Intervalos de confianza bootstrap
Los intervalos de confianza bootstrap usan la distribución bootstrap de \(\hat{\theta}^*\) para construir un rango de valores plausibles para el verdadero parámetro \(\theta\). Existen cuatro métodos principales, que difieren en precisión, supuestos y coste computacional. El intervalo BCa es la opción más precisa de uso general.
Planteamiento y notación
A partir de \(B\) remuestras bootstrap tenemos estimaciones \(\hat{\theta}^*_1, \ldots, \hat{\theta}^*_B\). Sea \(\hat{\theta}^*_{(\alpha)}\) el cuantil \(\alpha\) de la distribución bootstrap. El estadístico observado en la muestra original es \(\hat{\theta}\).
- Intervalo percentil
El método más sencillo: usa directamente los cuantiles de la distribución bootstrap.
\[\text{IC}_\text{perc} = \left[\hat{\theta}^*_{(\alpha/2)},\; \hat{\theta}^*_{(1-\alpha/2)}\right]\]
Intuición: si la distribución bootstrap está centrada en \(\hat{\theta}\) y es simétrica, el intervalo percentil es una aproximación válida. Aplicación: ordena las \(B\) estimaciones bootstrap y toma los valores en las posiciones \(\lfloor B\alpha/2 \rfloor\) y \(\lceil B(1-\alpha/2) \rceil\).
Limitación: el intervalo percentil ignora el sesgo. Si la distribución bootstrap está desplazada respecto a la verdadera distribución muestral (es decir, \(E[\hat{\theta}^*] \neq \hat{\theta}\) o \(E[\hat{\theta}] \neq \theta\)), el intervalo tiene una cobertura incorrecta.
- Intervalo básico (invertido)
También llamado empírico o pivotal. Usa la distribución bootstrap de \(\hat{\theta}^* - \hat{\theta}\) como aproximación de la distribución muestral de \(\hat{\theta} - \theta\):
\[\text{IC}_\text{básico} = \left[2\hat{\theta} - \hat{\theta}^*_{(1-\alpha/2)},\; 2\hat{\theta} - \hat{\theta}^*_{(\alpha/2)}\right]\]
Intuición: refleja la distribución bootstrap alrededor de \(\hat{\theta}\). Esto corrige el sesgo en la localización de la distribución bootstrap, pero no la asimetría. Los límites están “invertidos”: el límite superior usa el cuantil inferior bootstrap y viceversa.
- Intervalo studentizado (bootstrap-t)
El intervalo más preciso cuando se dispone de una estimación del error estándar. Normaliza el estadístico bootstrap por su propio EE:
\[t_b^* = \frac{\hat{\theta}^*_b - \hat{\theta}}{\widehat{\text{EE}}^*_b}\]
\[\text{IC}_\text{stud} = \left[\hat{\theta} - t^*_{(1-\alpha/2)} \cdot \widehat{\text{EE}},\; \hat{\theta} - t^*_{(\alpha/2)} \cdot \widehat{\text{EE}}\right]\]
donde \(\widehat{\text{EE}}^*_b\) es el EE de \(\hat{\theta}^*_b\) estimado a partir de un bootstrap anidado dentro de cada remuestra (o analíticamente si se dispone de él), y \(\widehat{\text{EE}}\) es el EE de la muestra original.
Ventaja: tiene en cuenta la variación del EE entre las remuestras bootstrap, logrando precisión de segundo orden. Desventaja: requiere \(B \times B\) bootstrap anidado o una fórmula analítica del EE, lo que lo hace computacionalmente costoso.
- Intervalo BCa (corregido por sesgo y acelerado)
La recomendación estándar para uso general. Ajusta el intervalo percentil tanto por sesgo como por asimetría mediante dos cantidades:
- Corrección por sesgo \(\hat{z}_0\): mide cuánto está desplazada la distribución bootstrap respecto a \(\hat{\theta}\).
- Aceleración \(\hat{a}\): mide cómo varía el EE de \(\hat{\theta}\) con el verdadero valor del parámetro (estimado mediante jackknife).
\[\hat{z}_0 = \Phi^{-1}\!\left(\frac{\#\{\hat{\theta}^*_b < \hat{\theta}\}}{B}\right)\]
\[\hat{a} = \frac{\sum_{i=1}^n (\bar{\psi} - \psi_i)^3}{6\left[\sum_{i=1}^n (\bar{\psi} - \psi_i)^2\right]^{3/2}}, \quad \psi_i = \hat{\theta}_{(i)} \text{ (jackknife)}\]
\[\alpha_1 = \Phi\!\left(\hat{z}_0 + \frac{\hat{z}_0 + z_{\alpha/2}}{1 - \hat{a}(\hat{z}_0 + z_{\alpha/2})}\right), \quad \alpha_2 = \Phi\!\left(\hat{z}_0 + \frac{\hat{z}_0 + z_{1-\alpha/2}}{1 - \hat{a}(\hat{z}_0 + z_{1-\alpha/2})}\right)\]
\[\text{IC}_\text{BCa} = \left[\hat{\theta}^*_{(\alpha_1)},\; \hat{\theta}^*_{(\alpha_2)}\right]\]
Cuando \(\hat{z}_0 = 0\) (sin sesgo) y \(\hat{a} = 0\) (sin asimetría), el BCa se reduce al intervalo percentil. El BCa logra precisión de segundo orden: su error de cobertura es \(O(n^{-1})\) frente a \(O(n^{-1/2})\) del intervalo percentil.
Comparación de los cuatro métodos
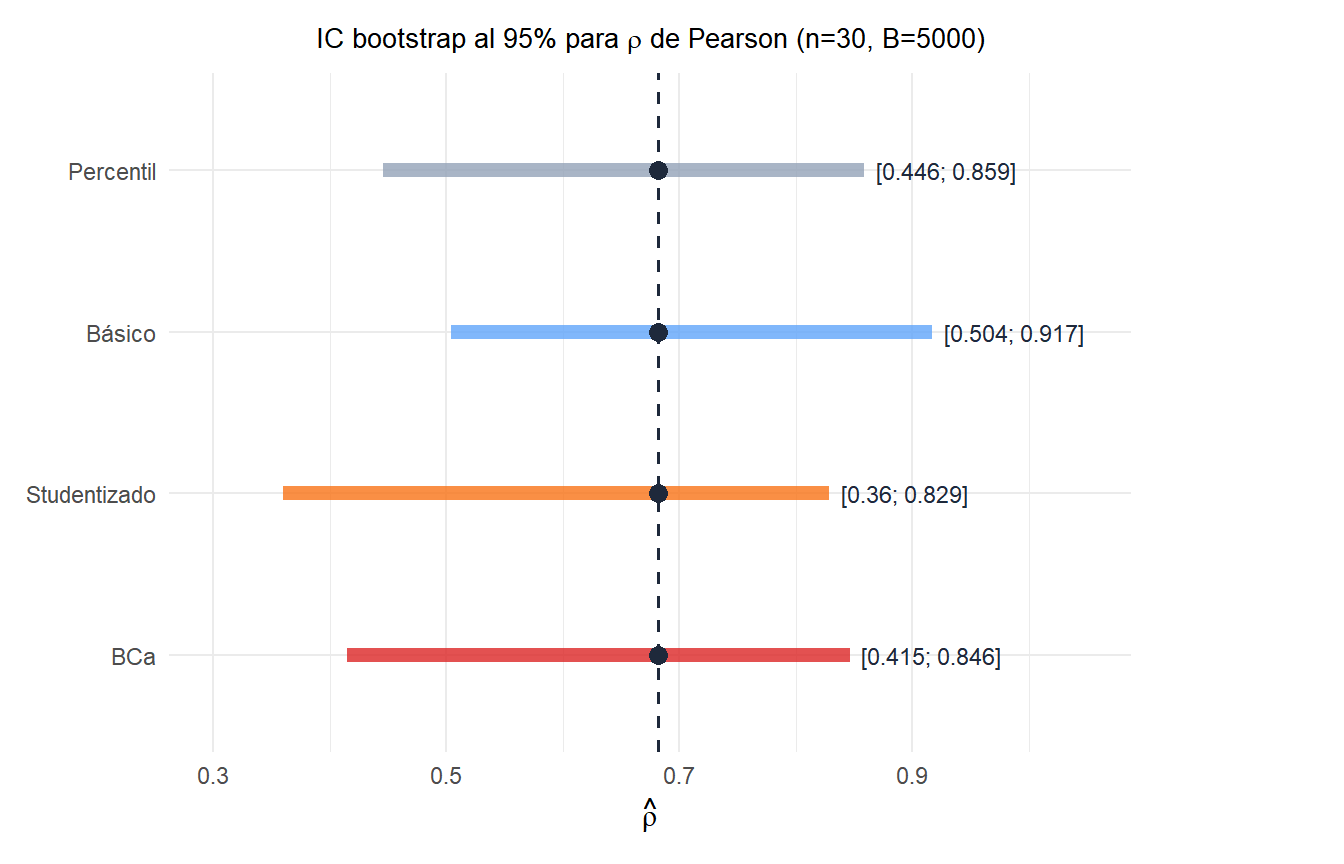
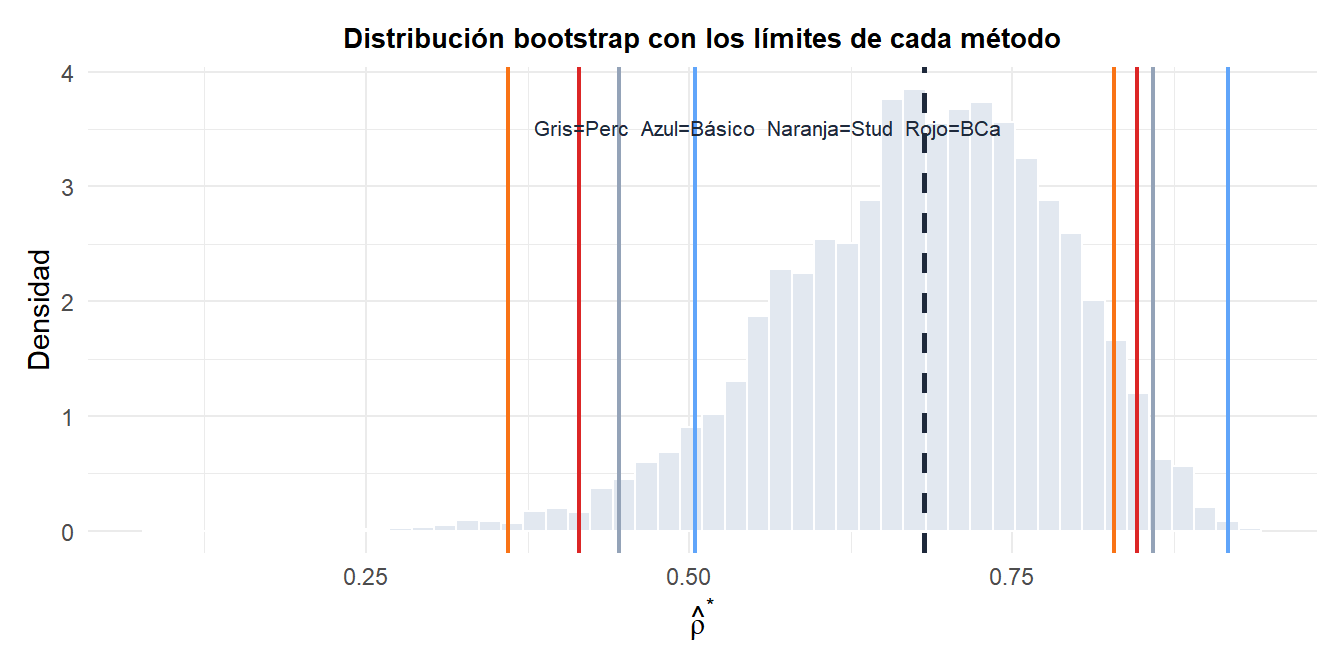
Los cuatro intervalos difieren en posición y amplitud porque hacen correcciones distintas por sesgo y asimetría. Para una correlación próxima al límite (\(\hat{\rho} \approx 0{,}8\)), la distribución está sesgada a la izquierda y el BCa produce el intervalo asimétrico más adecuado.
Qué método usar
| Método | Precisión | Requiere | Mejor para |
|---|---|---|---|
| Percentil | Primer orden | \(B \geq 1000\) | Estimaciones rápidas, distribuciones simétricas |
| Básico | Primer orden | \(B \geq 1000\) | Corrige el sesgo de localización |
| Studentizado | Segundo orden | EE por remuestra | Estadísticos pivotables con EE disponible |
| BCa | Segundo orden | \(B \geq 5000\) + jackknife | Uso general, distribuciones asimétricas |
⚠️ El intervalo percentil puede tener cobertura deficiente para estadísticos sesgados o asimétricos
El intervalo percentil asume que la distribución bootstrap tiene la misma forma que la verdadera distribución muestral. Cuando \(\hat{\theta}\) está sesgado o su distribución es asimétrica (habitual para estadísticos acotados como correlaciones, proporciones y varianzas), el intervalo percentil tiene una cobertura real inferior al nivel nominal.
Para correlaciones próximas a \(\pm 1\), varianzas y otros parámetros acotados, usa siempre BCa en lugar de percentil. Para la media muestral a partir de una distribución simétrica, los cuatro métodos dan resultados similares.
💡 IC bootstrap en R con el paquete boot
library(boot)
stat_fn <- function(data, idx) median(data[idx])
boot_obj <- boot(x, stat_fn, R = 5000)
# Los cuatro intervalos a la vez
boot.ci(boot_obj, conf = 0.95,
type = c("perc", "basic", "stud", "bca"))Para el intervalo studentizado, la función statistic debe devolver un vector c(estimación, varianza). Para el BCa, se recomienda al menos \(B = 2000\); \(B = 5000\) para estabilidad en las colas.

