Regresión logística
La regresión logística modela la probabilidad de un resultado binario usando la función logística para proyectar una combinación lineal de predictores en el intervalo \([0,1]\). Es el modelo de clasificación más utilizado en biomedicina, economía y ciencias sociales por su interpretabilidad: los coeficientes traducen directamente en odds ratios con intervalos de confianza.
El modelo
Sea \(y_i \in \{0, 1\}\) la variable resultado. La regresión logística modela:
\[P(y_i = 1 \mid \mathbf{x}_i) = \sigma(\mathbf{x}_i^T\boldsymbol{\beta}) = \frac{1}{1 + e^{-\mathbf{x}_i^T\boldsymbol{\beta}}}\]
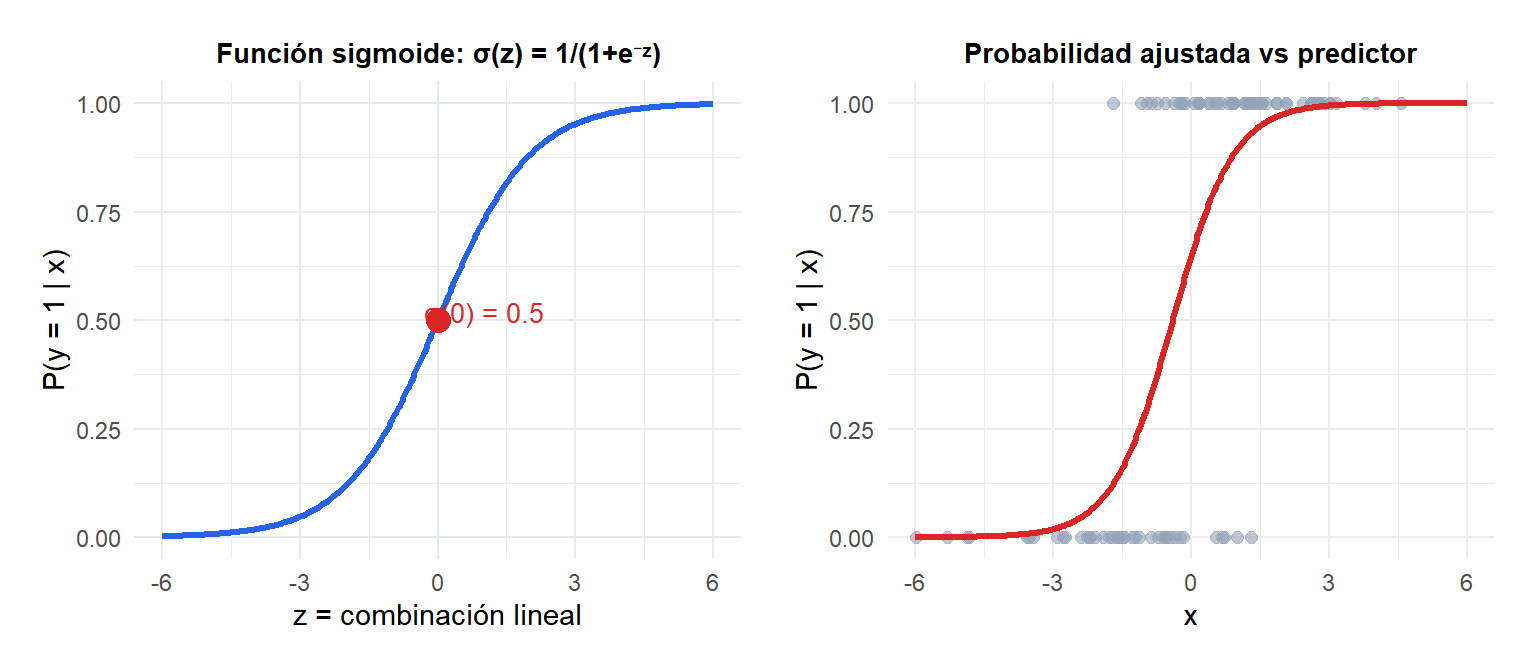
donde \(\sigma(z) = 1/(1+e^{-z})\) es la función sigmoide. Tomando el logaritmo del cociente de probabilidades (log-odds o logit):
\[\log\frac{P(y=1 \mid \mathbf{x})}{P(y=0 \mid \mathbf{x})} = \beta_0 + \beta_1 x_1 + \cdots + \beta_k x_k\]
El modelo es lineal en los log-odds: el log-odds de la clase positiva es una combinación lineal de los predictores.
Estimación por máxima verosimilitud
Los coeficientes se estiman maximizando la función de log-verosimilitud:
\[\ell(\boldsymbol{\beta}) = \sum_{i=1}^n \left[y_i \log p_i + (1-y_i)\log(1-p_i)\right]\]
donde \(p_i = \sigma(\mathbf{x}_i^T\boldsymbol{\beta})\). No existe solución en forma cerrada: se optimiza iterativamente con el algoritmo de Newton-Raphson, equivalente a mínimos cuadrados iterativamente reponderados (IRLS). La función de log-verosimilitud es cóncava, por lo que hay un único máximo global.
Interpretación: odds ratios
El exponencial de un coeficiente es el odds ratio (OR): el factor multiplicativo en el odds cuando \(x_j\) aumenta una unidad con los demás predictores fijos:
\[e^{\beta_j} = \frac{\text{odds}(y=1 \mid x_j+1)}{\text{odds}(y=1 \mid x_j)} = \frac{P(y=1 \mid x_j+1)/(1-P(y=1 \mid x_j+1))}{P(y=1 \mid x_j)/(1-P(y=1 \mid x_j))}\]
En un modelo de riesgo de enfermedad cardíaca:
- \(\hat{\beta}_{\text{edad}} = 0{,}05\) → \(e^{0{,}05} \approx 1{,}05\): cada año adicional de edad multiplica el odds de enfermedad por 1,05, es decir, un aumento del 5 %.
- \(\hat{\beta}_{\text{fumador}} = 0{,}8\) → \(e^{0{,}8} \approx 2{,}23\): ser fumador multiplica el odds por 2,23, un 123 % más que los no fumadores.
- \(\hat{\beta}_{\text{ejercicio}} = -0{,}3\) → \(e^{-0{,}3} \approx 0{,}74\): hacer ejercicio reduce el odds al 74 %, es decir, un 26 % menos.
Un intervalo de confianza para el OR que no contenga 1 indica que la variable es estadísticamente significativa.
Evaluación: curva ROC y AUC
Para clasificación binaria, el modelo produce una probabilidad \(\hat{p}_i\). Una predicción de clase requiere un umbral \(t\): predice clase 1 si \(\hat{p}_i > t\).
Para cada umbral \(t \in [0,1]\): - Tasa de verdaderos positivos (TVP) = sensibilidad: \(P(\hat{y}=1 \mid y=1)\). - Tasa de falsos positivos (TFP) = 1 - especificidad: \(P(\hat{y}=1 \mid y=0)\).
La curva ROC representa la TVP frente a la TFP para todos los umbrales posibles. El área bajo la curva (AUC) es la probabilidad de que el modelo asigne una puntuación más alta a un positivo aleatorio que a un negativo aleatorio.
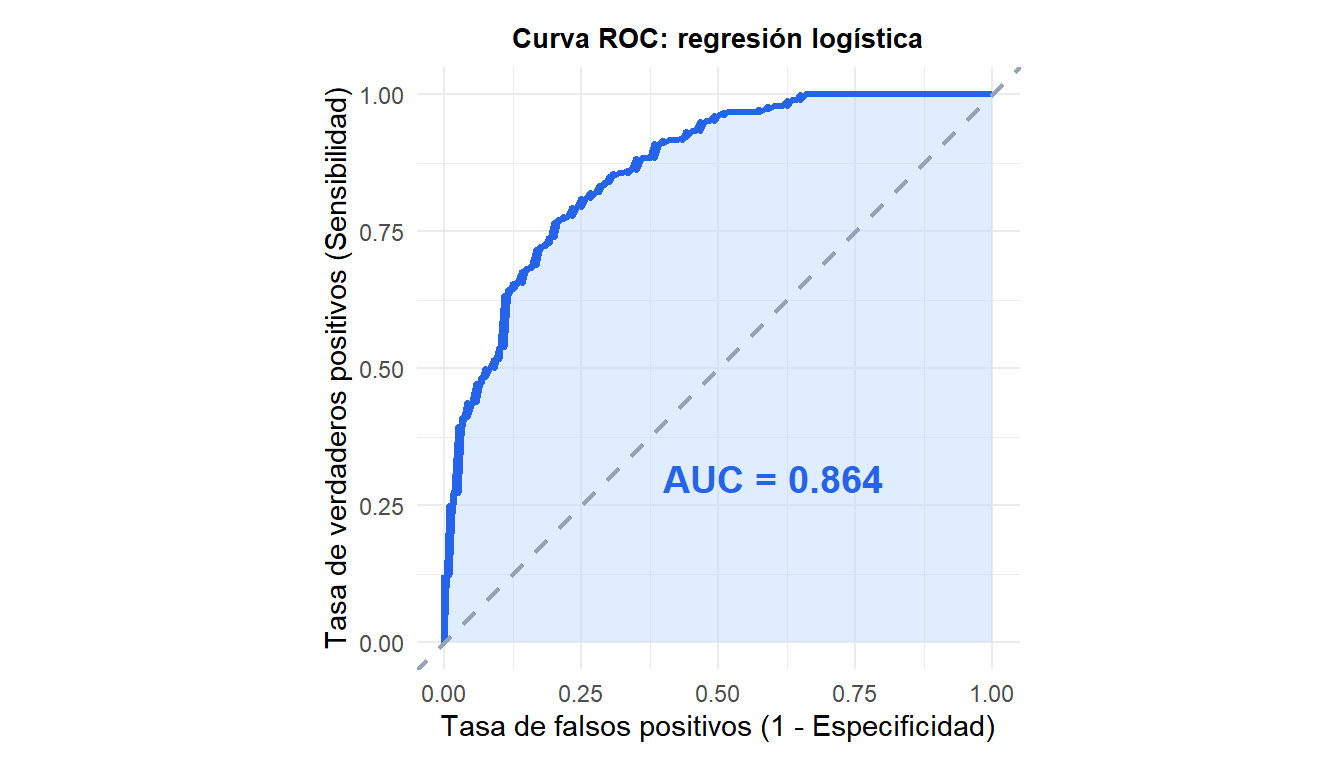
Un AUC de 0,5 corresponde a la predicción aleatoria (diagonal discontinua). Un AUC de 1,0 es la discriminación perfecta. En la práctica, AUC > 0,8 se considera buena discriminación, AUC > 0,9 excelente.
Extensión multiclase: regresión softmax
Para \(K > 2\) clases, la regresión softmax (regresión logística multinomial) generaliza:
\[P(y_i = k \mid \mathbf{x}_i) = \frac{e^{\mathbf{x}_i^T\boldsymbol{\beta}_k}}{\sum_{j=1}^K e^{\mathbf{x}_i^T\boldsymbol{\beta}_j}}, \qquad k = 1, \ldots, K\]
con \(K-1\) vectores de coeficientes independientes (uno se normaliza a cero como referencia). Las probabilidades suman 1 por construcción.
⚠️ La regresión logística no requiere predictores normales
Al contrario que LDA, la regresión logística no asume ninguna distribución de los predictores: es un modelo discriminativo que modela directamente \(P(y \mid x)\) sin modelar \(P(x)\). Funciona bien con predictores continuos, binarios y categóricos mezclados.
Sin embargo, la regresión logística sí requiere que la relación entre los log-odds y los predictores sea lineal. Si la relación real es fuertemente no lineal, considera añadir términos polinómicos, splines o cambiar a un clasificador más flexible.
💡 Regresión logística en R
fit <- glm(y ~ x1 + x2, data = df, family = binomial)
summary(fit)
# Odds ratios con intervalos de confianza
exp(coef(fit))
exp(confint(fit))
# Probabilidades predichas
predict(fit, newdata = df_nuevo, type = "response")
# Curva ROC y AUC
library(pROC)
pred_probs <- predict(fit, type = "response")
roc_obj <- roc(df$y, pred_probs)
auc(roc_obj)
plot(roc_obj)
# Regresión logística multinomial
library(nnet)
fit_multi <- multinom(y ~ x1 + x2, data = df)
