Optimización convexa
La optimización convexa es la clase de problemas en los que tanto la función objetivo como el conjunto factible son convexos. Esta única propiedad tiene una consecuencia enorme: todo mínimo local es un mínimo global. Los problemas convexos pueden resolverse de forma fiable y eficiente independientemente de su tamaño, mientras que los problemas no convexos son en general intratables en el peor caso.
Conjuntos convexos
Un conjunto \(\mathcal{C} \subseteq \mathbb{R}^n\) es convexo si el segmento entre cualquier par de puntos de \(\mathcal{C}\) está contenido completamente en \(\mathcal{C}\):
\[x, y \in \mathcal{C} \implies \theta x + (1-\theta)y \in \mathcal{C} \quad \forall \theta \in [0,1]\]
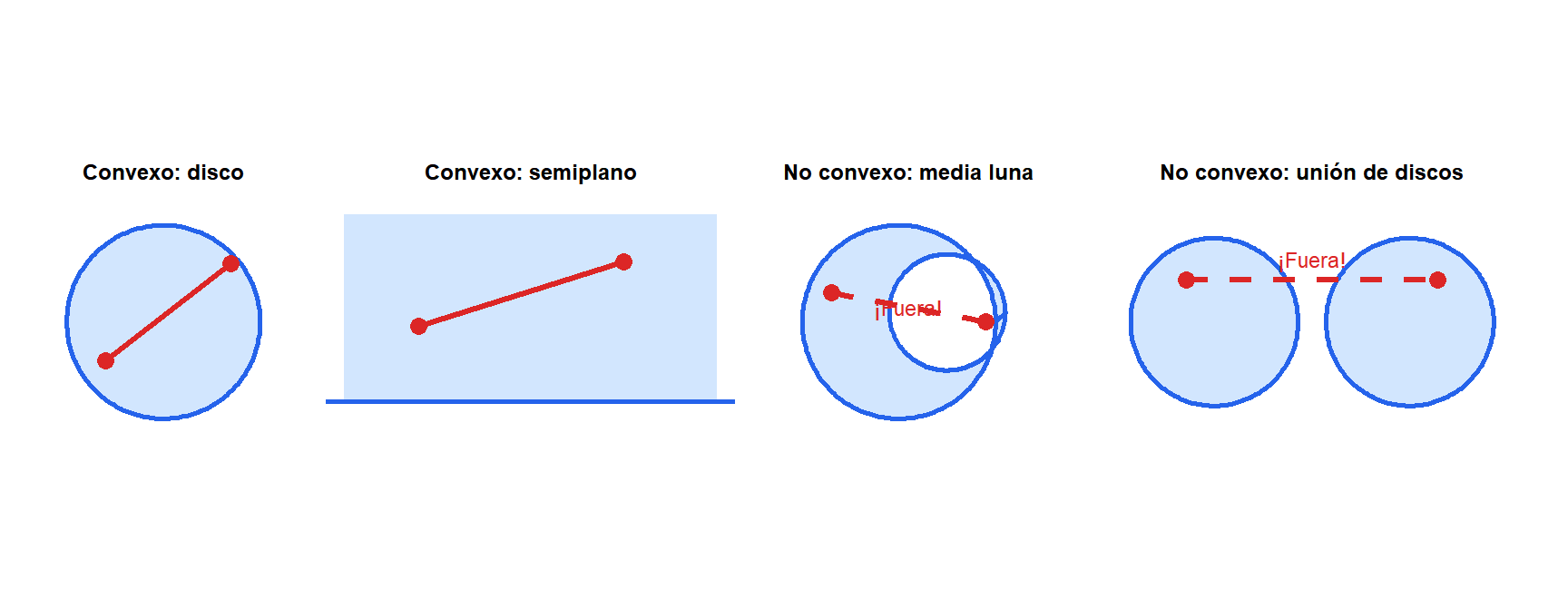
El segmento rojo está contenido completamente en los conjuntos convexos (disco, semiplano), pero sale de los no convexos (media luna, unión de discos). Conjuntos convexos importantes: semiespacios, poliedros (intersecciones de semiespacios), bolas, elipsoides, conos.
Funciones convexas
Una función \(f: \mathbb{R}^n \to \mathbb{R}\) es convexa si su dominio es convexo y:
\[f(\theta x + (1-\theta)y) \leq \theta f(x) + (1-\theta)f(y) \quad \forall x,y,\; \theta \in [0,1]\]
Geométricamente: la cuerda entre dos puntos cualesquiera de la gráfica está por encima de la gráfica (o sobre ella).
Para \(f\) dos veces diferenciable: \(f\) es convexa si y solo si \(\nabla^2 f(x) \succeq 0\) (hessiano semidefinido positivo) en todo punto.
Operaciones que preservan la convexidad: combinaciones lineales no negativas, máximo puntual, composición con funciones afines. Esto permite construir funciones convexas complejas a partir de otras más simples.
Funciones convexas habituales:
- Cuadrática: \(f(x) = x^T Q x + b^T x\) con \(Q \succeq 0\).
- Exponencial: \(e^{ax}\) para cualquier \(a\).
- Potencias: \(|x|^p\) para \(p \geq 1\); \(x^p\) para \(p \geq 1\) con \(x > 0\).
- Normas: \(\|x\|_p\) para \(p \geq 1\).
- Log-sum-exp: \(\log\sum_i e^{x_i}\) (aproximación suave del máximo).
- Entropía negativa: \(\sum_i x_i \log x_i\).
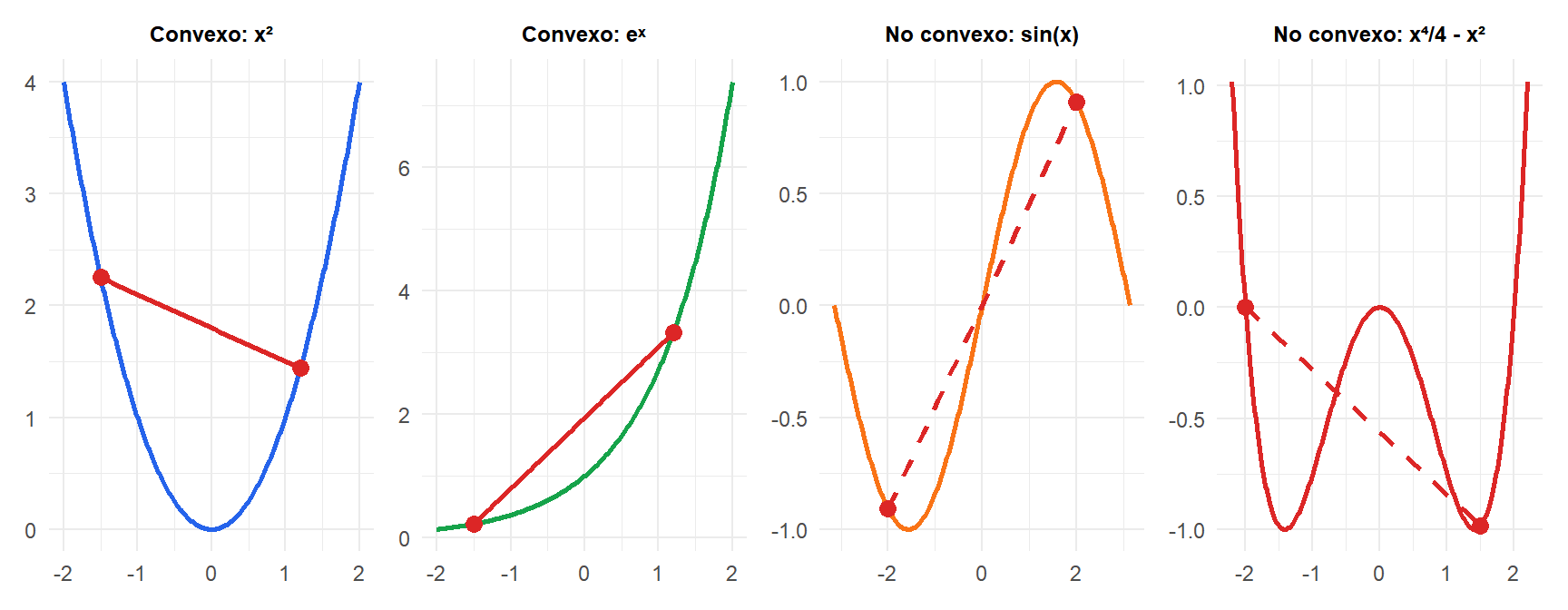
Para las funciones convexas (azul, verde) la cuerda está por encima de la curva. Para las no convexas (naranja, rojo) la cuerda cae por debajo: la definición queda violada.
Problema de optimización convexa en forma estándar
\[\min_{x} f_0(x) \quad \text{s.a.} \quad f_i(x) \leq 0,\; i=1,\ldots,m \quad Ax = b\]
donde \(f_0, f_1, \ldots, f_m\) son todas convexas y las restricciones de igualdad son afines. El conjunto factible \(\{x : f_i(x) \leq 0,\; Ax = b\}\) es convexo (intersección de conjuntos convexos).
El teorema fundamental de la optimización convexa: cualquier mínimo local de un problema convexo es un mínimo global. Si \(f_0\) es estrictamente convexa, el mínimo global es único.
Esta es la propiedad que hace tratable la optimización convexa: no hay que preocuparse por quedar atrapado en mínimos locales. Cualquier algoritmo de descenso encontrará el óptimo global.
Jerarquía de clases de problemas convexos
La optimización convexa engloba una jerarquía de clases de problemas cada vez más generales, cada una con solvers especializados:
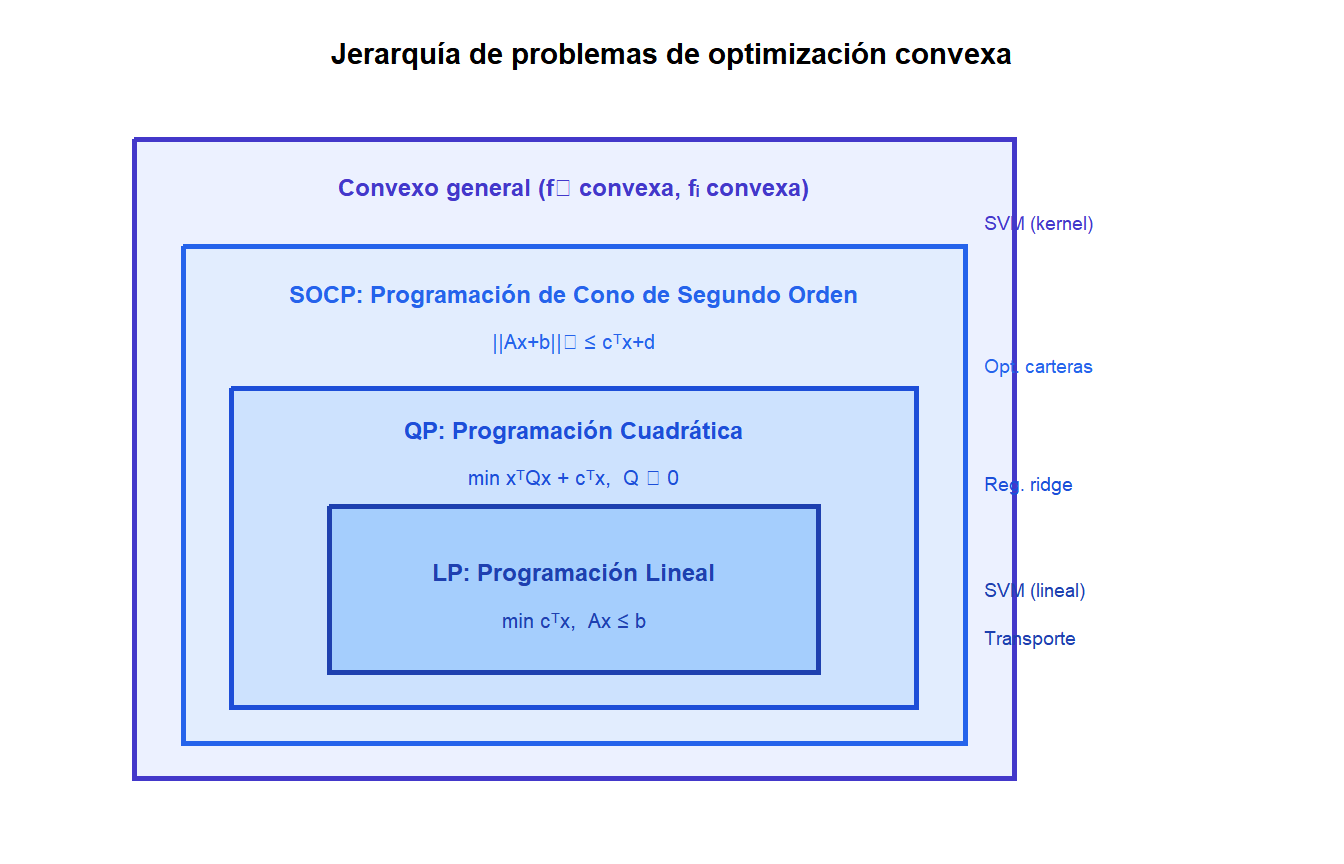
Cada clase es un caso especial de la anterior. Existen solvers especializados para cada nivel: el método Simplex para LP, conjuntos activos o punto interior para QP, solvers SOCP para restricciones de cono de segundo orden.
Dualidad de Lagrange y dualidad fuerte
Para cualquier problema de optimización (convexo o no), el problema dual de Lagrange es:
\[\max_{\lambda \geq 0,\, \nu} g(\lambda, \nu), \qquad g(\lambda, \nu) = \inf_x \mathcal{L}(x, \lambda, \nu) = \inf_x \left[f_0(x) + \sum_i \lambda_i f_i(x) + \nu^T(Ax-b)\right]\]
La función dual \(g(\lambda, \nu)\) es siempre cóncava (incluso si el primal es no convexo) y proporciona una cota inferior sobre el valor óptimo primal \(p^*\):
\[g(\lambda, \nu) \leq p^* \quad \forall \lambda \geq 0, \nu\]
La diferencia \(p^* - g(\lambda^*, \nu^*)\) es el gap de dualidad.
Dualidad débil: \(d^* \leq p^*\) siempre. Dualidad fuerte: \(d^* = p^*\) (gap nulo). La dualidad fuerte se cumple para problemas convexos bajo la condición de Slater: existe un punto estrictamente factible \(\hat{x}\) con \(f_i(\hat{x}) < 0\) para todas las restricciones de desigualdad.
Bajo dualidad fuerte, las condiciones KKT son necesarias y suficientes para la optimalidad. Resolver el dual es a veces más sencillo que el primal: el dual de la SVM es un programa cuadrático que da lugar de forma natural al kernel trick y a soluciones dispersas.
⚠️ Lo que importa es la convexidad del problema, no solo de la función
Una función objetivo convexa con restricciones no convexas no da un problema convexo. El conjunto factible también debe ser convexo. Las restricciones no convexas (por ejemplo, \(\|x\|_0 \leq k\) para dispersión, \(x \in \{0,1\}^n\) para programas enteros) hacen el problema no convexo aunque \(f_0\) sea cuadrática.
Situaciones habituales que rompen la convexidad a pesar de una función objetivo de apariencia convexa:
- Restricciones de igualdad no afines: \(\|x\| = 1\) (esfera).
- Restricciones de cardinalidad: como máximo \(k\) entradas no nulas.
- Variables enteras o binarias.
- Restricciones de rango sobre matrices.
Para estos problemas, las relajaciones convexas (sustituir variables enteras por continuas, sustituir el rango por la norma nuclear) suelen proporcionar cotas útiles o soluciones aproximadas.
Condiciones KKT para problemas convexos
Para problemas convexos que satisfacen la condición de Slater, las condiciones KKT son necesarias y suficientes para la optimalidad global. Un punto \(x^*\) es el óptimo global si y solo si existen \(\lambda^* \geq 0\) y \(\nu^*\) tales que:
- Factibilidad primal: \(f_i(x^*) \leq 0\), \(Ax^* = b\).
- Factibilidad dual: \(\lambda_i^* \geq 0\).
- Holgura complementaria: \(\lambda_i^* f_i(x^*) = 0\).
- Estacionariedad: \(\nabla f_0(x^*) + \sum_i \lambda_i^* \nabla f_i(x^*) + A^T\nu^* = 0\).
Este es el resultado limpio de las KKT: para problemas no convexos, las KKT son solo necesarias. Para problemas convexos bajo la condición de Slater, caracterizan el óptimo global de forma completa.
💡 Optimización convexa en R
library(CVXR)
# Lasso (mínimos cuadrados con regularización L1): convexo pero no suave
n <- 50; p <- 20
X <- matrix(rnorm(n*p), n, p)
y <- rnorm(n)
beta <- Variable(p)
lambda <- 0.1
prob <- Problem(Minimize(sum_squares(X %*% beta - y) + lambda*sum(abs(beta))))
solve(prob)
beta$value
# Optimización de carteras: minimizar varianza sujeto a restricción de rendimiento
w <- Variable(p, nonneg=TRUE) # pesos >= 0
Sigma <- cov(matrix(rnorm(n*p), n, p)) # matriz de covarianza
mu <- rnorm(p, 0.05, 0.02) # rendimientos esperados
target_return <- 0.04
prob <- Problem(Minimize(quad_form(w, Sigma)),
list(sum(w) == 1,
t(mu) %*% w >= target_return))
solve(prob)
# Programa lineal
c_obj <- c(5, 4)
A_mat <- rbind(c(1,2), c(2,1))
b_rhs <- c(8, 10)
x <- Variable(2, nonneg=TRUE)
prob <- Problem(Maximize(t(c_obj) %*% x),
list(A_mat %*% x <= b_rhs))
solve(prob)CVXR comprueba automáticamente si los problemas son convexos (usando reglas de programación convexa disciplinada) y llama al solver adecuado (ECOS, SCS, MOSEK).

