Estimación de la varianza poblacional
La varianza muestral \(S^2\) es el estimador puntual estándar para la varianza poblacional \(\sigma^2\). Su característica clave es la división por \(n-1\) en lugar de \(n\), que corrige un sesgo sistemático que surge al estimar la media con los mismos datos.
El estimador: varianza muestral
Dada una muestra \(x_1, x_2, \ldots, x_n\) con media muestral \(\bar{x}\), la varianza muestral es:
\[S^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2\]
Es un estimador insesgado de \(\sigma^2\): \(E[S^2] = \sigma^2\).
El estimador alternativo, obtenido dividiendo por \(n\), es el estimador de máxima verosimilitud (MLE):
\[\hat{\sigma}^2_{\text{MLE}} = \frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})^2\]
El MLE es sesgado: \(E[\hat{\sigma}^2_{\text{MLE}}] = \frac{n-1}{n}\sigma^2 < \sigma^2\).
¿Por qué dividir por \(n-1\)?
La intuición: al calcular las desviaciones \((x_i - \bar{x})\), usamos \(\bar{x}\) en lugar de la desconocida \(\mu\). La media muestral \(\bar{x}\) está siempre en el centro de los datos, por lo que las desviaciones respecto a \(\bar{x}\) tienden a ser ligeramente menores que las desviaciones respecto a \(\mu\). Esto hace que \(\frac{1}{n}\sum(x_i-\bar{x})^2\) subestime sistemáticamente \(\sigma^2\).
De forma más formal: las \(n\) desviaciones \((x_i - \bar{x})\) deben sumar cero (porque \(\sum(x_i - \bar{x}) = 0\)), por lo que solo \(n-1\) de ellas son libres de variar. El divisor \(n-1\) refleja esta pérdida de un grado de libertad.
Supón que la población real tiene \(\sigma^2 = 10\). Se toman repetidamente muestras de tamaño \(n = 5\) y se calculan ambos estimadores.
A largo plazo (sobre muchas muestras):
\[E\!\left[\frac{1}{5}\sum(x_i-\bar{x})^2\right] = \frac{4}{5} \times 10 = 8 \quad \text{(subestima en un 20\%)}\]
\[E\!\left[\frac{1}{4}\sum(x_i-\bar{x})^2\right] = 10 \quad \text{(correcto en promedio)}\]
Para muestras pequeñas (\(n = 5\)), el sesgo del MLE es del 20%. Para \(n = 100\) es solo del 1%, por eso la distinción importa más en muestras pequeñas.
Distribución muestral de \(S^2\)
El resultado clave que conecta \(S^2\) con la distribución chi-cuadrado: si la población es normal, entonces:
\[\frac{(n-1)S^2}{\sigma^2} \sim \chi^2(n-1)\]
Este resultado tiene dos aplicaciones: confirma que \(S^2\) es insesgado (ya que \(E[\chi^2(n-1)] = n-1\), lo que da \(E[S^2] = \sigma^2\)) y es la base de los intervalos de confianza y los contrastes de hipótesis sobre \(\sigma^2\).
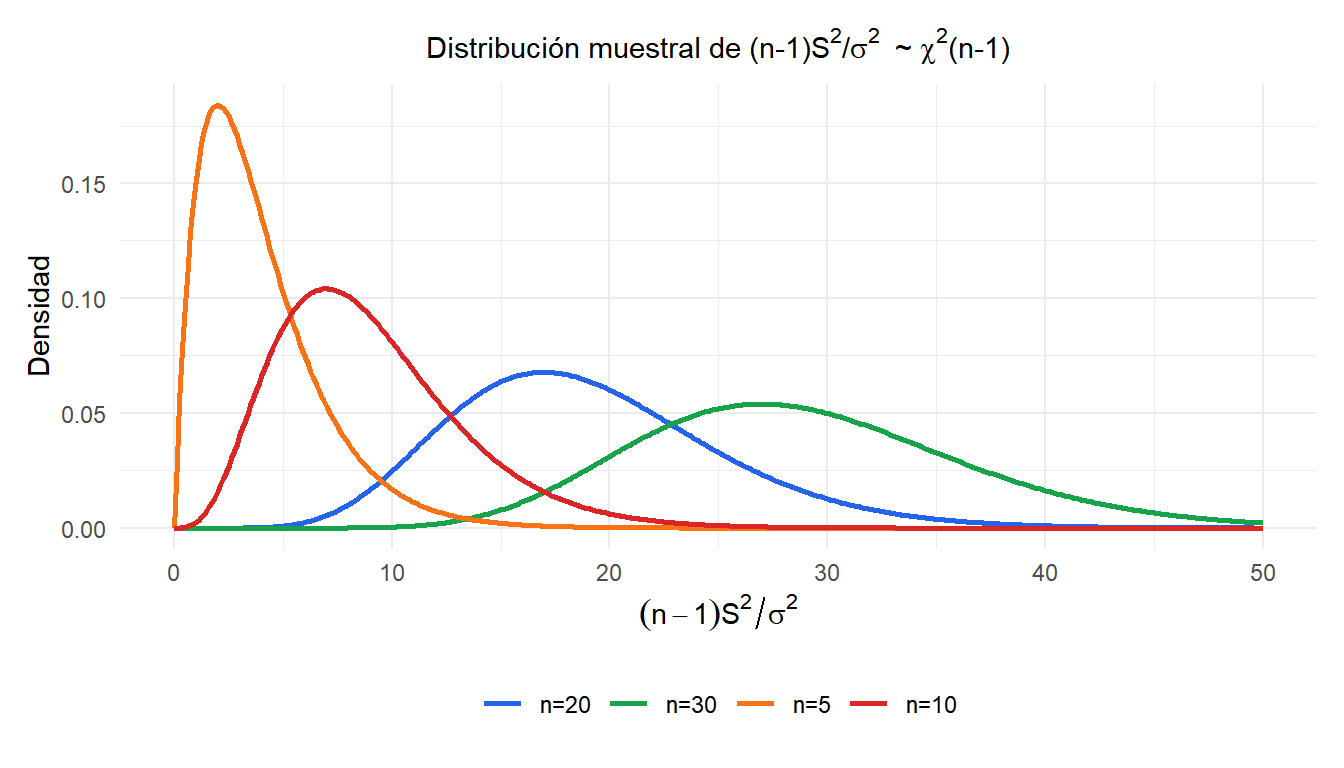
⚠️ La distribución chi-cuadrado no es simétrica
A diferencia de la distribución muestral de \(\bar{X}\), la distribución de \(S^2\) es siempre asimétrica a la derecha. Esto tiene dos consecuencias prácticas:
- Los intervalos de confianza para \(\sigma^2\) no son simétricos alrededor de \(S^2\): el límite superior está más lejos de \(S^2\) que el límite inferior.
- La asimetría es más pronunciada para \(n\) pequeño y desaparece lentamente al crecer \(n\). Para muestras pequeñas, el supuesto de normalidad de la población es importante: el resultado chi-cuadrado solo es exacto cuando la población es normal.
Comparación de los dos estimadores
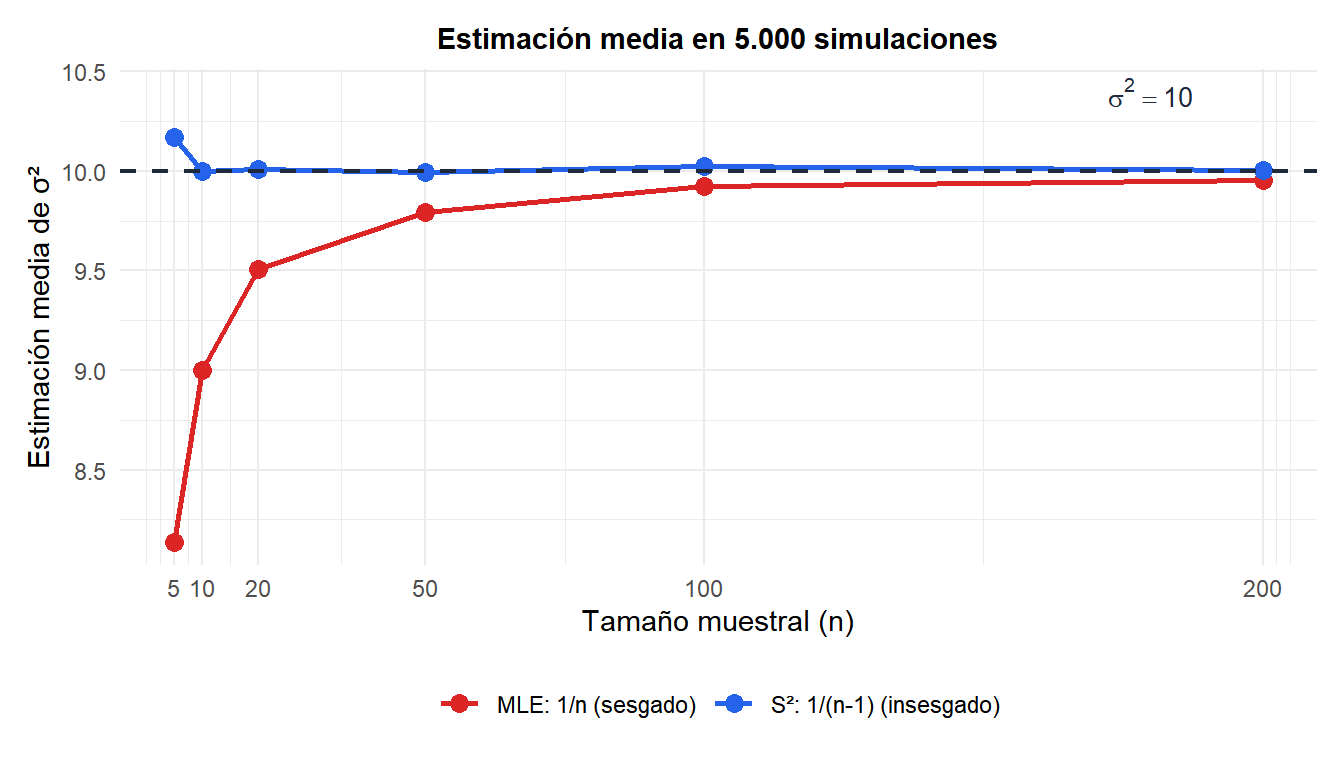
La simulación confirma: \(S^2\) (azul) se mantiene en el objetivo \(\sigma^2 = 10\) para todos los tamaños muestrales, mientras que el MLE (rojo) subestima sistemáticamente, especialmente para \(n\) pequeño.
Ejemplo paso a paso
Un ingeniero de calidad mide el diámetro (en mm) de 8 rodamientos de una producción:
\[12{,}1;\; 11{,}9;\; 12{,}3;\; 12{,}0;\; 11{,}8;\; 12{,}2;\; 12{,}1;\; 12{,}4\]
Paso 1: calcula la media muestral:
\[\bar{x} = \frac{12{,}1 + 11{,}9 + \cdots + 12{,}4}{8} = \frac{96{,}8}{8} = 12{,}1 \text{ mm}\]
Paso 2: calcula las desviaciones al cuadrado:
\[\sum(x_i - \bar{x})^2 = 0 + 0{,}04 + 0{,}04 + 0{,}01 + 0{,}09 + 0{,}01 + 0 + 0{,}09 = 0{,}28\]
Paso 3: divide por \(n - 1 = 7\):
\[S^2 = \frac{0{,}28}{7} = 0{,}04 \text{ mm}^2, \qquad S = \sqrt{0{,}04} = 0{,}2 \text{ mm}\]
La varianza poblacional estimada es \(0{,}04\) mm² y la desviación típica es \(0{,}2\) mm. El MLE daría \(0{,}28/8 = 0{,}035\) mm², subestimando en un 12,5%.
💡 Varianza muestral vs desviación típica muestral
\(S^2\) es insesgada para \(\sigma^2\), pero \(S = \sqrt{S^2}\) no es insesgada para \(\sigma\). La raíz cuadrada de un estimador insesgado no es en sí misma insesgada (desigualdad de Jensen para funciones cóncavas). En la práctica este sesgo es pequeño y \(S\) sigue siendo el estimador estándar para \(\sigma\), aunque técnicamente existe un factor de corrección para poblaciones normales.

