Descenso del gradiente
El descenso del gradiente minimiza una función diferenciable \(f(x)\) moviéndose repetidamente en la dirección opuesta al gradiente, que es la dirección de mayor ascenso. Es el algoritmo base del entrenamiento de redes neuronales, la regresión logística y prácticamente cualquier modelo de machine learning a gran escala.
Intuición
Imagina que estás en un paisaje montañoso con niebla densa. No puedes ver el valle, pero sí notas la inclinación del terreno bajo tus pies. La estrategia de mayor descenso: en cada paso, muévete en la dirección en la que el suelo baja más pronunciadamente. Repite hasta llegar a un punto llano.
El gradiente \(\nabla f(x)\) apunta en la dirección de mayor ascenso. Moverse en sentido contrario, \(-\nabla f(x)\), da la dirección de mayor descenso. El tamaño del paso (cuánto avanzar) lo controla la tasa de aprendizaje \(\alpha > 0\).
La regla de actualización
\[x_{k+1} = x_k - \alpha \nabla f(x_k)\]
Partiendo de un punto inicial \(x_0\), esta regla se aplica de forma iterativa hasta que se cumpla un criterio de parada: \(\|\nabla f(x_k)\| < \varepsilon\), se alcanza el número máximo de iteraciones, o la mejora en \(f\) cae por debajo de un umbral.
Para una función de una variable: \(x_{k+1} = x_k - \alpha f'(x_k)\). La actualización resta la pendiente escalada por \(\alpha\).
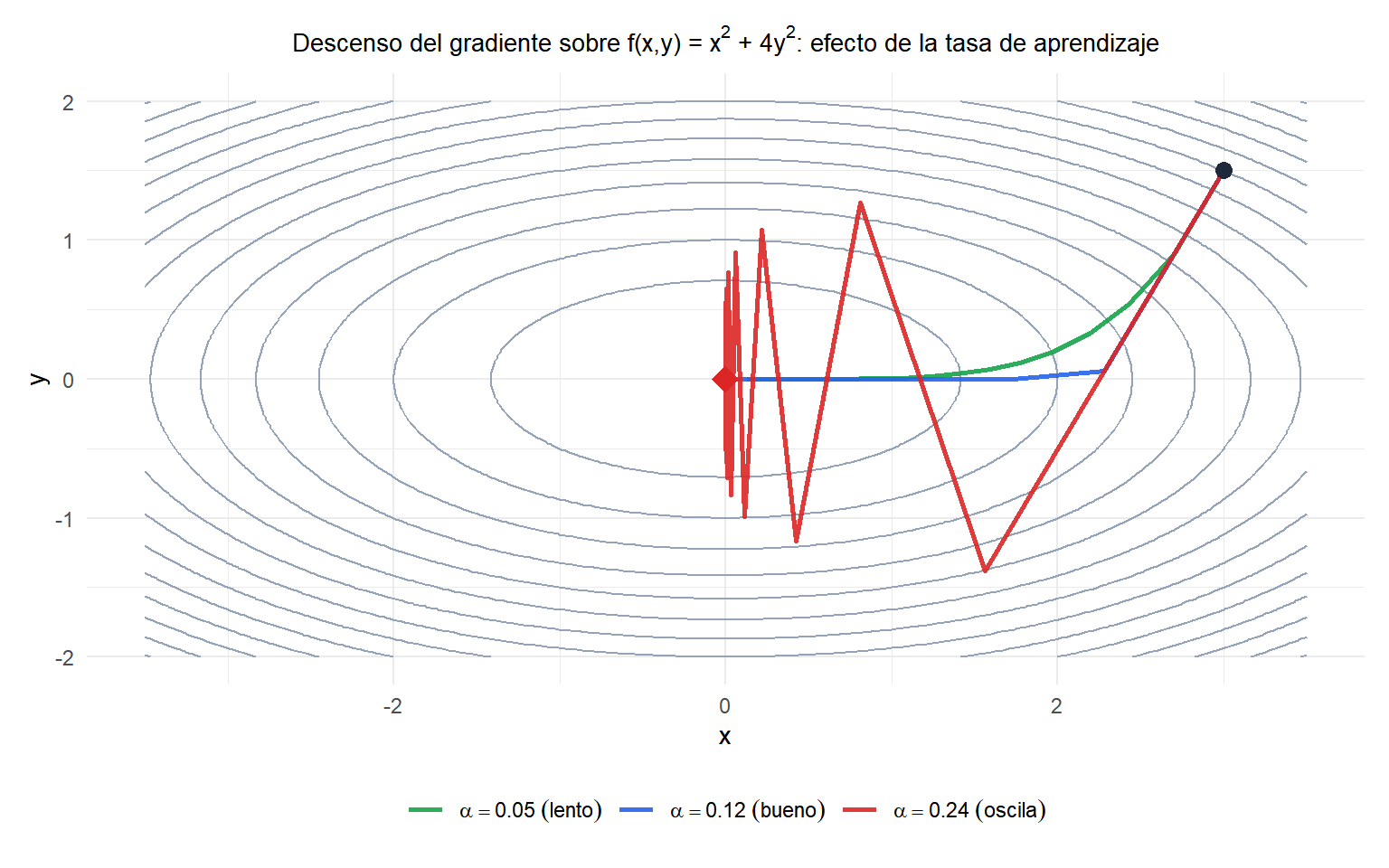
Tasa baja (verde): converge de forma segura pero lentamente. Tasa adecuada (azul): converge en pocas iteraciones. Tasa alta (rojo): oscila a lo largo del valle, ya que la forma elíptica hace que la dirección \(y\) tenga una curvatura mucho mayor y los pasos largos se pasan de largo.
La tasa de aprendizaje
La tasa de aprendizaje \(\alpha\) es el hiperparámetro más importante del descenso del gradiente. Para una función con gradiente Lipschitz-continuo (el gradiente no cambia demasiado rápido), la tasa fija óptima satisface:
\[\alpha \leq \frac{1}{L}\]
donde \(L\) es la constante de Lipschitz del gradiente: \(\|\nabla f(x) - \nabla f(y)\| \leq L\|x-y\|\) para todo \(x, y\). Para la cuadrática \(f(x) = \frac{1}{2}x^T H x\), \(L\) es igual al mayor valor propio de \(H\).
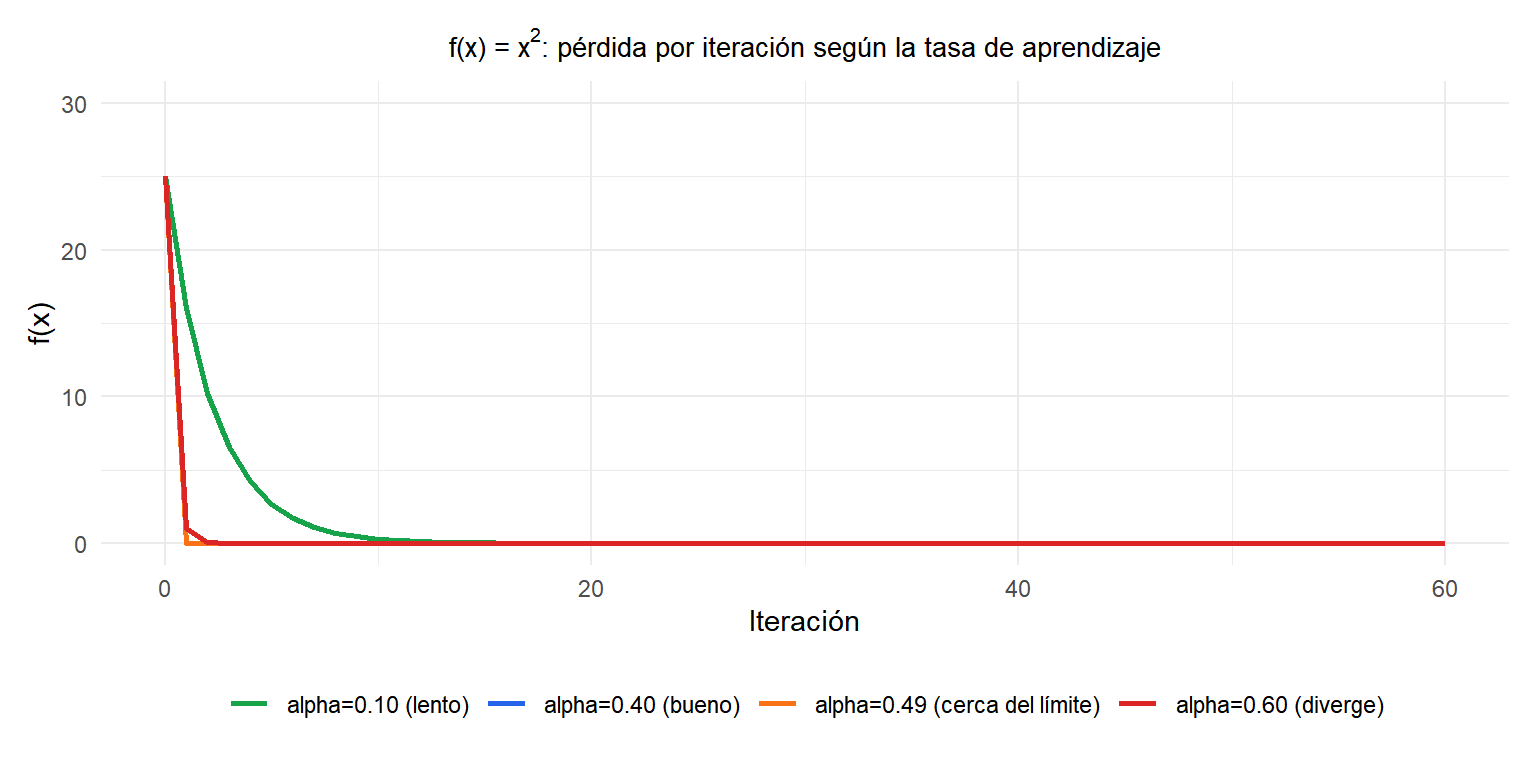
Para \(f(x)=x^2\), la constante de Lipschitz es \(L=2\) y el umbral seguro es \(\alpha \leq 0{,}5\). Con \(\alpha=0{,}49\) (naranja) la convergencia es muy lenta cerca del límite; con \(\alpha=0{,}6\) (rojo) los iterados divergen.
Teoría de la convergencia
Para una función convexa con gradiente \(L\)-Lipschitz, el descenso del gradiente con paso constante \(\alpha = 1/L\) alcanza:
\[f(x_k) - f(x^*) \leq \frac{L \|x_0 - x^*\|^2}{2k}\]
Esto es convergencia sublineal: \(O(1/k)\). Para reducir el error a la mitad hacen falta cuatro veces más iteraciones.
Para funciones fuertemente convexas (valores propios del hessiano acotados inferiormente por \(\mu > 0\)), la convergencia es lineal (geométrica):
\[f(x_k) - f(x^*) \leq \left(1 - \frac{\mu}{L}\right)^k (f(x_0) - f(x^*))\]
El cociente \(\kappa = L/\mu\) es el número de condición. Los problemas mal condicionados (\(\kappa \gg 1\), contornos alargados como la elipse anterior) convergen muy despacio. De ahí la importancia del precondicionamiento y los métodos adaptativos (Adam, RMSProp).
Batch, estocástico y mini-batch
En machine learning, \(f(\theta) = \frac{1}{n}\sum_{i=1}^n \ell(\theta; x_i, y_i)\) es una suma sobre \(n\) ejemplos de entrenamiento. Calcular el gradiente completo requiere evaluar los \(n\) términos, lo que resulta caro para conjuntos de datos grandes.
Descenso del gradiente batch
Usa el conjunto de datos completo para calcular el gradiente en cada paso. Gradiente exacto, convergencia estable, pero lento por iteración para \(n\) grande.
Descenso de gradiente estocástico (SGD)
Usa un único ejemplo \(i\) elegido al azar en cada paso:
\[x_{k+1} = x_k - \alpha \nabla \ell(\theta; x_{i_k}, y_{i_k})\]
Mucho más rápido por iteración. El gradiente es una estimación ruidosa: \(E[\nabla \ell_i] = \nabla f\). Este ruido impide la convergencia exacta, pero ayuda a escapar de mínimos locales poco profundos. Requiere una tasa de aprendizaje decreciente (\(\alpha_k \to 0\)) para garantías teóricas de convergencia.
Descenso del gradiente mini-batch
Usa un lote pequeño de \(B\) ejemplos (típicamente \(B = 32\) a \(512\)):
\[x_{k+1} = x_k - \frac{\alpha}{B} \sum_{i \in \mathcal{B}_k} \nabla \ell(\theta; x_i, y_i)\]
Es el estándar en deep learning. Equilibra la reducción de varianza del batch con la velocidad del SGD. El paralelismo en GPU hace que el cálculo por lotes sea casi gratuito para valores razonables de \(B\).
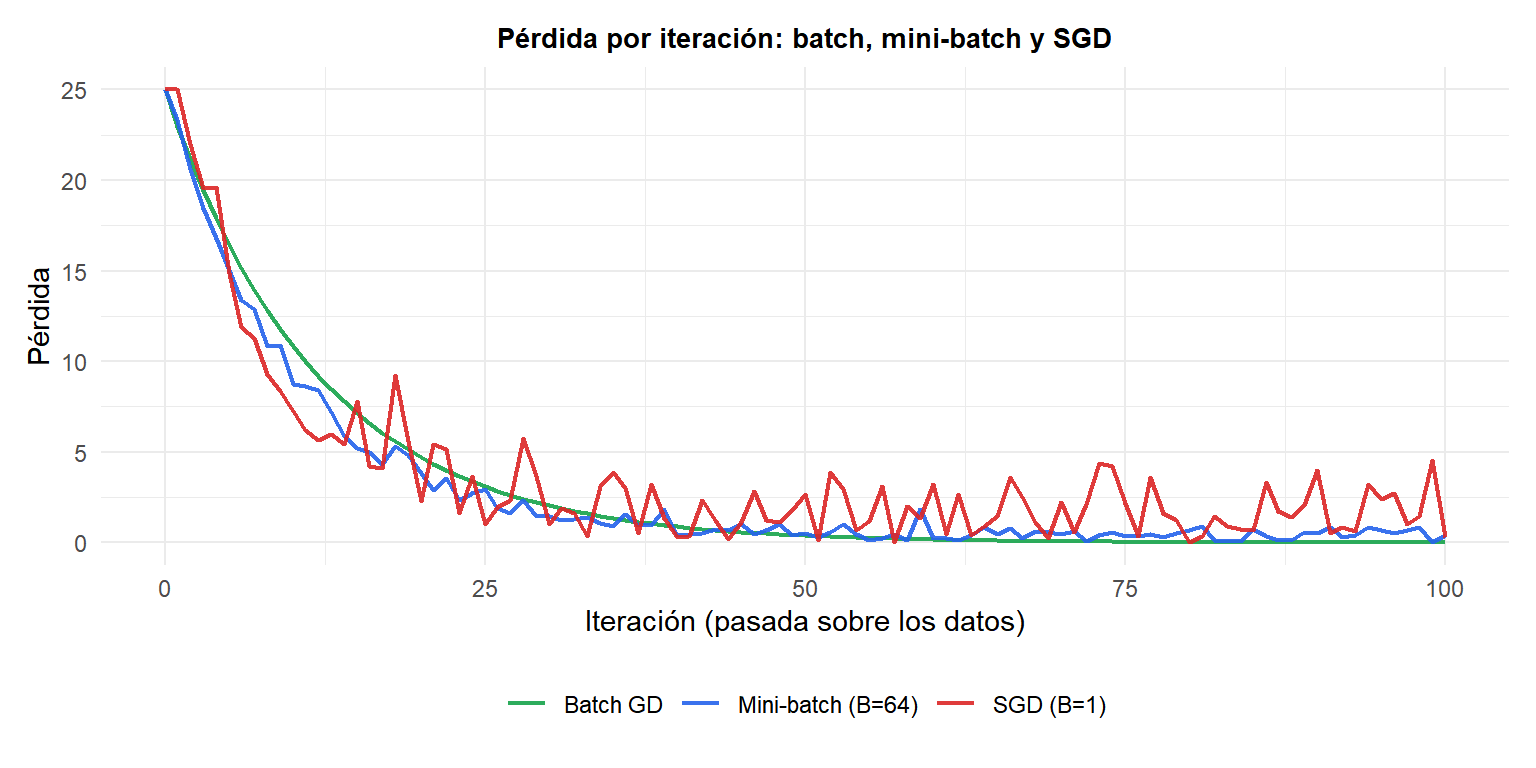
Batch GD (verde): descenso suave pero lento. SGD (rojo): descenso más rápido al principio pero con oscilaciones. Mini-batch (azul): equilibra ambos, descenso rápido con ruido moderado.
Elegir la tasa de aprendizaje: búsqueda lineal
En lugar de un \(\alpha\) fijo, la búsqueda lineal encuentra el mejor tamaño de paso en cada iteración:
\[\alpha_k = \arg\min_{\alpha > 0} f(x_k - \alpha \nabla f(x_k))\]
La búsqueda lineal exacta resuelve esta minimización de forma exacta (viable para funciones sencillas). La búsqueda lineal con retroceso es más práctica: empieza con un \(\alpha\) grande y lo reduce a la mitad hasta que se satisface la condición de Armijo:
\[f(x_k - \alpha \nabla f(x_k)) \leq f(x_k) - c \alpha \|\nabla f(x_k)\|^2\]
para alguna constante pequeña \(c \in (0,1)\) (típicamente \(c = 10^{-4}\)). Esto garantiza un descenso suficiente sin necesidad de resolver la minimización de forma exacta.
⚠️ El descenso del gradiente falla con funciones no suaves y no convexas
Tres situaciones en las que el descenso del gradiente estándar no es fiable:
Funciones no suaves: si \(f\) no es diferenciable en \(x_k\) (por ejemplo, regularización L1, ReLU), el gradiente no existe. En su lugar, usa métodos de subgradiente o algoritmos proximales.
Funciones no convexas: el descenso del gradiente converge a un punto estacionario, no necesariamente al mínimo global. En deep learning esto se acepta en la práctica (la mayoría de mínimos locales son empíricamente buenos), pero no hay garantía teórica.
Puntos de silla: en dimensiones altas, los puntos estacionarios suelen ser puntos de silla (gradiente nulo pero no mínimo). El descenso del gradiente estándar puede quedarse atrapado cerca de ellos durante un tiempo exponencialmente largo. El ruido del SGD y los métodos con momentum (Adam) ayudan a escapar más rápido.
Extensiones: momentum y métodos adaptativos
El descenso del gradiente estándar rara vez se usa en deep learning. Dos extensiones importantes:
Momentum: acumula un vector de velocidad \(v\) en la dirección de los gradientes consistentes, amortiguando las oscilaciones y acelerando la convergencia en las direcciones de baja curvatura:
\[v_{k+1} = \beta v_k + \nabla f(x_k), \qquad x_{k+1} = x_k - \alpha v_{k+1}\]
Adam (Adaptive Moment Estimation): mantiene tasas de aprendizaje por parámetro basadas en estimaciones del primer y segundo momento del gradiente. En la práctica adapta \(\alpha\) de forma individual para cada dimensión. Es el optimizador estándar en deep learning.
Gradiente acelerado de Nesterov (NAG): evalúa el gradiente en un punto “anticipado” \(x_k - \beta v_k\) en lugar de en \(x_k\), lo que da una mejor convergencia teórica para funciones convexas (\(O(1/k^2)\) frente a \(O(1/k)\)).
💡 Descenso del gradiente en R
# Descenso del gradiente manual para cualquier f diferenciable
gradient_descent <- function(f, grad_f, x0, alpha=0.01,
max_iter=1000, tol=1e-6) {
x <- x0
path <- matrix(NA, max_iter+1, length(x0))
path[1,] <- x
for (k in 1:max_iter) {
g <- grad_f(x)
x <- x - alpha * g
path[k+1,] <- x
if (sqrt(sum(g^2)) < tol) break
}
list(x=x, value=f(x), path=path[1:(k+1),])
}
# Ejemplo: minimizar f(x,y) = x^2 + 4y^2
f <- function(x) x[1]^2 + 4*x[2]^2
grad_f <- function(x) c(2*x[1], 8*x[2])
result <- gradient_descent(f, grad_f, x0=c(3,1.5), alpha=0.1)
# Para machine learning con diferenciación automática: usar torch o tensorflow
# Para optimización convexa: usar CVXR, que llama a solvers de punto interior
