Diagnósticos de regresión lineal
Los diagnósticos de regresión comprueban si los supuestos detrás de MCO se satisfacen y si alguna observación distorsiona indebidamente el modelo. Ejecutar una regresión sin diagnósticos es como aceptar un resultado sin comprobar el trabajo: las estimaciones pueden ser correctas o completamente erróneas, y no puedes saber cuál sin comprobarlo.
Los supuestos LINE
Los cuatro supuestos de la regresión lineal, recordados como LINE:
- Linealidad: \(E[y|x] = \mathbf{x}^T\boldsymbol{\beta}\) (la media condicional es lineal en los predictores).
- Independencia: los residuos \(\varepsilon_i\) son independientes entre observaciones.
- Normalidad: \(\varepsilon_i \sim N(0, \sigma^2)\).
- Equal varianza (homocedasticidad): \(\text{Var}(\varepsilon_i) = \sigma^2\) para todo \(i\).
La linealidad y la independencia son los más críticos: sus violaciones llevan a estimaciones sesgadas o inconsistentes. La normalidad importa principalmente en muestras pequeñas (la inferencia es robusta a la no normalidad para \(n\) grande vía el TCL). La heterocedasticidad no sesga \(\hat{\boldsymbol{\beta}}\) pero infla o deflacta los errores estándar, haciendo los contrastes de hipótesis no fiables.
Los cuatro gráficos diagnósticos
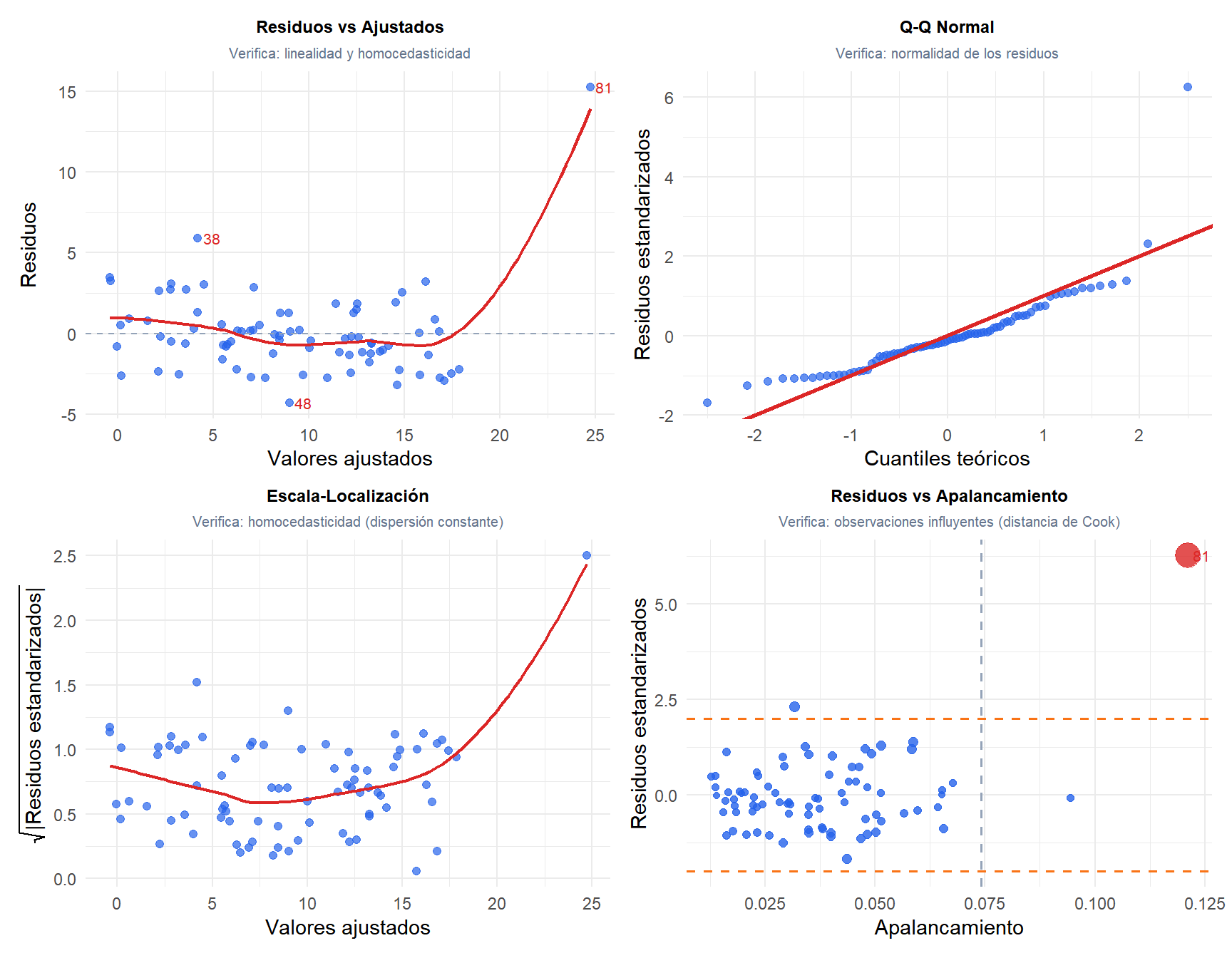
Los cuatro gráficos exponen diferentes violaciones de los supuestos:
- Residuos vs Ajustados: una línea roja plana significa que la linealidad se cumple. Una forma de U o de embudo indica no linealidad o heterocedasticidad.
- Q-Q Normal: los puntos sobre la diagonal indican normalidad. Las curvas en S indican colas pesadas; las desviaciones curvadas indican asimetría.
- Escala-Localización: una línea roja plana indica homocedasticidad. Una tendencia ascendente significa que la varianza aumenta con el valor ajustado.
- Residuos vs Apalancamiento: los puntos con alta distancia de Cook (burbujas grandes, etiquetadas) son influyentes. Las líneas horizontales discontinuas marcan \(\pm 2\) residuos estandarizados.
Contrastes formales de violación de supuestos
Contraste de Breusch-Pagan para heterocedasticidad
Regresa los residuos al cuadrado sobre los predictores. Un resultado significativo rechaza \(H_0\): varianza constante.
Contraste de Shapiro-Wilk para normalidad de residuos
Contrasta si los residuos provienen de una distribución normal. Para \(n\) grande (\(> 5{,}000\)), incluso una no normalidad trivial se detecta: usa los gráficos Q-Q para evaluar la significación práctica.
Contraste de Durbin-Watson para autocorrelación
\[DW = \frac{\sum_{i=2}^n (e_i - e_{i-1})^2}{\sum_{i=1}^n e_i^2}\]
\(DW \approx 2\) indica no autocorrelación. \(DW < 1{,}5\) sugiere autocorrelación positiva (los residuos consecutivos tienden a tener el mismo signo). Relevante para datos de series temporales; menos importante para datos transversales.
Valores atípicos, apalancamiento y puntos influyentes
Tres conceptos distintos que a menudo se confunden:
Valor atípico
Un punto con un residuo grande: el \(y_i\) observado está lejos de \(\hat{y}_i\). Se detecta por residuos estandarizados \(|e_i / \hat{\sigma}| > 2\) o \(> 3\). Un valor atípico en \(y\) no necesariamente influye en la recta de regresión si su \(x_i\) está cerca de \(\bar{x}\).
Alto apalancamiento
Un punto con un valor extremo de \(x_i\), lejos del centro del espacio de predictores. Medido por la diagonal de la matriz sombrero \(h_{ii} = \mathbf{x}_i^T(\mathbf{X}^T\mathbf{X})^{-1}\mathbf{x}_i\). Un umbral habitual es \(h_{ii} > 2(k+1)/n\). Los puntos de alto apalancamiento tienen el potencial de influir en el ajuste, pero pueden o no hacerlo dependiendo de su valor \(y_i\).
Punto influyente
Un punto que realmente cambia los coeficientes de regresión sustancialmente al ser eliminado. Combina alto apalancamiento con un residuo grande. Se mide con la distancia de Cook:
\[D_i = \frac{(\hat{\boldsymbol{\beta}} - \hat{\boldsymbol{\beta}}_{(-i)})^T \mathbf{X}^T\mathbf{X} (\hat{\boldsymbol{\beta}} - \hat{\boldsymbol{\beta}}_{(-i)})}{(k+1)\hat{\sigma}^2}\]
\(D_i > 0{,}5\) merece investigación; \(D_i > 1\) generalmente se considera influyente.
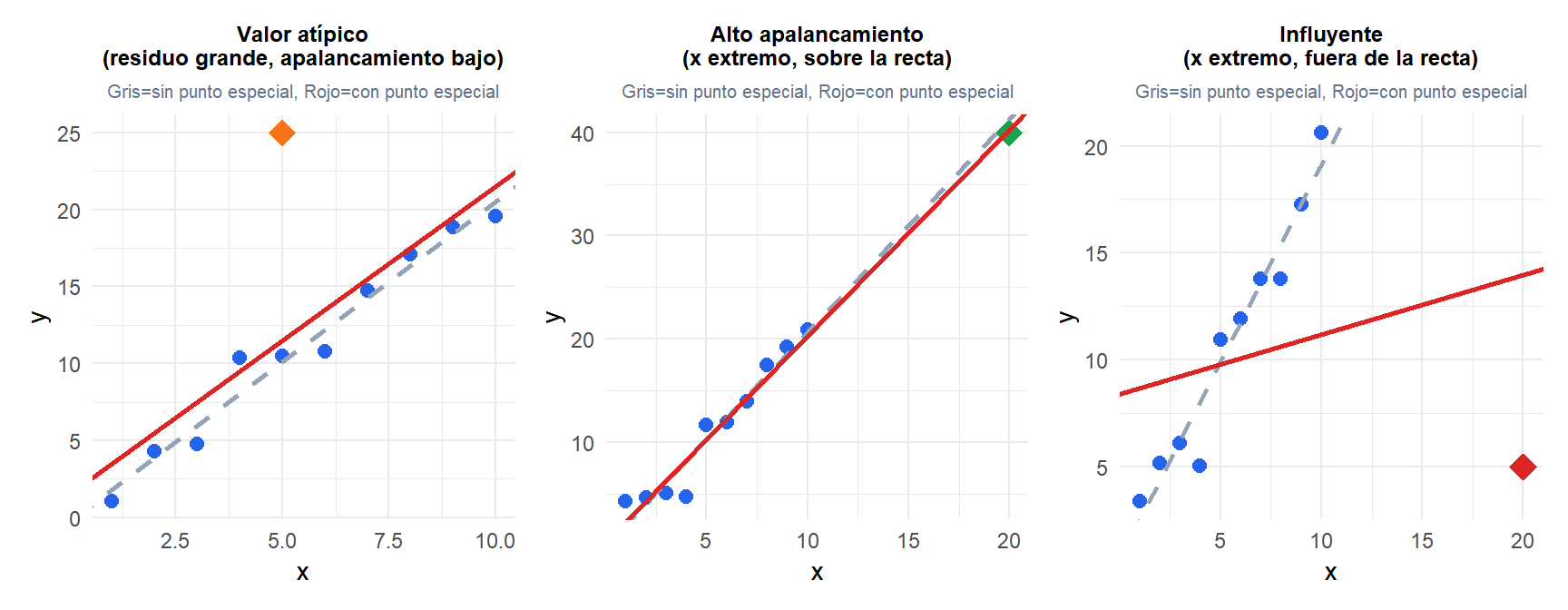
El valor atípico (naranja) tiene un residuo grande pero está en \(x=5\) (cerca de \(\bar{x}\)): la recta apenas se mueve. El punto de alto apalancamiento (verde) está lejos de \(\bar{x}\) pero se encuentra sobre la recta verdadera: la recta apenas se mueve. El punto influyente (rojo) combina \(x\) extremo con un residuo grande: la recta rota sustancialmente.
⚠️ Nunca elimines puntos influyentes sin investigarlos
Una observación influyente no es automáticamente un error. Podría ser:
- Un punto extremo pero válido que el modelo debería considerar.
- Un error de entrada de datos que debería corregirse.
- Una ruptura estructural o evento especial (una crisis financiera, un cambio de política) que justifica una variable indicadora separada.
Antes de eliminar cualquier punto, investiga por qué es influyente. Eliminar observaciones influyentes válidas para mejorar las métricas de ajuste es manipulación de datos y produce un modelo que fallará en observaciones similares en el futuro.
💡 Diagnósticos de regresión en R
fit <- lm(y ~ x1 + x2, data=df)
# Los cuatro gráficos diagnósticos de una vez
par(mfrow=c(2,2))
plot(fit)
# Contrastes formales
library(lmtest)
bptest(fit) # Breusch-Pagan: H0 = homocedasticidad
dwtest(fit) # Durbin-Watson: H0 = no autocorrelación
shapiro.test(residuals(fit)) # H0 = normalidad
# Medidas de influencia
influencePlot(fit) # apalancamiento vs residuos estandarizados
cooks.distance(fit)
hatvalues(fit)
# Todo a la vez
library(car)
outlierTest(fit) # contraste de Bonferroni para valores atípicos
vif(fit) # multicolinealidad
