Regresión Ridge
La regresión Ridge añade una penalización sobre la norma \(L_2\) de los coeficientes a la función de pérdida MCO. Los coeficientes se encogen hacia cero pero nunca llegan exactamente a cero. Ridge es especialmente eficaz cuando los predictores están correlacionados (multicolinealidad) o cuando el número de predictores es comparable al número de observaciones.
El estimador Ridge
\[\hat{\boldsymbol{\beta}}^{\text{Ridge}} = \arg\min_{\boldsymbol{\beta}} \left\{\|\mathbf{y} - \mathbf{X}\boldsymbol{\beta}\|^2 + \lambda\|\boldsymbol{\beta}\|^2\right\}\]
Derivando e igualando a cero se obtiene la solución en forma cerrada:
\[\hat{\boldsymbol{\beta}}^{\text{Ridge}} = (\mathbf{X}^T\mathbf{X} + \lambda\mathbf{I})^{-1}\mathbf{X}^T\mathbf{y}\]
Comparado con el MCO ordinario \(\hat{\boldsymbol{\beta}} = (\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y}\): Ridge añade \(\lambda\mathbf{I}\) a \(\mathbf{X}^T\mathbf{X}\) antes de invertir. Esto hace la matriz invertible incluso cuando \(\mathbf{X}^T\mathbf{X}\) es casi singular (multicolinealidad) o singular (\(p > n\)).
Interpretación por SVD
La descomposición en valores singulares de \(\mathbf{X} = \mathbf{U}\mathbf{D}\mathbf{V}^T\) revela qué hace Ridge exactamente. Los valores ajustados Ridge son:
\[\hat{\mathbf{y}}^{\text{Ridge}} = \mathbf{X}\hat{\boldsymbol{\beta}}^{\text{Ridge}} = \sum_{j=1}^p \mathbf{u}_j \frac{d_j^2}{d_j^2 + \lambda} \mathbf{u}_j^T\mathbf{y}\]
El factor \(d_j^2/(d_j^2 + \lambda)\) es el factor de encogimiento de cada componente de la SVD:
- Para direcciones con \(d_j^2 \gg \lambda\): el factor se aproxima a 1 (poco encogimiento).
- Para direcciones con \(d_j^2 \ll \lambda\): el factor se aproxima a 0 (mucho encogimiento).
Ridge encoge más las direcciones de baja varianza (valores singulares pequeños), que son precisamente las que están mal determinadas por los datos. Las direcciones de alta varianza (con información abundante) apenas se ven afectadas.
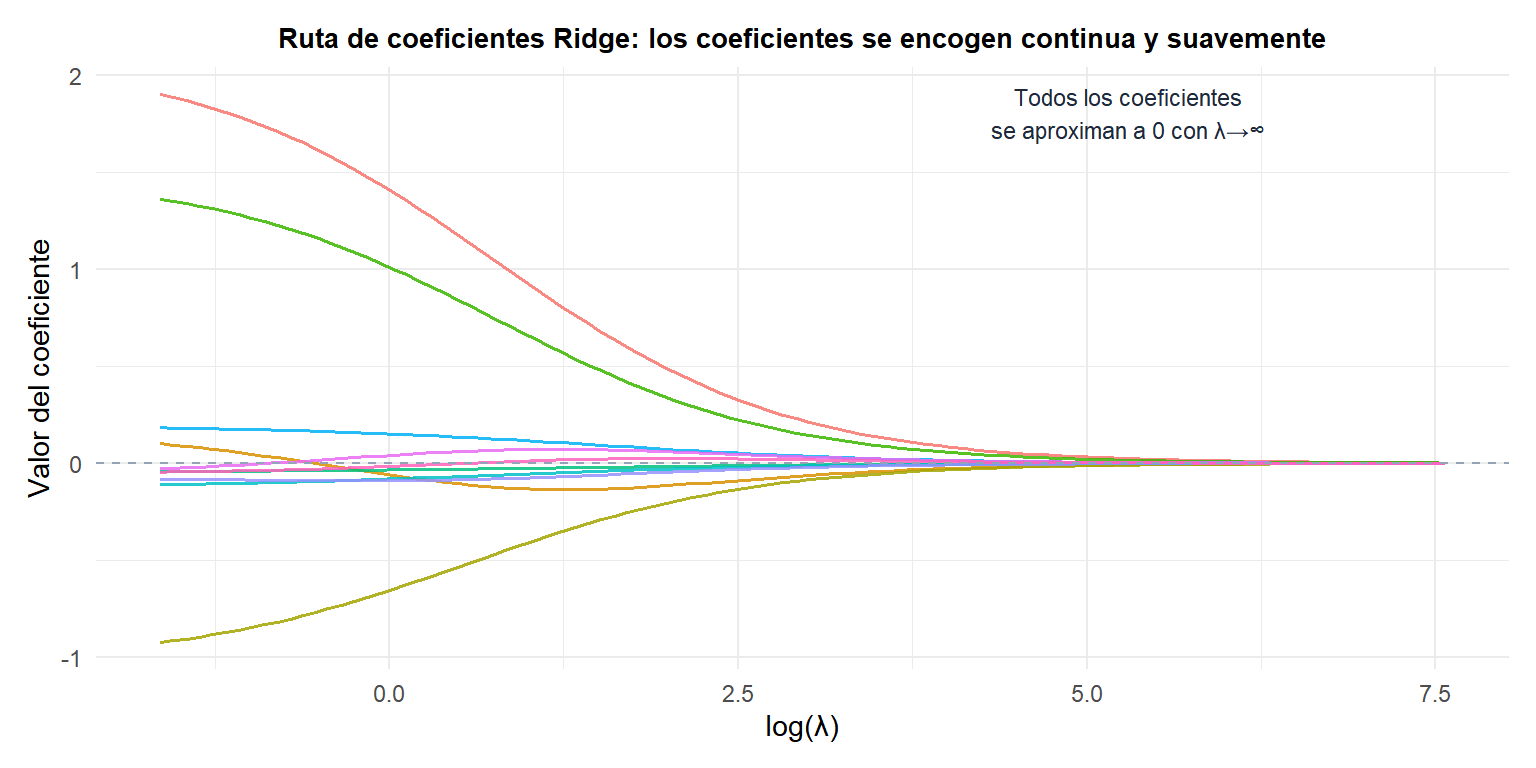
Grados de libertad efectivos
En MCO, los grados de libertad del modelo son \(p\) (número de predictores). En Ridge, son:
\[\text{df}(\lambda) = \sum_{j=1}^p \frac{d_j^2}{d_j^2 + \lambda} = \text{tr}(\mathbf{H}_\lambda)\]
donde \(\mathbf{H}_\lambda = \mathbf{X}(\mathbf{X}^T\mathbf{X}+\lambda\mathbf{I})^{-1}\mathbf{X}^T\) es la matriz sombrero Ridge. Con \(\lambda=0\) se recuperan los \(p\) grados de libertad del MCO; con \(\lambda \to \infty\), los grados de libertad tienden a cero. Esto permite comparar modelos Ridge con distintos \(\lambda\) en términos de complejidad efectiva.
Ridge como solución a la multicolinealidad
Cuando dos predictores \(x_j\) y \(x_k\) están correlacionados, \(\mathbf{X}^T\mathbf{X}\) es casi singular: los coeficientes MCO son muy inestables (errores estándar enormes). Ridge estabiliza la estimación:
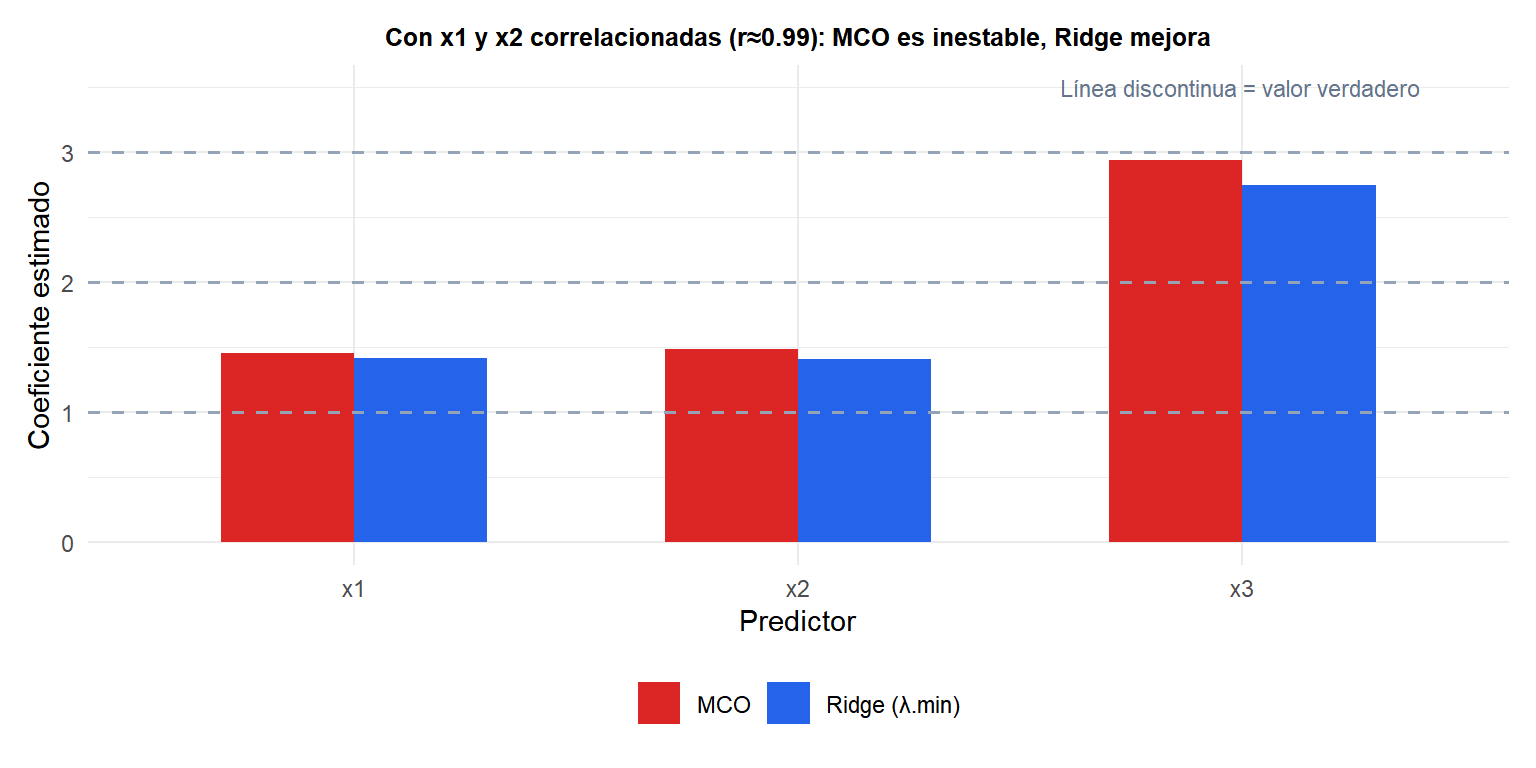
Los coeficientes MCO de \(x_1\) y \(x_2\) son inestables y alejados de los valores reales (2 y 1) porque la multicolinealidad hace que el modelo no pueda distinguir el efecto individual de cada predictor. Ridge redistribuye el peso entre los predictores correlacionados, recuperando estimaciones más próximas a los valores reales.
💡 Regresión Ridge en R
library(glmnet)
# Validación cruzada para seleccionar lambda
cv_ridge <- cv.glmnet(X, y, alpha=0, nfolds=10)
plot(cv_ridge)
# Coeficientes con lambda.min y lambda.1se
coef(cv_ridge, s="lambda.min")
coef(cv_ridge, s="lambda.1se")
# Ruta completa de coeficientes
fit_ridge <- glmnet(X, y, alpha=0)
plot(fit_ridge, xvar="lambda")
# Predicciones
predict(cv_ridge, newx=X_test, s="lambda.min")
