Estimación de la media poblacional
La media muestral \(\bar{X}\) es el estimador puntual estándar para la media poblacional \(\mu\). Comprender sus propiedades, su distribución muestral y su error estándar es la base de cualquier inferencia sobre medias.
El estimador: media muestral
Dada una muestra aleatoria \(x_1, x_2, \ldots, x_n\) de una población con media \(\mu\) y varianza \(\sigma^2\), el estimador natural para \(\mu\) es la media muestral:
\[\bar{X} = \frac{1}{n} \sum_{i=1}^{n} X_i\]
La media muestral tiene tres propiedades clave que la convierten en la elección estándar:
- Insesgada: \(E[\bar{X}] = \mu\). En promedio sobre todas las muestras posibles, \(\bar{X}\) da en el blanco.
- Consistente: a medida que \(n\) aumenta, \(\bar{X}\) converge a \(\mu\).
- Eficiente: entre todos los estimadores insesgados, \(\bar{X}\) tiene la menor varianza cuando la población es normal (alcanza la cota de Cramér-Rao).
Distribución muestral de la media
Antes de recoger datos, \(\bar{X}\) es una variable aleatoria. Su distribución sobre todas las muestras posibles de tamaño \(n\) es la distribución muestral de la media:
\[\bar{X} \sim N\!\left(\mu,\ \frac{\sigma}{\sqrt{n}}\right) \quad \text{exactamente, si la población es normal}\]
Por el Teorema Central del Límite (TCL), esta aproximación se cumple para cualquier población con varianza finita cuando \(n\) es suficientemente grande (se suele usar \(n \geq 30\) como regla práctica, aunque el \(n\) necesario depende de la forma de la población).
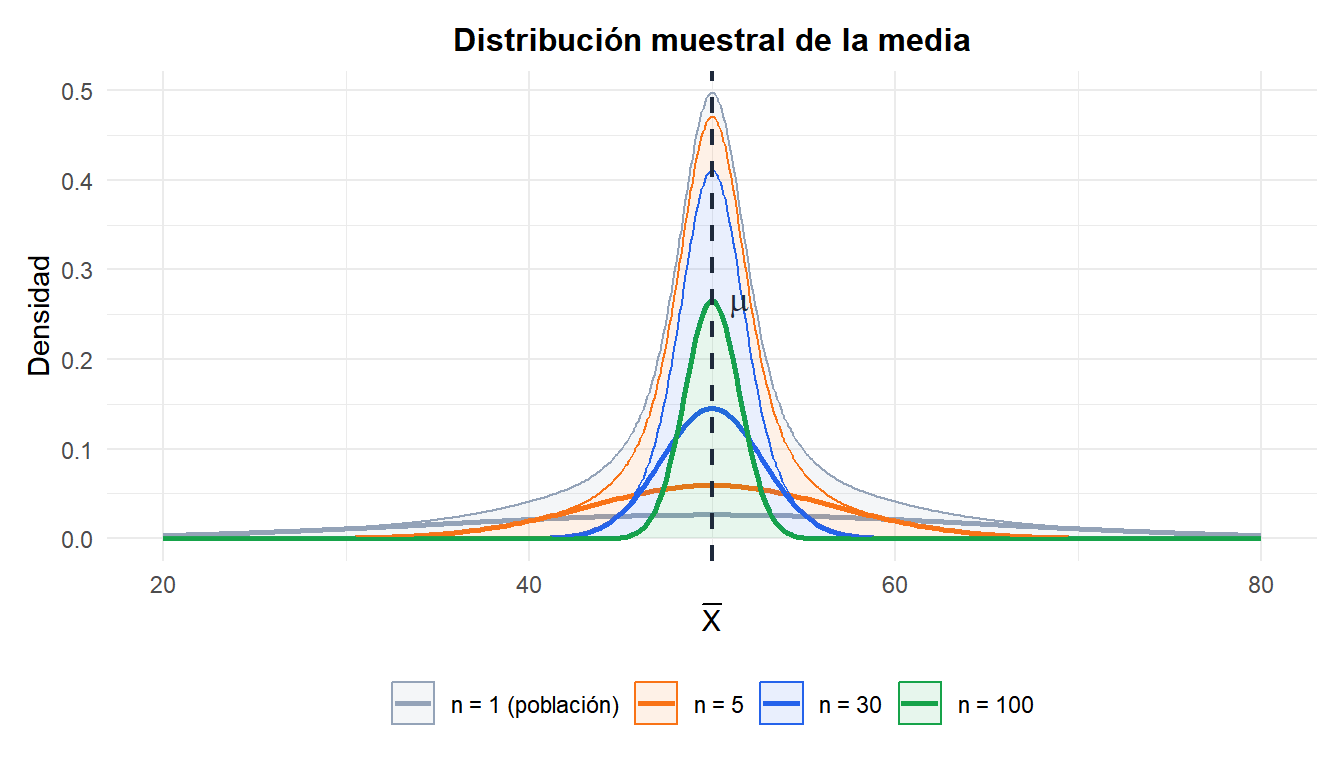
Figure 1: A medida que n aumenta, la distribución muestral de la media se estrecha y se vuelve más simétrica, independientemente de la distribución de la población
Error estándar de la media
La dispersión de la distribución muestral se mide con el error estándar (EE):
\[\text{EE}(\bar{X}) = \frac{\sigma}{\sqrt{n}}\]
El EE indica cuánto se espera que varíe \(\bar{X}\) de una muestra a otra. Disminuye al aumentar \(n\): duplicar el tamaño muestral reduce el error estándar a la mitad (se necesitan cuatro veces más datos para reducirlo a la mitad).
En la práctica \(\sigma\) es desconocida y se estima con la desviación típica muestral \(S\):
\[\widehat{\text{EE}}(\bar{X}) = \frac{S}{\sqrt{n}}\]
⚠️ El error estándar no es lo mismo que la desviación típica
- Desviación típica (\(S\)): mide la dispersión de las observaciones individuales alrededor de la media muestral. Describe la variabilidad de los datos.
- Error estándar (\(\widehat{\text{EE}}\)): mide la dispersión de la media muestral entre distintas muestras. Describe la precisión de la estimación.
Un conjunto de datos grande puede tener una \(S\) grande (los datos están muy dispersos) y un \(\widehat{\text{EE}}\) muy pequeño (la media se estima con precisión). Responden a preguntas distintas.
Ejemplo paso a paso
Un hospital registra la estancia hospitalaria (en días) de una muestra aleatoria de 40 pacientes ingresados con un diagnóstico concreto. Los resultados son: \(\bar{x} = 6{,}4\) días, \(S = 3{,}1\) días.
Estimación puntual de la media poblacional:
\[\hat{\mu} = \bar{x} = 6{,}4 \text{ días}\]
Error estándar estimado:
\[\widehat{\text{EE}} = \frac{S}{\sqrt{n}} = \frac{3{,}1}{\sqrt{40}} = \frac{3{,}1}{6{,}32} \approx 0{,}49 \text{ días}\]
Interpretación: la mejor estimación puntual de la estancia media para todos los pacientes con este diagnóstico es 6,4 días. El error estándar de 0,49 días indica que si se repitiese el estudio muchas veces, la media muestral caería típicamente a menos de 0,49 días del valor real.
Misma población (\(\mu = 6{,}4\), \(S = 3{,}1\)), distintos tamaños muestrales:
| \(n\) | \(\widehat{\text{EE}} = S/\sqrt{n}\) | Interpretación |
|---|---|---|
| 10 | \(3{,}1/\sqrt{10} \approx 0{,}98\) | Media conocida con una precisión de ~1 día |
| 40 | \(3{,}1/\sqrt{40} \approx 0{,}49\) | Media conocida con una precisión de ~0,5 días |
| 160 | \(3{,}1/\sqrt{160} \approx 0{,}25\) | Media conocida con una precisión de ~0,25 días |
| 640 | \(3{,}1/\sqrt{640} \approx 0{,}12\) | Media conocida con una precisión de ~0,12 días |
Cada vez que se multiplica \(n\) por cuatro, el error estándar se reduce a la mitad. La precisión mejora con más datos, pero con rendimientos decrecientes.
Por qué funciona la media muestral: el TCL
El Teorema Central del Límite garantiza que \(\bar{X}\) sigue aproximadamente una distribución normal para \(n\) grande, independientemente de la forma de la población. Esto es lo que hace que la media muestral sea universalmente útil:
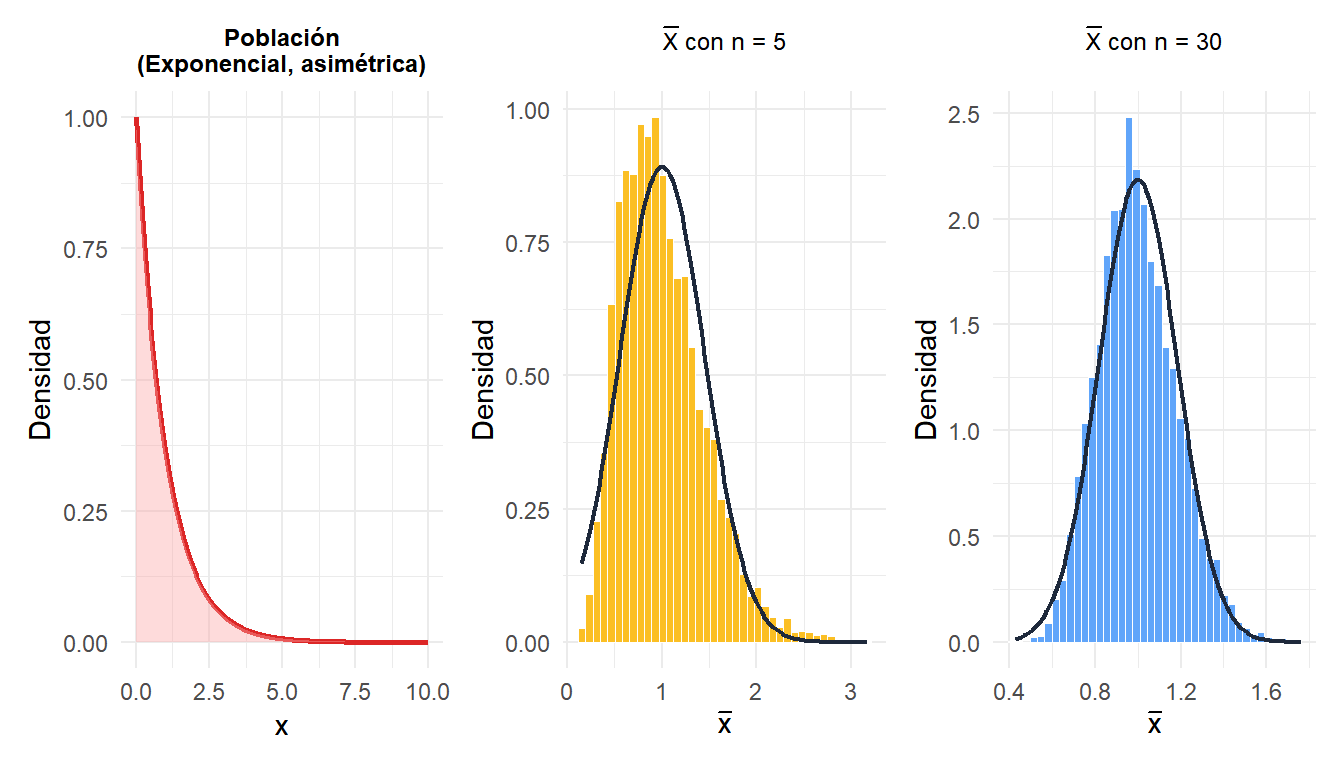
Figure 2: Las medias de muestras de una población exponencial fuertemente sesgada convergen a la normalidad a medida que n aumenta
Incluso partiendo de una distribución exponencial fuertemente sesgada, la distribución muestral de \(\bar{X}\) ya es aproximadamente normal para \(n = 30\).
💡 Cuándo usar z vs t para la inferencia sobre la media
La elección depende de lo que se conozca:
- \(\sigma\) conocida: usa la normal estándar \(Z = (\bar{X} - \mu)/(\sigma/\sqrt{n})\). Raro en la práctica.
- \(\sigma\) desconocida, \(n\) grande: la distribución \(t\) con \(n-1\) grados de libertad. Para \(n \geq 30\) es prácticamente indistinguible de la normal.
- \(\sigma\) desconocida, \(n\) pequeño: la distribución \(t\) es imprescindible. Tiene colas más pesadas para dar cuenta de la incertidumbre adicional al estimar \(\sigma\).
En la práctica: usa siempre \(t\) cuando \(\sigma\) sea desconocida. Para \(n\) grande, \(t\) y \(z\) dan el mismo resultado.

