Distribución t de Student
La distribución t de Student es la que se usa cuando se quiere hacer inferencia sobre la media poblacional pero no se conoce la varianza poblacional. Tiene colas más pesadas que la normal y converge a ella a medida que crece el tamaño muestral, lo que la convierte en la herramienta estándar para los t-tests e intervalos de confianza.
Definición
Si \(Z \sim N(0,1)\) y \(V \sim \chi^2(\nu)\) son independientes, entonces:
\[T = \frac{Z}{\sqrt{V/\nu}} \sim t(\nu)\]
\(T\) sigue una distribución t de Student con \(\nu\) grados de libertad. Su PDF es:
\[f(x) = \frac{\Gamma\!\left(\frac{\nu+1}{2}\right)}{\sqrt{\nu\pi}\;\Gamma\!\left(\frac{\nu}{2}\right)} \left(1 + \frac{x^2}{\nu}\right)^{-(\nu+1)/2}, \quad -\infty < x < \infty\]
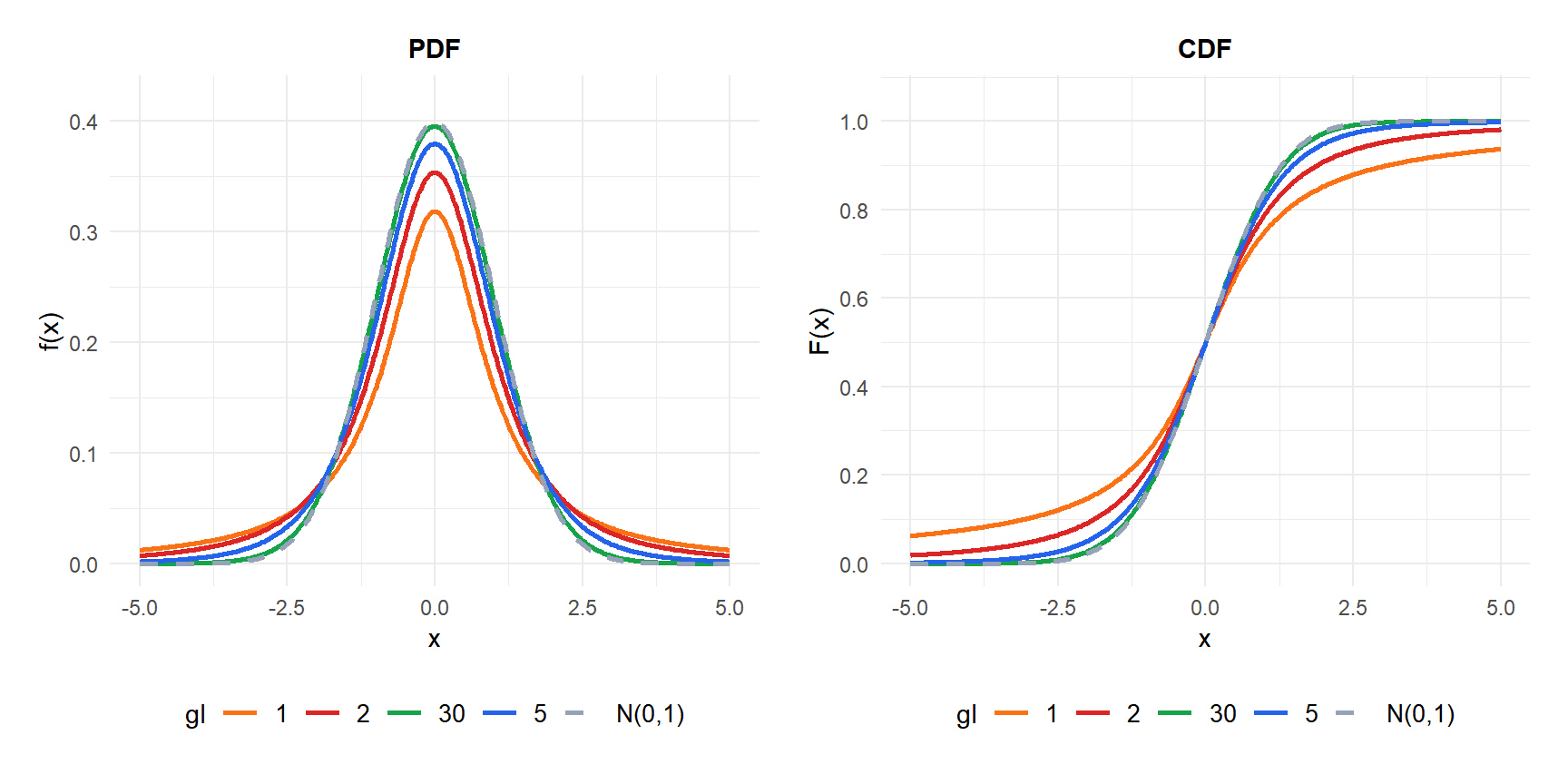
La distribución es simétrica alrededor de cero y tiene forma de campana como la normal, pero con colas más pesadas. Cuando \(\nu \to \infty\), \(t(\nu) \to N(0,1)\).
⚠️ ¿Quién es Student?
“Student” fue el seudónimo de William Sealy Gosset, estadístico que trabajaba en la cervecería Guinness de Dublín a principios del siglo XX. Guinness no permitía a sus empleados publicar investigaciones, así que Gosset publicó bajo el nombre “Student” en 1908. Desarrolló la distribución para trabajar con muestras pequeñas de cebada y lúpulo, uno de los orígenes más prácticos de un resultado estadístico fundamental.
Efecto de los grados de libertad
Los grados de libertad \(\nu\) controlan el peso de las colas:
- \(\nu\) pequeño: colas muy pesadas. Los valores extremos son mucho más probables que bajo la normal. Con \(\nu = 1\), la distribución es una Cauchy, que no tiene media.
- \(\nu \geq 30\): prácticamente indistinguible de \(N(0,1)\) para la mayoría de los propósitos.
- \(\nu \to \infty\): converge exactamente a \(N(0,1)\).
Propiedades
Para \(T \sim t(\nu)\):
- Valor esperado (media)
\[E(T) = 0, \quad \text{para } \nu > 1\]
No definida para \(\nu = 1\) (distribución de Cauchy).
- Varianza
\[\text{Var}(T) = \frac{\nu}{\nu - 2}, \quad \text{para } \nu > 2\]
No definida para \(\nu \leq 2\). Siempre mayor que 1, y se aproxima a 1 cuando \(\nu \to \infty\).
- Asimetría
Siempre 0: la distribución es perfectamente simétrica alrededor de 0, para \(\nu > 3\).
- Curtosis
\[g_2 = \frac{6}{\nu - 4}, \quad \text{para } \nu > 4\]
Siempre positiva (leptocúrtica). Se aproxima a 0 cuando \(\nu \to \infty\).
- Moda y mediana
Ambas iguales a 0 por simetría.
- Función cuantil
No existe forma cerrada; los valores se leen de tablas t o se calculan con software. Valores clave de \(t_{0{,}975,\, \nu}\) (IC bilateral al 95%):
| \(\nu\) | \(t_{0{,}975}\) |
|---|---|
| 5 | 2,571 |
| 10 | 2,228 |
| 20 | 2,086 |
| 30 | 2,042 |
| \(\infty\) | 1,960 |
A medida que \(\nu\) crece, el valor crítico se aproxima a 1,960, el cuantil de la normal estándar.
¿Por qué usar t en lugar de z?
Al contrastar una hipótesis sobre la media poblacional \(\mu\), el estadístico natural es:
\[Z = \frac{\bar{X} - \mu}{\sigma / \sqrt{n}}\]
Esto sigue exactamente \(N(0,1)\). El problema es que \(\sigma\) casi nunca se conoce. Sustituirla por la desviación típica muestral \(S\) da:
\[T = \frac{\bar{X} - \mu}{S / \sqrt{n}} \sim t(n-1)\]
Este estadístico sigue una distribución t porque \(S\) introduce variabilidad adicional. La distribución t tiene colas más pesadas que la normal para dar cuenta de la incertidumbre extra que introduce estimar \(\sigma\).
⚠️ ¿Cuándo se puede usar z en lugar de t?
En la práctica, muchos libros de texto dicen “usa z cuando \(n \geq 30\) y \(\sigma\) es conocida, usa t en caso contrario”. La regla real es más simple: usa siempre t cuando \(\sigma\) sea desconocida, independientemente del tamaño muestral. Para \(n\) grande, t y z dan resultados casi idénticos, así que usar t nunca es incorrecto.
El único caso en que z es estrictamente correcto y t es una aproximación es cuando \(\sigma\) es verdaderamente conocida, lo cual es raro fuera de experimentos controlados.
Aplicaciones
Contraste t de una muestra e intervalo de confianza
Para contrastar \(H_0: \mu = \mu_0\) o construir un IC para \(\mu\):
\[T = \frac{\bar{X} - \mu_0}{S/\sqrt{n}} \sim t(n-1)\]
Intervalo de confianza al \((1-\alpha)\) para \(\mu\):
\[\bar{X} \pm t_{\alpha/2,\, n-1} \cdot \frac{S}{\sqrt{n}}\]
Una empresa alimentaria afirma que sus envases pesan 500 g de media. Un auditor de calidad pesa 12 envases y obtiene \(\bar{X} = 494\) g y \(S = 8\) g.
Contrasta \(H_0: \mu = 500\) frente a \(H_1: \mu \neq 500\) con \(\alpha = 0{,}05\).
\[T = \frac{494 - 500}{8/\sqrt{12}} = \frac{-6}{2{,}309} \approx -2{,}60\]
Valor crítico: \(t_{0{,}025,\, 11} \approx 2{,}201\).
Como \(|{-2{,}60}| > 2{,}201\), rechazamos \(H_0\). Hay evidencia significativa de que los envases pesan menos de lo declarado.
IC al 95%: \(494 \pm 2{,}201 \times 2{,}309 = 494 \pm 5{,}08 = (488{,}9;\, 499{,}1)\) g.
Contraste t de dos muestras
Para comparar las medias de dos grupos independientes con varianzas iguales:
\[T = \frac{\bar{X}_1 - \bar{X}_2}{S_p\sqrt{1/n_1 + 1/n_2}} \sim t(n_1 + n_2 - 2)\]
donde \(S_p^2 = \frac{(n_1-1)S_1^2 + (n_2-1)S_2^2}{n_1+n_2-2}\) es la varianza combinada.
Para varianzas desiguales, el test de Welch usa unos grados de libertad modificados (aproximación de Satterthwaite).
⚠️ Comprueba siempre el supuesto de igualdad de varianzas
El contraste t de dos muestras combinado asume varianzas iguales. Si las varianzas difieren sustancialmente, usa el test de Welch: no asume igualdad de varianzas y se recomienda como opción por defecto. En R, t.test() usa Welch por defecto; añade var.equal = TRUE para la versión combinada.
Contraste t de datos pareados
Cuando las observaciones vienen en pares (antes/después, sujetos emparejados), calcula las diferencias \(D_i = X_{i1} - X_{i2}\) y aplica el contraste t de una muestra a \(D_i\).
Ocho empleados realizan un test de velocidad de escritura antes y después de un programa de formación. Las diferencias (después menos antes, en palabras por minuto) son:
\[d = (5, 8, -2, 12, 6, 3, 9, 4)\]
\(\bar{d} = 5{,}625\), \(S_d \approx 4{,}24\), \(n = 8\).
\[T = \frac{5{,}625}{4{,}24/\sqrt{8}} = \frac{5{,}625}{1{,}499} \approx 3{,}75\]
Valor crítico: \(t_{0{,}025,\, 7} \approx 2{,}365\).
Como \(3{,}75 > 2{,}365\), rechazamos \(H_0\): la formación mejoró significativamente la velocidad de escritura (\(p \approx 0{,}007\)).
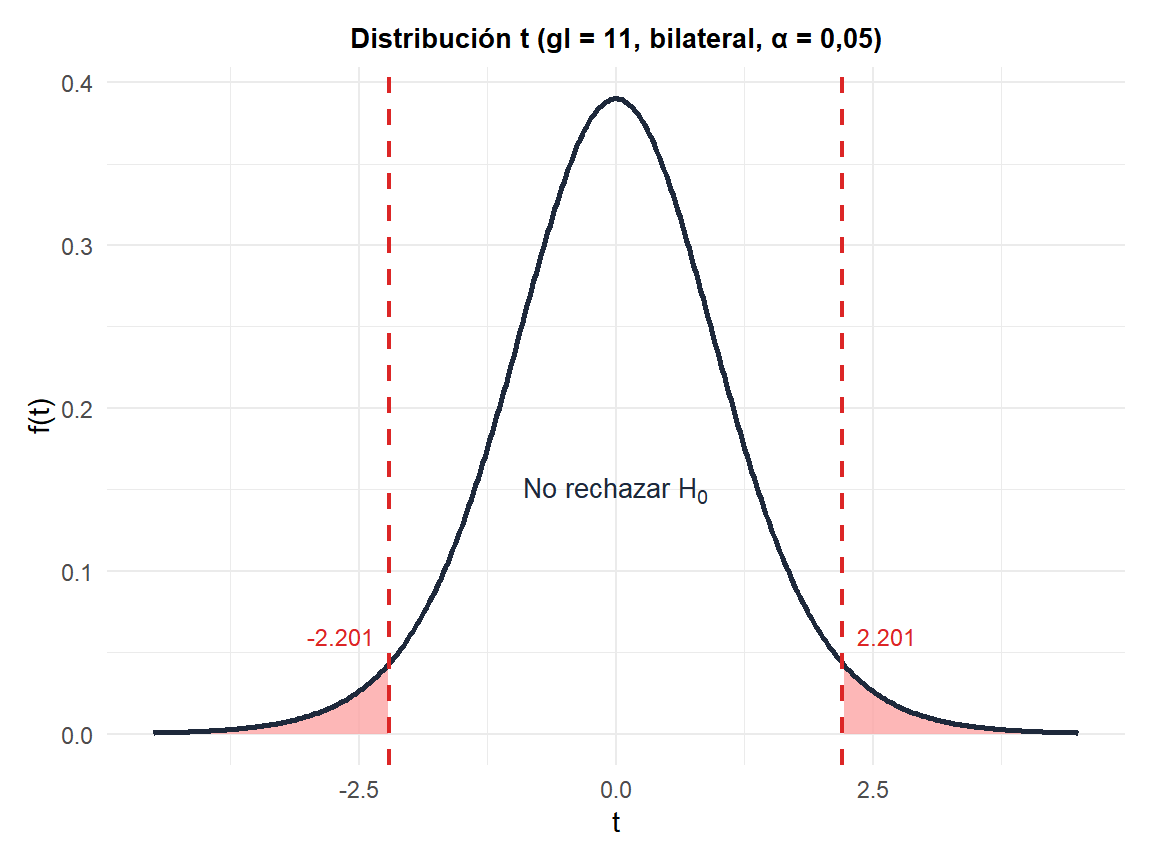
Figure 1: Contraste t bilateral con 11 grados de libertad a α=0,05: regiones de rechazo en rojo
💡 Relación con otras distribuciones
- Normal: \(t(\infty) = N(0,1)\). Cuando \(\nu \to \infty\), la t converge a la normal estándar.
- Cauchy: \(t(1) = \text{Cauchy}(0,1)\). Sin media, sin varianza.
- Chi-cuadrado: \(T^2 \sim F(1, \nu)\), donde \(F\) es la distribución F. Elevar al cuadrado un estadístico t da un estadístico F.
- Distribución F: \(t(\nu)^2 = F(1, \nu)\).
- Beta: \(T^2/(\nu + T^2) \sim \text{Beta}(1/2,\, \nu/2)\).

