Naive Bayes
Naive Bayes aplica el teorema de Bayes a la clasificación asumiendo que todas las características son condicionalmente independientes dada la etiqueta de clase. El supuesto casi siempre es incorrecto en la práctica, pero Naive Bayes funciona sorprendentemente bien, especialmente en clasificación de texto, donde sigue siendo uno de los mejores modelos de referencia. Sus principales ventajas son la velocidad, la interpretabilidad y el buen comportamiento con conjuntos de entrenamiento pequeños.
Del teorema de Bayes a un clasificador
El objetivo es encontrar la clase \(c\) que maximiza la probabilidad a posteriori dadas las características observadas \(\mathbf{x} = (x_1, \ldots, x_p)\):
\[\hat{c} = \arg\max_c P(C=c \mid \mathbf{x}) = \arg\max_c \frac{P(\mathbf{x} \mid C=c)\, P(C=c)}{P(\mathbf{x})}\]
Como \(P(\mathbf{x})\) es igual para todas las clases, solo necesitamos:
\[\hat{c} = \arg\max_c P(\mathbf{x} \mid C=c)\, P(C=c)\]
El problema: estimar \(P(\mathbf{x} \mid C=c)\) requiere la distribución conjunta de todos los \(p\) predictores dada la clase, lo que es intratable para \(p\) grande.
El supuesto ingenuo: los predictores son condicionalmente independientes dada la clase:
\[P(\mathbf{x} \mid C=c) = \prod_{j=1}^p P(x_j \mid C=c)\]
Esto reduce la estimación a \(p\) problemas univariados, uno por predictor. El clasificador se convierte en:
\[\hat{c} = \arg\max_c P(C=c) \prod_{j=1}^p P(x_j \mid C=c)\]
En la práctica, los productos de muchas probabilidades pequeñas producen underflow numérico. Tomar logaritmos convierte el producto en una suma:
\[\hat{c} = \arg\max_c \left[\log P(C=c) + \sum_{j=1}^p \log P(x_j \mid C=c)\right]\]
Tres variantes
Las tres variantes difieren en cómo modelan \(P(x_j \mid C=c)\):
Naive Bayes gaussiano
Para predictores continuos, se asume que cada predictor sigue una distribución gaussiana dentro de cada clase:
\[P(x_j \mid C=c) = \frac{1}{\sqrt{2\pi\sigma_{jc}^2}} \exp\!\left(-\frac{(x_j - \mu_{jc})^2}{2\sigma_{jc}^2}\right)\]
Los parámetros \(\mu_{jc}\) y \(\sigma_{jc}^2\) se estiman como la media y varianza muestrales del predictor \(j\) dentro de la clase \(c\). La frontera de decisión entre dos clases es cuadrática en general (se vuelve lineal cuando \(\sigma_{jc}^2 = \sigma_j^2\) para todo \(c\)).
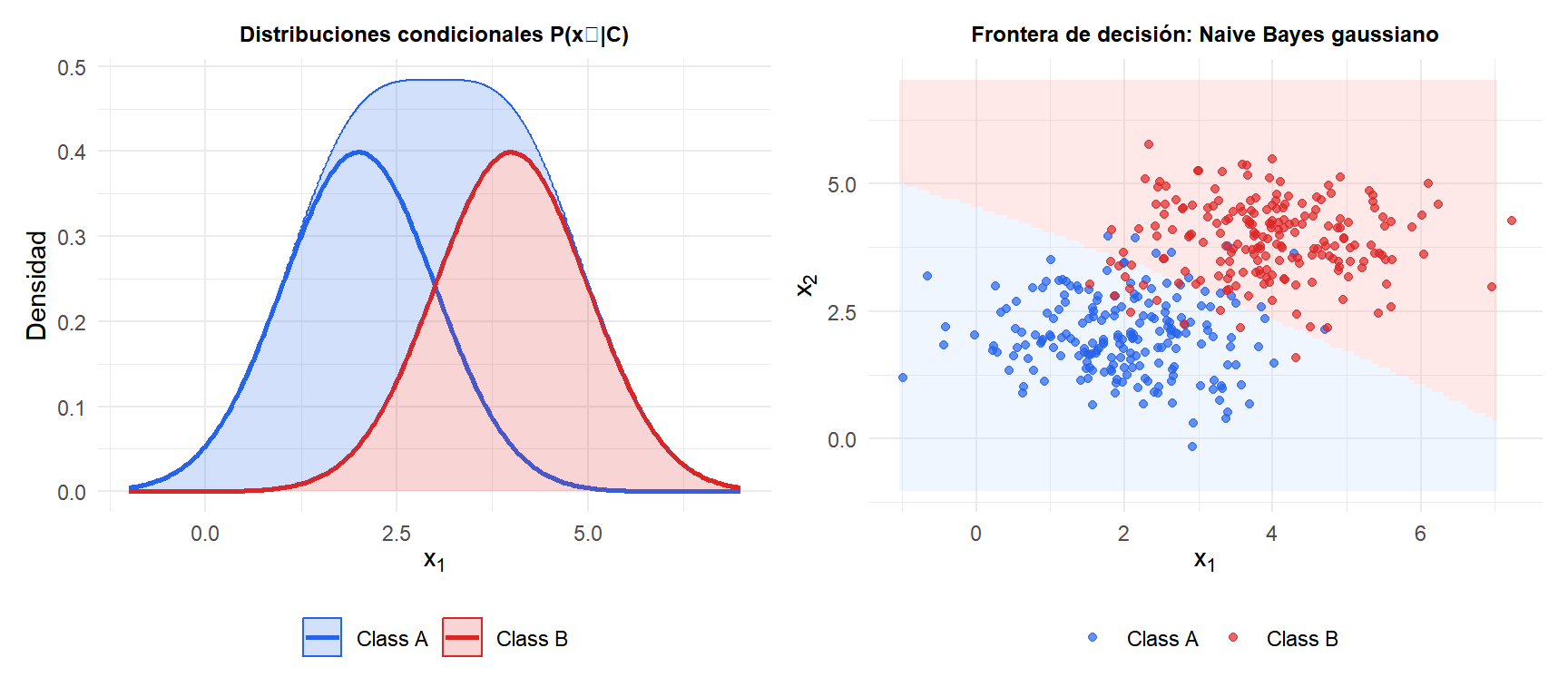
Naive Bayes multinomial
Para predictores de recuento (p. ej., frecuencias de palabras en un documento), la verosimilitud de observar los recuentos \(\mathbf{x} = (x_1, \ldots, x_p)\) dada la clase \(c\) sigue una distribución multinomial:
\[P(\mathbf{x} \mid C=c) \propto \prod_{j=1}^p \theta_{jc}^{x_j}\]
donde \(\theta_{jc} = P(\text{palabra } j \mid C=c)\) se estima como la frecuencia relativa de la palabra \(j\) en los documentos de la clase \(c\). Este es el modelo estándar para clasificación de texto y filtrado de spam: cada correo es una bolsa de palabras y el recuento de cada palabra es un predictor.
Naive Bayes de Bernoulli
Para predictores binarios (palabra presente/ausente), cada predictor sigue una distribución de Bernoulli:
\[P(x_j \mid C=c) = \theta_{jc}^{x_j}(1-\theta_{jc})^{1-x_j}\]
A diferencia del NB multinomial, el NB de Bernoulli penaliza explícitamente la ausencia de una palabra: si una palabra está ausente de un documento pero es común en una clase, esa ausencia es evidencia en contra de esa clase.
Suavizado de Laplace
El problema de frecuencia cero surge en NB multinomial y de Bernoulli: si una palabra nunca aparece en los documentos de entrenamiento de la clase \(c\), entonces \(\hat{\theta}_{jc} = 0\) y la probabilidad a posteriori completa \(P(C=c \mid \mathbf{x}) = 0\) independientemente de todos los demás predictores.
El suavizado de Laplace (suavizado aditivo con \(\alpha=1\)) añade un pseudoconteo de 1 a cada combinación predictor-clase:
\[\hat{\theta}_{jc} = \frac{n_{jc} + \alpha}{n_c + \alpha p}\]
donde \(n_{jc}\) es el recuento del predictor \(j\) en la clase \(c\), \(n_c\) es el recuento total en la clase \(c\), y \(p\) es el número de predictores. Esto garantiza que ninguna probabilidad sea exactamente cero, mientras encoge las estimaciones hacia \(1/p\).
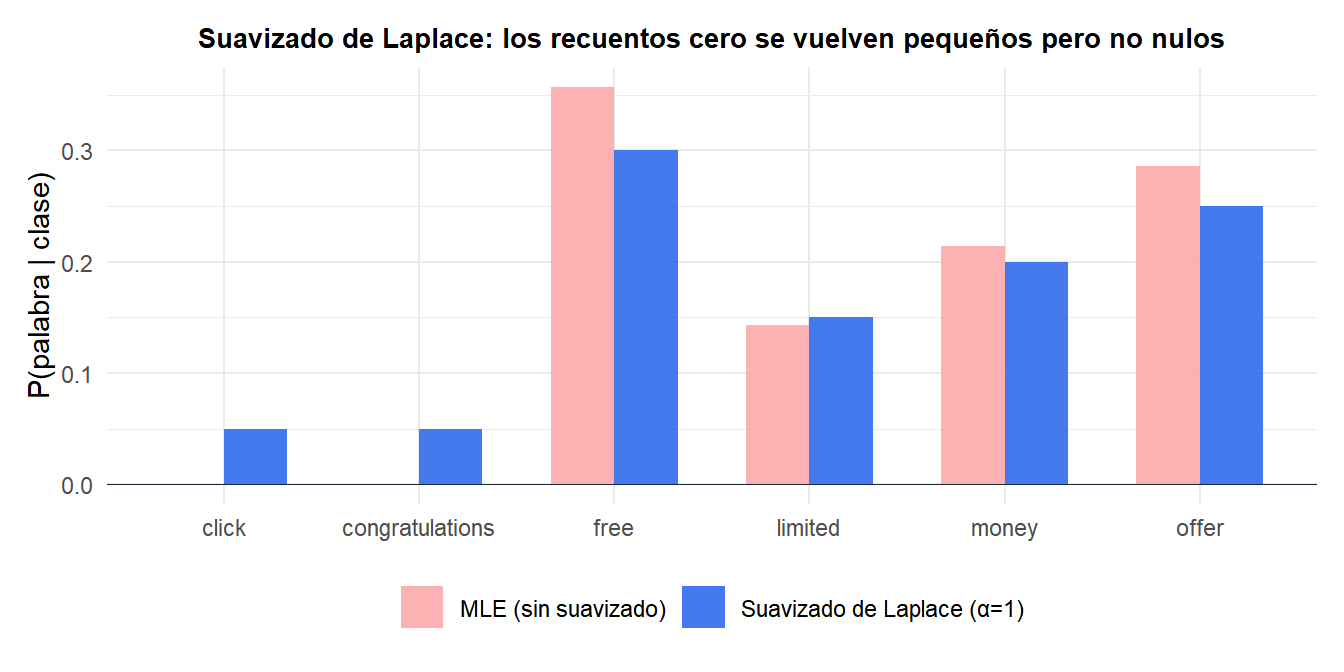
Las palabras “click” y “congratulations” tienen recuentos cero bajo MLE (rojo), lo que las hace catastróficas para cualquier documento que las contenga. El suavizado de Laplace (azul) les asigna una probabilidad pequeña pero no nula.
Por qué funciona a pesar de los supuestos incorrectos
El supuesto de independencia casi siempre se viola: las palabras en una oración están correlacionadas, las características en un historial médico están correlacionadas, los valores de píxeles en una imagen están correlacionados. Sin embargo, Naive Bayes suele funcionar bien. Dos explicaciones:
La clasificación solo necesita el orden correcto, no las probabilidades correctas. Aunque las probabilidades estimadas estén mal calibradas (y a menudo lo están), el ranking de clases por probabilidad a posteriori puede seguir siendo correcto. Naive Bayes es un mal estimador de probabilidades pero un buen clasificador.
Los errores se cancelan. Cuando los predictores están positivamente correlacionados dentro de una clase, Naive Bayes cuenta doble su evidencia. Pero la cuenta doble es igual para todas las clases, por lo que el orden relativo se preserva.
Naive Bayes falla cuando las correlaciones difieren entre clases: entonces la doble cuenta es desigual y el clasificador se sesga hacia la clase con correlaciones intraclase más fuertes.
Naive Bayes vs regresión logística
Ambos son clasificadores lineales (en log-odds) para predictores binarios. La diferencia clave es el enfoque de estimación:
- Naive Bayes es un modelo generativo: estima \(P(\mathbf{x} \mid C=c)\) y \(P(C=c)\) por separado, luego aplica el teorema de Bayes.
- Regresión logística es un modelo discriminativo: estima \(P(C \mid \mathbf{x})\) directamente.
Con predictores gaussianos y covarianzas iguales, Naive Bayes y LDA producen la misma frontera lineal. La regresión logística maximiza la verosimilitud condicional directamente y es más eficiente asintóticamente: necesita menos datos para igualar la precisión de Naive Bayes cuando los predictores no son verdaderamente independientes.
En la práctica: Naive Bayes gana con conjuntos de entrenamiento pequeños (menos que estimar); la regresión logística gana con conjuntos grandes (aprovecha la verosimilitud completa).
⚠️ Las probabilidades de Naive Bayes están mal calibradas
Las probabilidades a posteriori producidas por Naive Bayes suelen ser extremas: cercanas a 0 o 1, mucho más de lo que indican las probabilidades reales. Esto ocurre porque el supuesto de independencia ignora las correlaciones, lo que hace que el modelo sea sobreconfiado.
Si se necesitan probabilidades calibradas (p. ej., para umbrales de decisión en diagnóstico médico), aplica regresión isotónica o escalado de Platt tras Naive Bayes. Nunca uses las probabilidades a posteriori de Naive Bayes directamente para decisiones sensibles a costes sin calibración.
💡 Naive Bayes en R
library(e1071)
# Naive Bayes gaussiano (predictores continuos)
fit_gnb <- naiveBayes(y ~ ., data=df_train)
predict(fit_gnb, newdata=df_test) # etiquetas de clase
predict(fit_gnb, newdata=df_test, type="raw") # probs a posteriori
# Suavizado de Laplace (para predictores categóricos/texto)
fit_mnb <- naiveBayes(y ~ ., data=df_train, laplace=1)
# Para clasificación de texto con matriz documento-término
library(quanteda)
library(quanteda.textmodels)
dtm <- dfm(corpus)
fit_t <- textmodel_nb(dtm[train_idx,], y[train_idx], smooth=1)
predict(fit_t, newdata=dtm[test_idx,])
