Árboles de decisión
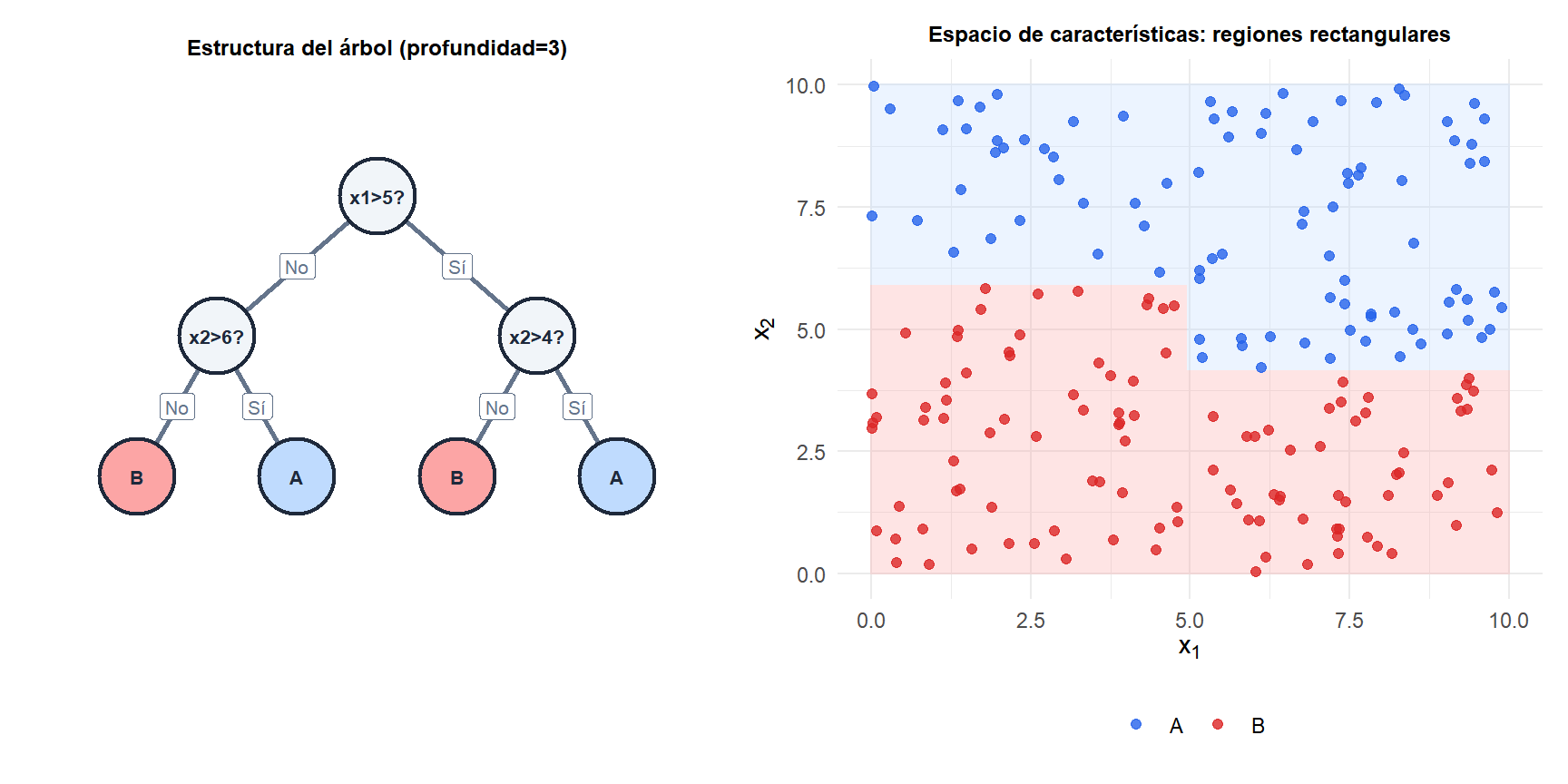
Un árbol de decisión particiona el espacio de características en regiones rectangulares dividiendo recursivamente sobre el predictor y el umbral que mejor separa las clases (o reduce el error de predicción en regresión). El resultado es una partición interpretable y alineada con los ejes: cada predicción es una secuencia de preguntas sí/no sobre los predictores. Los árboles son la base de los métodos ensemble más potentes: random forest y gradient boosting.
Partición binaria recursiva
El algoritmo CART (Classification and Regression Trees) construye el árbol de arriba hacia abajo:
- En cada nodo, considera todos los predictores \(j\) y todos los umbrales posibles \(t\).
- Elige el par \((j, t)\) que minimiza la impureza ponderada de los dos nodos hijo resultantes.
- Recurre en cada nodo hijo hasta que se cumple un criterio de parada (profundidad máxima, tamaño mínimo de nodo, o sin mejora posible).
- Asigna a cada nodo hoja la clase más frecuente (clasificación) o la respuesta media (regresión).
La búsqueda de divisiones es voraz: en cada nodo se elige la mejor división local sin anticipar el futuro. Esto no garantiza el árbol globalmente óptimo, pero encontrarlo es NP-difícil.
Criterios de división: impureza
Para un nodo con \(n\) puntos de los cuales \(n_k\) pertenecen a la clase \(k\), con \(\hat{p}_k = n_k/n\):
Índice Gini: \(G = 1 - \sum_k \hat{p}_k^2\). Mide la probabilidad de clasificar incorrectamente un punto elegido al azar. \(G=0\) para un nodo puro, \(G=0{,}5\) para máxima impureza binaria. Es el estándar en CART.
Ganancia de información (entropía): \(H = -\sum_k \hat{p}_k \log_2 \hat{p}_k\). La ganancia de información es la entropía del padre menos la entropía ponderada de los hijos. En la práctica, Gini y entropía producen resultados similares.
MSE (árboles de regresión): \(\text{MSE} = \frac{1}{n}\sum_{i \in \text{nodo}} (y_i - \bar{y})^2\). La mejor división minimiza la suma ponderada del MSE en los dos nodos hijo.
Poda: prevenir el sobreajuste
Un árbol completamente crecido ajusta perfectamente los datos de entrenamiento pero generaliza mal. La poda por complejidad de coste añade una penalización por el tamaño del árbol:
\[R_\alpha(T) = R(T) + \alpha|T|\]
donde \(R(T)\) es la tasa de error de entrenamiento, \(|T|\) es el número de hojas y \(\alpha \geq 0\) es el parámetro de complejidad. Para cada \(\alpha\), existe un único subárbol \(T_\alpha\) que minimiza \(R_\alpha\). Al aumentar \(\alpha\), se podan ramas progresivamente. El \(\alpha\) óptimo se selecciona por validación cruzada.
Importancia de variables
La importancia del predictor \(j\) es la reducción total de impureza atribuida a las divisiones sobre \(j\), ponderada por el número de muestras que pasan por cada división:
\[\text{Importancia}(j) = \sum_{\text{divisiones sobre } j} \frac{n_{\text{nodo}}}{n} \cdot \Delta\text{Impureza}\]
Los predictores usados cerca de la raíz (donde pasan más muestras) contribuyen más. Esta medida puede estar sesgada hacia predictores con muchos valores únicos.
Propiedades de los árboles
Ventajas: - Interpretables: pueden visualizarse y explicarse a audiencias no técnicas. - No requieren escalado de características. - Manejan tipos mixtos (numérico y categórico) de forma nativa. - Capturan automáticamente interacciones entre predictores.
Limitaciones: - Alta varianza: pequeños cambios en los datos producen árboles completamente diferentes. - Fronteras alineadas con ejes: no capturan fronteras diagonales sin muchas divisiones. - La búsqueda voraz no garantiza el árbol globalmente óptimo.
⚠️ Un solo árbol de decisión raramente es competitivo
La alta varianza de los árboles individuales los hace malos predictores por sí solos. Casi siempre se usan como bloques para métodos ensemble: random forest (promedia árboles profundos en muestras bootstrap, reduciendo la varianza) o gradient boosting (construye árboles superficiales secuencialmente, corrigiendo los errores). Un árbol podado individual es valioso para la interpretabilidad, pero si el objetivo es la precisión de predicción, compara siempre con random forest o gradient boosting.
💡 Árboles de decisión en R
library(rpart)
# Árbol de clasificación completo
fit <- rpart(y ~ ., data=df_train, method="class",
control=rpart.control(cp=0))
# Visualización
library(rpart.plot)
rpart.plot(fit, type=4, extra=101)
# Poda: elegir cp por validación cruzada
printcp(fit); plotcp(fit)
best_cp <- fit$cptable[which.min(fit$cptable[,"xerror"]), "CP"]
fit_podado <- prune(fit, cp=best_cp)
# Importancia de variables
fit$variable.importance / sum(fit$variable.importance)
