Análisis de correspondencias
El análisis de correspondencias (CA) es el equivalente del PCA para tablas de contingencia. Encuentra una representación de baja dimensión de las filas y columnas de una tabla de frecuencias bidireccional que preserva las distancias chi-cuadrado entre perfiles. El resultado es un biplot donde las filas y columnas cercanas entre sí están asociadas, y las filas o columnas cerca del origen tienen perfiles poco destacables.
La tabla de contingencia y los perfiles
El CA comienza con una tabla de contingencia \(\mathbf{N}\) de tamaño \(I \times J\), donde \(n_{ij}\) es la frecuencia de la categoría de fila \(i\) y la categoría de columna \(j\). Se define:
- \(n = \sum_{i,j} n_{ij}\): total general.
- \(\mathbf{P} = \mathbf{N}/n\): matriz de correspondencias (frecuencias relativas).
- \(r_i = \sum_j p_{ij}\): marginales de fila.
- \(c_j = \sum_i p_{ij}\): marginales de columna.
El perfil de fila de la fila \(i\) es \(\mathbf{f}_i = (p_{i1}/r_i, \ldots, p_{iJ}/r_i)\): la distribución condicional de columnas dada la fila \(i\). El perfil de columna de la columna \(j\) es \(\mathbf{g}_j = (p_{1j}/c_j, \ldots, p_{Ij}/c_j)\).
El CA encuentra coordenadas para filas y columnas tales que:
- Las filas (columnas) con perfiles similares están cerca.
- La distancia usada es la distancia chi-cuadrado, que pondera cada columna (fila) por el inverso de su frecuencia marginal, dando más peso a las categorías raras.
La distancia chi-cuadrado entre las filas \(i\) e \(i'\):
\[d^2_\chi(i,i') = \sum_j \frac{1}{c_j}\left(\frac{p_{ij}}{r_i} - \frac{p_{i'j}}{r_{i'}}\right)^2\]
Descomposición SVD
El CA aplica SVD a la matriz de residuos estandarizados:
\[s_{ij} = \frac{p_{ij} - r_i c_j}{\sqrt{r_i c_j}}\]
El numerador \(p_{ij} - r_i c_j\) es la desviación de la independencia: si filas y columnas fueran independientes, la proporción esperada sería \(r_i c_j\). El denominador estandariza por el recuento esperado.
\[\mathbf{S} = \mathbf{U}\boldsymbol{\Sigma}\mathbf{V}^T\]
Las coordenadas de filas (puntuaciones) son \(\mathbf{F} = \mathbf{D}_r^{-1/2}\mathbf{U}\boldsymbol{\Sigma}\) y las de columnas son \(\mathbf{G} = \mathbf{D}_c^{-1/2}\mathbf{V}\boldsymbol{\Sigma}\), donde \(\mathbf{D}_r\) y \(\mathbf{D}_c\) son matrices diagonales de los marginales de fila y columna.
Los valores singulares al cuadrado \(\sigma_k^2\) son las inercias principales: miden cuánto del estadístico chi-cuadrado total captura cada dimensión. La inercia total es igual a \(\chi^2/n\), donde \(\chi^2\) es el estadístico chi-cuadrado de la tabla de contingencia.
Ejemplo: hábitos de tabaquismo por puesto
Una encuesta registra los hábitos de tabaquismo (Ninguno, Leve, Medio, Intenso) por categoría de puesto (Director Sénior, Director Júnior, Empleado Sénior, Empleado Júnior, Secretario).
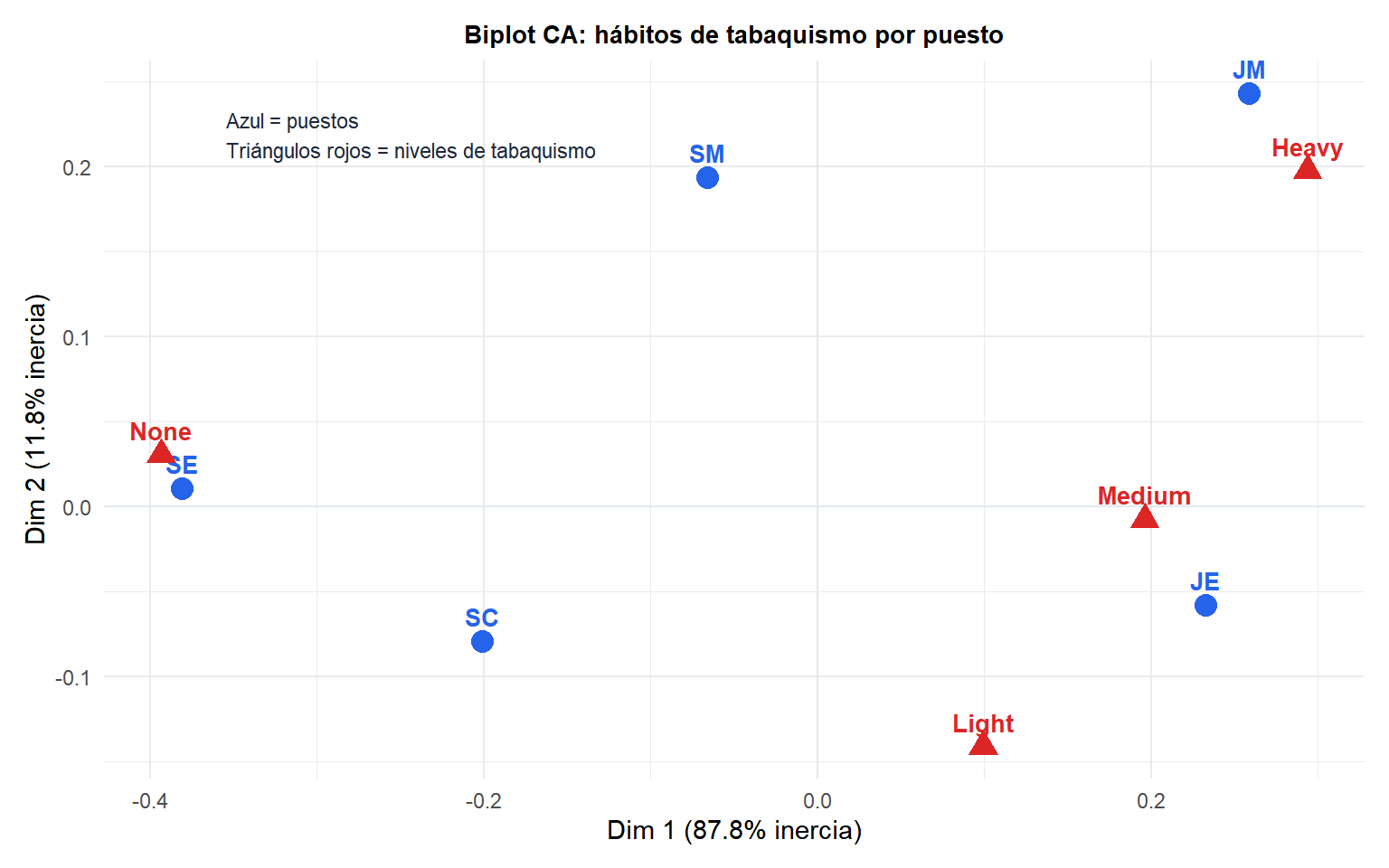
SM = Director Sénior, JM = Director Júnior, SE = Empleado Sénior, JE = Empleado Júnior, SC = Secretario. Los Empleados Júnior aparecen cerca de “Heavy”; los Directores Sénior están más cerca de “None”. La primera dimensión separa fumadores leves de intensos; la segunda separa roles directivos de no directivos.
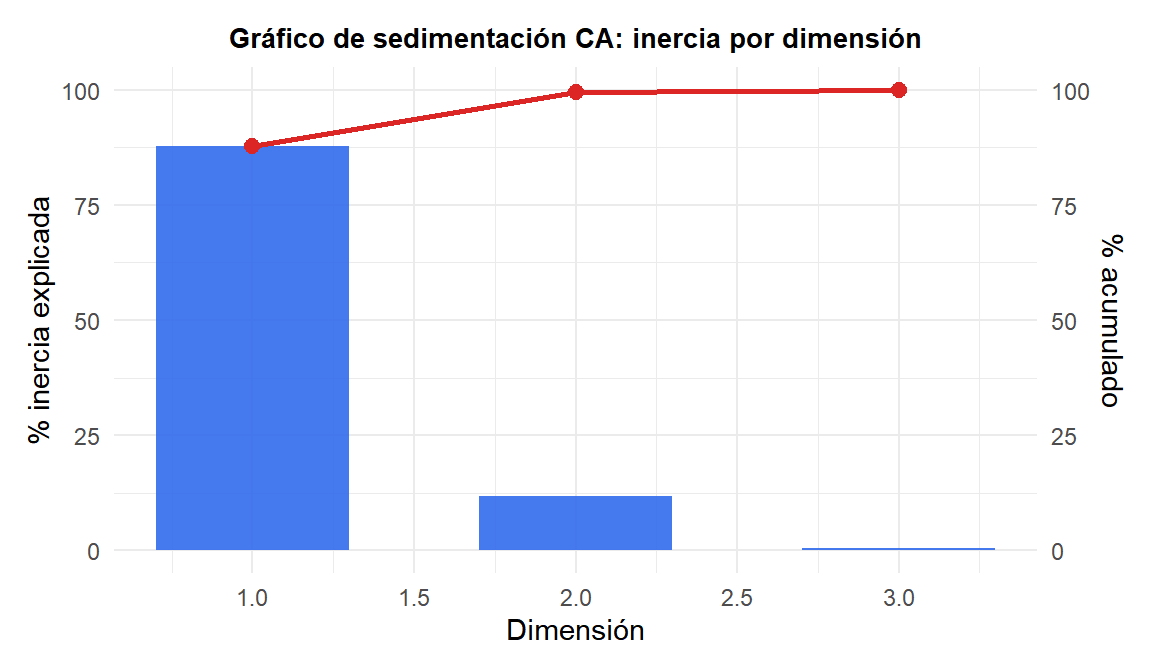
Inercia y número de dimensiones
Inercia total = \(\chi^2/n\): mide la asociación total entre filas y columnas. Inercia cero significa que filas y columnas son independientes. Inercia alta indica asociación fuerte.
Cada dimensión captura una fracción de la inercia total (análogo a la varianza explicada en PCA). Un gráfico de sedimentación de las inercias principales ayuda a decidir cuántas dimensiones retener.
Leer el biplot
Tres reglas para interpretar un biplot CA:
Regla 1: las filas cercanas entre sí tienen perfiles de columna similares. Dos puestos próximos tienen distribuciones de tabaquismo similares.
Regla 2: las columnas cercanas entre sí aparecen en perfiles de fila similares. Dos niveles de tabaquismo próximos tienden a caracterizar las mismas categorías de puesto.
Regla 3: un punto de fila cerca de un punto de columna indica asociación. Un puesto cerca de “Heavy” significa que esa categoría sobrerrepresenta a los fumadores intensos respecto a la media.
Regla 4: distancia al origen. Los puntos cerca del origen tienen perfiles próximos a la media (poco interesantes); los puntos lejos del origen tienen perfiles inusuales e impulsan las dimensiones.
⚠️ La proximidad fila-columna requiere cautela
En un biplot CA estándar (mapa simétrico), la distancia exacta entre un punto de fila y uno de columna no es directamente interpretable como distancia chi-cuadrado. El biplot proyecta filas y columnas en el mismo espacio por conveniencia visual, pero las distancias chi-cuadrado formales se definen por separado para filas y para columnas.
Para una distancia completamente interpretable entre filas y columnas usa un biplot asimétrico: representa un conjunto de perfiles como puntos y el otro como coordenadas en ese espacio de perfiles. La función fviz_ca_biplot(asymmetric=TRUE) de FactoMineR hace esto.
Análisis de Correspondencias Múltiple (ACM)
El CA maneja dos variables categóricas. El Análisis de Correspondencias Múltiple (ACM) extiende esto a tres o más variables. Cada individuo se describe mediante varias variables categóricas; el ACM encuentra un espacio de baja dimensión donde:
- Los individuos que dieron respuestas similares están cerca.
- Las categorías que se eligieron juntas con frecuencia están cerca.
- Las categorías cercanas a un individuo significan que ese individuo tiende a elegir esa categoría.
El ACM es equivalente al CA aplicado a la matriz indicadora (una matriz binaria con una columna por categoría y una fila por individuo). Se usa ampliamente en análisis de encuestas e investigación de mercado.
💡 Análisis de correspondencias en R
library(FactoMineR)
library(factoextra)
# CA sobre una tabla de contingencia
ca_res <- CA(contingency_table, ncp=5, graph=FALSE)
summary(ca_res) # inercia por dimensión
ca_res$eig # valores propios y % inercia
ca_res$row$coord # coordenadas de filas
ca_res$col$coord # coordenadas de columnas
# Biplot
fviz_ca_biplot(ca_res, repel=TRUE)
# Gráfico de sedimentación
fviz_screeplot(ca_res)
# Contribución de filas/columnas a cada dimensión
fviz_contrib(ca_res, choice="row", axes=1)
fviz_contrib(ca_res, choice="col", axes=1)
# ACM para múltiples variables categóricas
mca_res <- MCA(df_survey, graph=FALSE)
fviz_mca_biplot(mca_res, repel=TRUE)
