Bootstrap suavizado
El bootstrap suavizado sustituye la distribución empírica discreta \(\hat{F}_n\) por una estimación continua de densidad por núcleo \(\hat{f}_h\) antes de remuestrear. En lugar de extraer de los puntos de datos originales, extrae de una versión suavizada de los datos. Esto reduce el sesgo de discretización del bootstrap uniforme, especialmente para muestras pequeñas y estadísticos que dependen de la continuidad de la distribución.
Motivación: el problema de la discretización
El bootstrap uniforme (naive) remuestrea de \(\hat{F}_n\), que concentra masa de probabilidad \(1/n\) en cada valor observado. Para datos continuos, esto es una aproximación discreta de una distribución continua. La consecuencia: la distribución bootstrap también es discreta, lo que puede llevar a:
- Subestimación de la variabilidad para estadísticos sensibles a la forma de la distribución (cuantiles, densidades).
- Valores idénticos repetidos en las remuestras, que pueden distorsionar las estimaciones del rango o los extremos.
- Distribuciones bootstrap irregulares con picos en los valores observados.
El bootstrap suavizado distribuye cada punto observado en una pequeña región continua, produciendo una aproximación más suave y realista de la población.
Algoritmo
Cada observación del bootstrap suavizado se genera como:
\[x_i^* = x_{j} + h \cdot \varepsilon_i, \qquad j \sim \text{Uniforme}\{1, \ldots, n\}, \quad \varepsilon_i \sim K\]
donde \(K\) es una función núcleo (habitualmente \(N(0,1)\)) y \(h > 0\) es el ancho de banda. Esto equivale a muestrear de la estimación de densidad por núcleo:
\[\hat{f}_h(x) = \frac{1}{nh} \sum_{i=1}^n K\!\left(\frac{x - x_i}{h}\right)\]
El bootstrap suavizado sustituye \(\hat{F}_n\) (distribución empírica) por \(\hat{F}_h\) (CDF de núcleo). Cuando \(h \to 0\), se reduce al bootstrap uniforme. Cuando \(h \to \infty\), suaviza en exceso y pierde información.
Elección del ancho de banda
El ancho de banda \(h\) controla el equilibrio entre suavidad y fidelidad a los datos:
- Demasiado pequeño (\(h \to 0\)): se reduce al bootstrap uniforme. Sin beneficio de suavizado.
- Demasiado grande: infla artificialmente la variabilidad más allá de lo que los datos respaldan.
Un valor predeterminado habitual es la regla del pulgar de Silverman para núcleos normales:
\[h = 0{,}9 \cdot \min\!\left(S, \frac{\text{IQR}}{1{,}34}\right) \cdot n^{-1/5}\]
Para el bootstrap, el \(h\) óptimo es menor que para la estimación de densidad: en la práctica se usa habitualmente \(h_\text{boot} = h_\text{KDE} / \sqrt{2}\) o \(h_\text{boot} = h_\text{KDE} \cdot n^{-1/10}\).
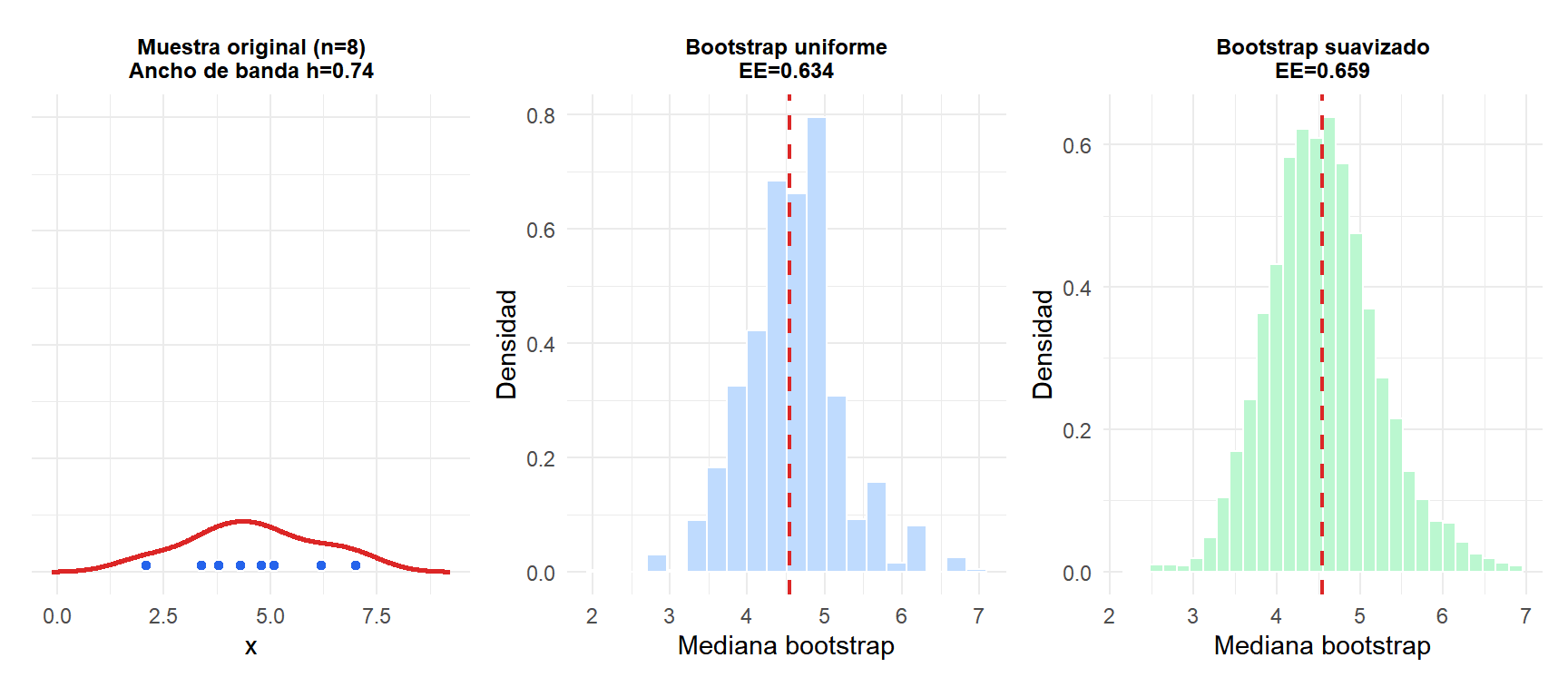
Con solo 8 observaciones, la distribución bootstrap uniforme de la mediana (azul) es visiblemente discreta con picos en los valores observados. El bootstrap suavizado (verde) produce una distribución continua y más suave que representa mejor la incertidumbre subyacente.
Cuándo usar el bootstrap suavizado
El bootstrap suavizado es más beneficioso cuando:
- Muestras pequeñas (\(n < 30\)): la distribución empírica \(\hat{F}_n\) es una mala aproximación de \(F\).
- Estimación de densidades o cuantiles: los estadísticos que dependen de la densidad local de la distribución son sensibles a la discretización.
- Distribución subyacente continua: si los datos provienen de una población continua, el suavizado recupera esa continuidad.
- Reducción de artefactos de discretización: cuando la distribución bootstrap uniforme muestra picos visibles o escalones discretos.
Es menos útil o incluso perjudicial cuando:
- Los datos son verdaderamente discretos (datos de recuento, escalas ordinales): el suavizado distorsiona la discretización natural.
- La muestra es grande: el bootstrap uniforme ya proporciona una buena aproximación.
- El ancho de banda está mal elegido: un suavizado excesivo puede inflar la variabilidad más allá de lo que los datos respaldan.
⚠️ El suavizado no siempre es mejor
Añadir suavizado introduce una nueva fuente de error: la elección del ancho de banda. Si \(h\) es demasiado grande, el bootstrap suavizado genera valores alejados de cualquier dato observado, ensanchando artificialmente la distribución bootstrap. Para muestras grandes donde el bootstrap uniforme funciona bien, el suavizado añade complejidad sin beneficio.
Una guía práctica: usa el bootstrap uniforme por defecto. Cambia al suavizado cuando la distribución bootstrap uniforme muestre picos discretos visibles o cuando estés estimando una densidad continua.
Ejemplo: estimación de un cuantil
El percentil 75 de una distribución continua es un funcional suave de \(F\), pero el cuantil muestral a partir de un conjunto de datos pequeño puede ser errático. El bootstrap suavizado da una estimación más estable.
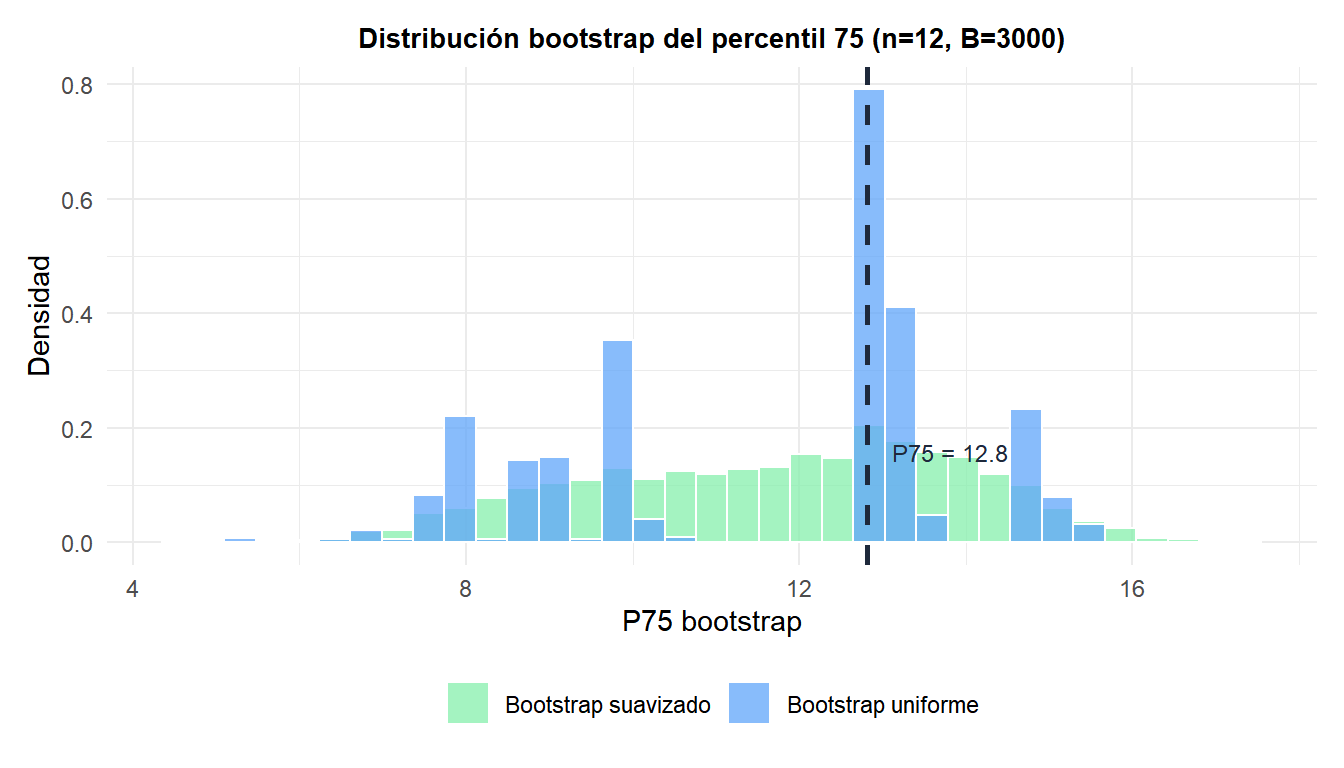
El bootstrap uniforme (azul) concentra la masa en los pocos valores de cuantil distintos posibles con \(n=12\). El bootstrap suavizado (verde) distribuye esta masa de forma continua, proporcionando una imagen más realista de la incertidumbre en la estimación del cuantil.
💡 Bootstrap suavizado en R
El paquete boot no implementa directamente el bootstrap suavizado, pero es sencillo de implementar:
library(boot)
## Definir el estadístico del bootstrap suavizado
smooth_boot_stat <- function(data, indices, h) {
x_resamp <- data[indices] + rnorm(length(indices), 0, h)
median(x_resamp) # o cualquier estadístico
}
h <- 0.9 * min(sd(x), IQR(x)/1.34) * length(x)^(-0.2) / sqrt(2)
boot(data = x, statistic = smooth_boot_stat, R = 2000, h = h)
