar el teorema de Bayes
Toda aplicación del teorema de Bayes sigue la misma estructura:
- Establece la distribución a priori \(P(A)\): ¿qué crees antes de ver la evidencia?
- Especifica la verosimilitud \(P(B \mid A)\): ¿qué tan probable es la evidencia bajo cada hipótesis?
- Calcula la verosimilitud marginal \(P(B)\) usando la ley de la probabilidad total.
- Aplica el teorema de Bayes para obtener la a posteriori \(P(A \mid B)\).
La a posteriori responde a la pregunta que realmente importa. La verosimilitud responde a la pregunta inversa, que suele ser más fácil de medir (un laboratorio puede medir la sensibilidad del test; un paciente quiere conocer su riesgo).

