DBSCAN
DBSCAN (Density-Based Spatial Clustering of Applications with Noise) define los clusters como regiones densas de puntos separadas por regiones dispersas. No requiere \(K\) de antemano, detecta valores atípicos automáticamente como puntos de ruido, y encuentra clusters de forma arbitraria. Sus dos parámetros, \(\varepsilon\) y minPts, definen qué se considera “denso”.
Conceptos clave: densidad y alcanzabilidad
\(\varepsilon\)-vecindad de un punto \(p\): el conjunto de todos los puntos dentro de la distancia \(\varepsilon\) de \(p\):
\[N_\varepsilon(p) = \{q \in D : d(p,q) \leq \varepsilon\}\]
Tipos de puntos (relativos a los parámetros \(\varepsilon\) y minPts):
- Punto núcleo: \(|N_\varepsilon(p)| \geq \text{minPts}\). Tiene suficientes vecinos para definir una región densa.
- Punto borde: \(|N_\varepsilon(p)| < \text{minPts}\) pero \(p \in N_\varepsilon(q)\) para algún punto núcleo \(q\). En el borde de un cluster.
- Punto ruido (valor atípico): ni núcleo ni borde. Aislado de cualquier región densa.
Alcanzabilidad por densidad: el punto \(q\) es alcanzable por densidad desde el punto núcleo \(p\) si existe una cadena de puntos núcleo \(p = p_1, p_2, \ldots, p_k = q\) donde cada \(p_{i+1} \in N_\varepsilon(p_i)\).
Un cluster es un conjunto máximo de puntos conectados por densidad: cada punto del cluster es alcanzable por densidad desde cada punto núcleo del cluster.
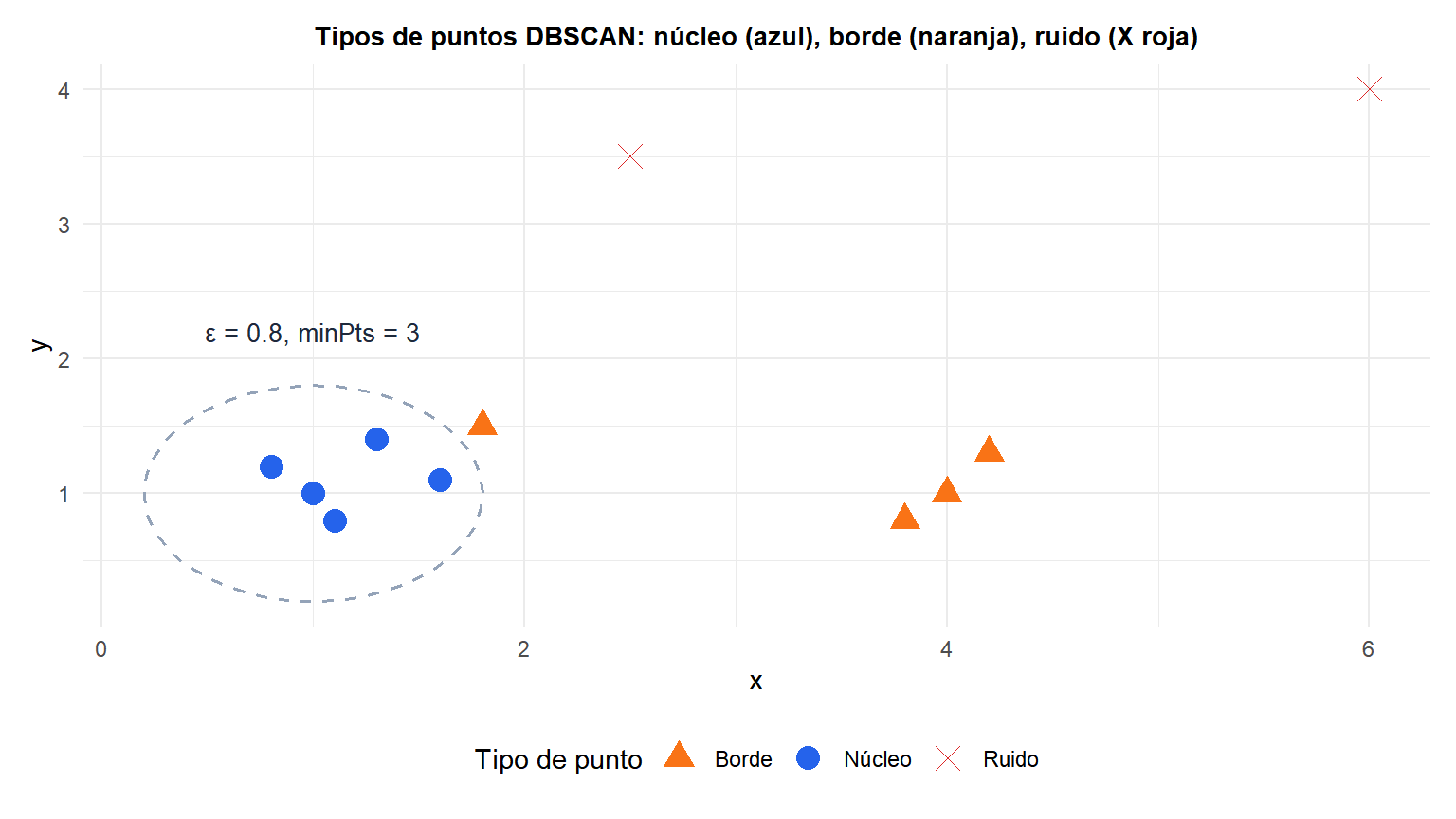
Los círculos discontinuos muestran la \(\varepsilon\)-vecindad de dos puntos núcleo. Los puntos núcleo azules tienen al menos minPts vecinos dentro de \(\varepsilon\); los puntos borde naranjas están dentro de \(\varepsilon\) de un núcleo pero no cumplen minPts por sí mismos; la X roja es ruido.
El algoritmo
Para cada punto no visitado p:
Marcar p como visitado
Si |N_eps(p)| < minPts:
Etiquetar p como Ruido
Si no:
Crear un nuevo cluster C
Añadir p a C
Añadir todos los puntos en N_eps(p) a un conjunto semilla S
Para cada punto q en S:
Si q no ha sido visitado:
Marcar q como visitado
Si |N_eps(q)| >= minPts:
Añadir N_eps(q) a S
Si q no pertenece aún a un cluster:
Añadir q a CCon un índice espacial (kd-tree o ball tree), la complejidad es \(O(n \log n)\). Sin él (fuerza bruta): \(O(n^2)\). El algoritmo es determinista dados \(\varepsilon\) y minPts: no hay inicialización aleatoria.
DBSCAN vs k-medias en datos no esféricos
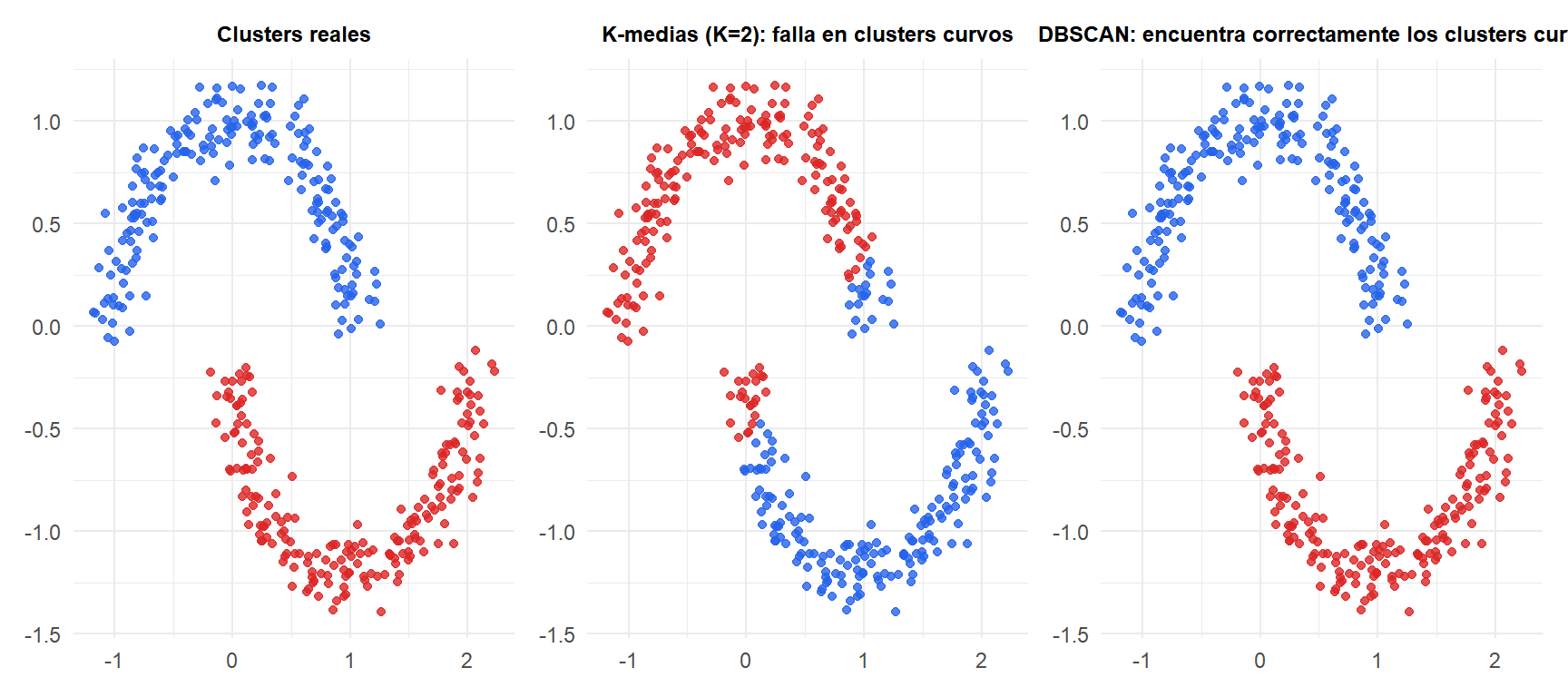
K-medias fuerza una partición de Voronoi: traza una frontera recta entre las dos medias lunas y clasifica mal la mitad de cada una. DBSCAN sigue la densidad de cada media luna y recupera correctamente ambos clusters curvos.
Elegir \(\varepsilon\) y minPts
minPts
Una regla práctica habitual: minPts \(\geq\) dimensionalidad + 1, típicamente 4 o 5 para datos 2D, aumentando con la dimensionalidad. Un minPts mayor hace el algoritmo más robusto al ruido pero puede perder clusters pequeños.
\(\varepsilon\): el gráfico de distancia k
Para cada punto, calcula la distancia al \(k\)-ésimo vecino más cercano (\(k\) = minPts - 1). Ordena estas distancias de mayor a menor y represéntalas. El “codo” de este gráfico de distancia-k sugiere un buen \(\varepsilon\): por debajo del codo, la mayoría de los puntos son núcleo; por encima, la mayoría son ruido.
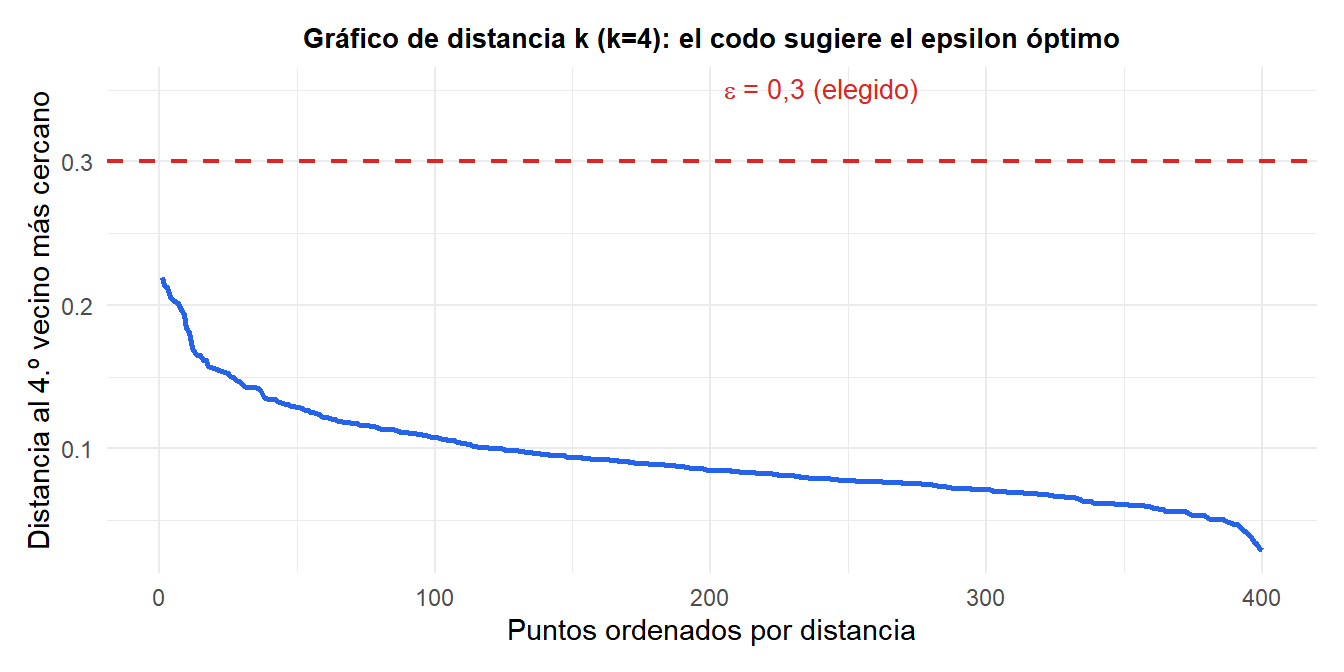
La caída brusca en las distancias k ordenadas marca el límite entre puntos núcleo y ruido. La línea roja discontinua en \(\varepsilon=0{,}3\) es donde se produce el codo.
Cuándo falla DBSCAN
DBSCAN asume que los clusters tienen densidad uniforme. Tiene problemas cuando:
- Clusters de densidad variable: un único \(\varepsilon\) puede ser demasiado pequeño para clusters dispersos (se fragmentan en ruido) y demasiado grande para los densos (se fusionan). HDBSCAN (DBSCAN jerárquico) aborda esto construyendo una jerarquía de niveles de densidad.
- Alta dimensionalidad: la maldición de la dimensionalidad hace que todos los puntos estén aproximadamente a la misma distancia, por lo que ningún \(\varepsilon\) único separa las regiones densas de las dispersas. DBSCAN pierde su significado más allá de \(d \approx 10\)-15 características.
- Conjuntos de datos muy grandes: incluso con indexación espacial, las consultas de \(\varepsilon\)-vecindad pueden ser lentas en alta dimensionalidad.
⚠️ Las etiquetas de cluster de DBSCAN no son estables ante parámetros distintos
DBSCAN es determinista dados \(\varepsilon\) y minPts, pero las etiquetas de cluster (qué cluster recibe la etiqueta 1, 2, etc.) pueden diferir entre implementaciones o ejecuciones con datos reordenados. Los puntos borde que caen dentro de \(\varepsilon\) de varios clusters se asignan al primer punto núcleo procesado.
Más importante: pequeños cambios en \(\varepsilon\) pueden causar grandes cambios en el clustering. Prueba siempre un rango de valores de \(\varepsilon\) cerca del codo del gráfico de distancia-k y comprueba que los resultados son estables. Un resultado que cambia completamente con un cambio del 10% en \(\varepsilon\) no es fiable.
💡 DBSCAN en R
library(dbscan)
# Gráfico de distancia k para elegir epsilon
kNNdistplot(X, k=4)
abline(h=0.3, col="red", lty=2)
# Ajustar DBSCAN
db <- dbscan(X, eps=0.3, minPts=5)
db$cluster # 0 = ruido, 1,2,... = clusters
table(db$cluster)
# Representar resultados
plot(X, col=db$cluster+1, pch=20)
# HDBSCAN (maneja densidad variable)
hdb <- hdbscan(X, minPts=5)
plot(hdb$hc) # dendrograma del árbol de clusters condensado
# LOF (Factor de Outlier Local): puntuación de anomalía basada en densidad continua
lof_scores <- lof(X, minPts=5)
plot(X, col=ifelse(lof_scores > 2, "red","black"), pch=20)
