Distribución normal
La distribución normal es la distribución continua más importante en estadística. Describe una enorme variedad de fenómenos naturales y es la distribución límite de sumas y medias de variables aleatorias independientes, razón por la que aparece en todas partes.
Definición
Una variable aleatoria \(X\) sigue una distribución normal con media \(\mu \in \mathbb{R}\) y desviación típica \(\sigma > 0\), escrita \(X \sim N(\mu, \sigma)\), si su función de densidad de probabilidad es:
\[f(x) = \frac{1}{\sigma\sqrt{2\pi}}\, e^{-\frac{(x-\mu)^2}{2\sigma^2}}, \quad -\infty < x < \infty\]
La curva tiene forma de campana, es simétrica alrededor de \(\mu\) y su dispersión está controlada por \(\sigma\). El área total bajo la curva es siempre 1.
⚠️ Notación: N(μ, σ) frente a N(μ, σ²)
Distintos libros de texto usan convenciones diferentes:
- \(N(\mu, \sigma)\): parametrizada por la media y la desviación típica. Habitual en muchos libros europeos y en español.
- \(N(\mu, \sigma^2)\): parametrizada por la media y la varianza. Habitual en libros anglosajones y en la documentación de la mayoría del software.
Comprueba siempre qué convención usa tu asignatura antes de sustituir números en las fórmulas. Una distribución normal con media 0 y desviación típica 2 es \(N(0, 2)\) en una convención y \(N(0, 4)\) en la otra.
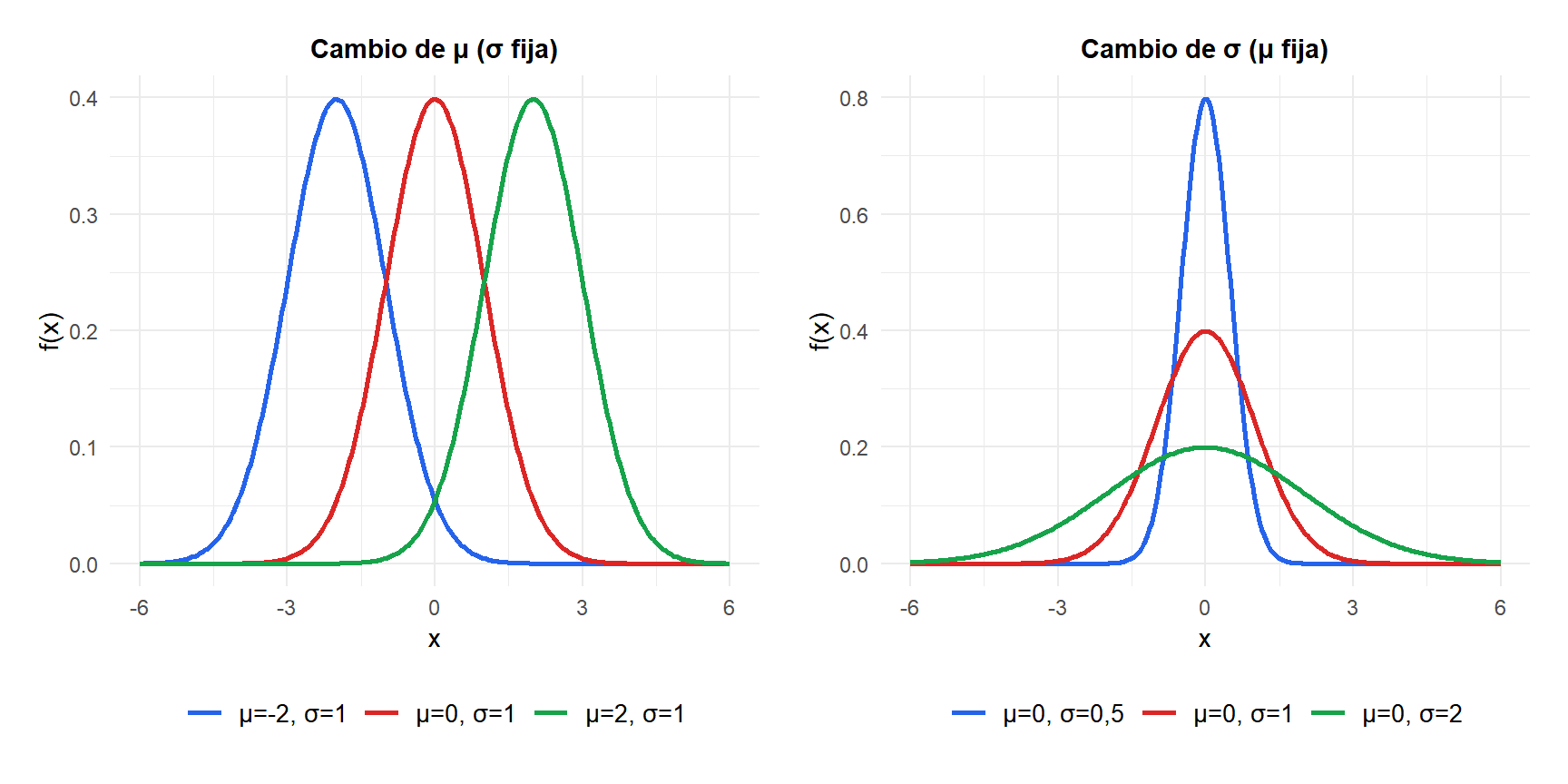
Figure 1: Efecto de cambiar μ (izquierda) y σ (derecha) sobre la forma de la distribución normal
Propiedades
Para \(X \sim N(\mu, \sigma)\):
- Valor esperado (media)
\[E(X) = \mu\]
- Varianza
\[\text{Var}(X) = \sigma^2\]
- Asimetría
Siempre 0. La distribución normal es perfectamente simétrica alrededor de \(\mu\).
- Curtosis
\[g_2 = 0 \quad \text{(curtosis en exceso)}\]
La distribución normal es la referencia para la curtosis: mesocúrtica por definición. La curtosis simple es 3; la curtosis en exceso resta 3 para dar 0.
- Moda y mediana
\[\text{Moda} = \text{Mediana} = \mu\]
Las tres medidas de tendencia central coinciden, consecuencia de la simetría perfecta.
- CDF
\[F(x) = \Phi\left(\frac{x-\mu}{\sigma}\right) = \frac{1}{2}\left[1 + \text{erf}\left(\frac{x-\mu}{\sigma\sqrt{2}}\right)\right]\]
donde \(\Phi\) es la CDF de la normal estándar. No existe una primitiva en forma cerrada: las probabilidades se calculan numéricamente o mediante tablas.
- Función cuantil
\[Q(p) = \mu + \sigma\,\Phi^{-1}(p)\]
El percentil 95 de \(N(0,1)\) es \(\Phi^{-1}(0{,}95) \approx 1{,}645\).
La regla 68-95-99,7
El resultado más práctico sobre la distribución normal es la regla empírica: casi toda la probabilidad se concentra dentro de pocas desviaciones típicas de la media.
\[P(\mu - \sigma \leq X \leq \mu + \sigma) \approx 0{,}6827\] \[P(\mu - 2\sigma \leq X \leq \mu + 2\sigma) \approx 0{,}9545\] \[P(\mu - 3\sigma \leq X \leq \mu + 3\sigma) \approx 0{,}9973\]
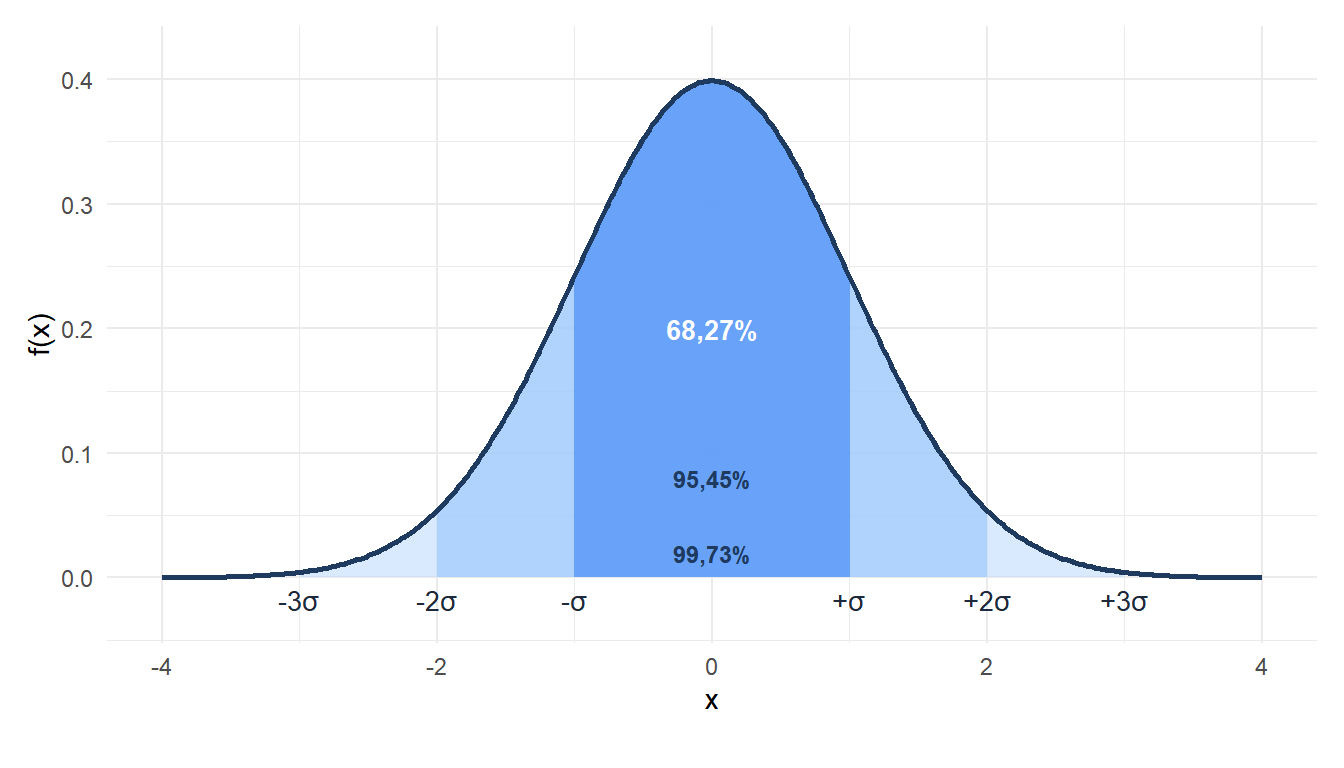
Figure 2: La regla 68-95-99,7: probabilidad dentro de 1, 2 y 3 desviaciones típicas de la media
La estatura de hombres adultos en un país sigue \(N(175, 7)\) cm (media 175 cm, desviación típica 7 cm).
- Aproximadamente el 68% de los hombres mide entre \(175 - 7 = 168\) y \(175 + 7 = 182\) cm.
- Aproximadamente el 95% mide entre \(175 - 14 = 161\) y \(175 + 14 = 189\) cm.
- Solo alrededor del 0,3% mide por debajo de 154 cm o por encima de 196 cm (más de 3 desviaciones típicas de la media).
Distribución normal estándar
La distribución normal estándar \(Z \sim N(0, 1)\) tiene media 0 y desviación típica 1. Su PDF es:
\[f(z) = \frac{1}{\sqrt{2\pi}}\,e^{-z^2/2}, \quad -\infty < z < \infty\]
Su CDF se denota \(\Phi(z) = P(Z \leq z)\) y está tabulada en las tablas de la normal estándar.
Cualquier variable normal puede tipificarse:
\[Z = \frac{X - \mu}{\sigma}\]
Esto convierte \(X \sim N(\mu, \sigma)\) en \(Z \sim N(0,1)\), permitiendo usar una única tabla para todas las distribuciones normales.
Propiedades de simetría útiles de \(\Phi\):
- \(\Phi(-z) = 1 - \Phi(z)\)
- \(P(Z > z) = 1 - \Phi(z)\)
- \(P(a \leq Z \leq b) = \Phi(b) - \Phi(a)\)
Ejemplo paso a paso
Las puntuaciones en un examen estandarizado siguen \(X \sim N(70, 10)\) (media 70, desviación típica 10).
Probabilidad de obtener más de 85 puntos:
Tipificamos: \(z = (85 - 70)/10 = 1{,}5\)
\[P(X > 85) = P(Z > 1{,}5) = 1 - \Phi(1{,}5) \approx 1 - 0{,}9332 = 0{,}0668\]
Aproximadamente el 6,7% de los estudiantes supera los 85 puntos.
Probabilidad de obtener entre 60 y 80 puntos:
\[P(60 \leq X \leq 80) = \Phi\left(\frac{80-70}{10}\right) - \Phi\left(\frac{60-70}{10}\right) = \Phi(1) - \Phi(-1) \approx 0{,}8413 - 0{,}1587 = 0{,}6827\]
Es exactamente el 68,27% de la regla empírica: el intervalo \([\mu - \sigma, \mu + \sigma]\).
Puntuación en el percentil 90:
\[Q(0{,}90) = 70 + 10 \times \Phi^{-1}(0{,}90) \approx 70 + 10 \times 1{,}282 = 82{,}82\]
Un estudiante necesita obtener alrededor de 82,8 puntos para estar en el 10% superior.
Por qué la distribución normal está en todas partes
El Teorema Central del Límite (TCL) establece que la suma (o media) de un gran número de variables aleatorias independientes, con independencia de sus distribuciones individuales, tiende hacia una distribución normal. Esta es la razón matemática por la que la distribución normal aparece en tantos fenómenos naturales y sociales:
- La estatura y el peso resultan de la suma de muchos factores genéticos y ambientales pequeños.
- Los errores de medición en física son sumas de muchas fuentes de error pequeñas e independientes.
- Las medias muestrales en inferencia estadística son aproximadamente normales para muestras grandes, con independencia de la distribución de la población.
💡 Relación con otras distribuciones
- Normal estándar: \(N(0, 1)\) es la referencia. Todas las demás distribuciones normales son desplazamientos y reescalamientos de ella.
- Chi-cuadrado: la suma de cuadrados de \(k\) variables \(N(0,1)\) independientes sigue una \(\chi^2(k)\).
- t de Student: el cociente entre una variable \(N(0,1)\) y la raíz cuadrada de una \(\chi^2(k)/k\).
- Lognormal: si \(\ln(X) \sim N(\mu, \sigma)\), entonces \(X\) sigue una distribución lognormal. Se usa para precios de activos y mediciones biológicas que no pueden ser negativas.
- Aproximación binomial: \(\text{Binomial}(n,p) \approx N(np,\, \sqrt{np(1-p)})\) para \(n\) grande.

