Método Simplex
El método Simplex, desarrollado por George Dantzig en 1947, resuelve programas lineales aprovechando que la solución óptima siempre se encuentra en un vértice del politopo factible. Se desplaza de vértice en vértice por las aristas, mejorando siempre la función objetivo, hasta que no existe ningún vértice vecino que mejore el resultado.
Idea clave
Un programa lineal con \(n\) variables y \(m\) restricciones (en forma estándar, tras añadir \(m\) variables de holgura) tiene como máximo \(\binom{n+m}{m}\) vértices. El método Simplex no los evalúa todos: parte de un vértice y en cada iteración se mueve al vértice adyacente que mejora el objetivo. En la práctica termina en \(O(m)\) a \(O(2m)\) pivotes para la mayoría de problemas reales.
Cada vértice corresponde a una solución factible básica (SFB): una solución donde exactamente \(m\) variables son distintas de cero (las variables básicas) y las \(n\) restantes son cero (las variables no básicas). Restringir la atención a los vértices reduce un espacio de búsqueda infinito a uno finito.
Forma estándar y el tableau inicial
Cualquier PL con restricciones de desigualdad se convierte primero a forma estándar añadiendo variables de holgura. Para un problema de maximización \(\max z = \mathbf{c}^T x\) sujeto a \(\mathbf{A}x \leq \mathbf{b}\), \(x \geq 0\):
\[\mathbf{A}x + s = \mathbf{b}, \qquad x \geq 0,\; s \geq 0\]
Las variables de holgura \(s_i\) absorben la holgura en cada desigualdad. La SFB inicial es \(x = 0\), \(s = \mathbf{b}\), \(z = 0\): se empieza en el origen con todas las holguras en la base.
El tableau del Simplex organiza el sistema:
\[\begin{array}{c|ccccc|c} \text{Base} & x_1 & x_2 & \cdots & s_1 & s_2 & \text{LD} \\\hline s_1 & a_{11} & a_{12} & \cdots & 1 & 0 & b_1 \\ s_2 & a_{21} & a_{22} & \cdots & 0 & 1 & b_2 \\\hline -z & -c_1 & -c_2 & \cdots & 0 & 0 & 0 \end{array}\]
La fila del objetivo almacena \(-\mathbf{c}^T\) (negativo porque escribimos \(-z + \mathbf{c}^T x = 0\) y seguimos las mejoras llevando \(-z\) hacia su valor más negativo, es decir, maximizando \(z\)).
El algoritmo: tres reglas
Regla 1: variable entrante (coeficiente más negativo)
Se recorre la fila del objetivo. La variable no básica con el coeficiente más negativo entra en la base: llevarla de cero a un valor positivo aumentará \(z\) lo más rápido posible. Si todos los coeficientes son \(\geq 0\), la SFB actual es óptima.
Regla 2: variable saliente (test de la razón mínima)
Para la columna entrante, se calcula la razón \(b_i / a_{i,\text{entr}}\) para cada fila \(i\) donde \(a_{i,\text{entr}} > 0\). La variable básica de la fila con la razón más pequeña sale de la base. Esta razón es cuánto puede aumentar la variable entrante antes de que la variable básica actual en esa fila llegue a cero. Tomar el mínimo garantiza que se mantiene la factibilidad.
Si ninguna razón es positiva (todos los \(a_{i,\text{entr}} \leq 0\)), el PL es no acotado: la variable entrante puede crecer sin límite.
Regla 3: operación de pivote
El elemento en la intersección de la columna entrante y la fila saliente es el elemento pivote. Se divide la fila pivote entre el elemento pivote para que el pivote valga 1. Después se usan operaciones de fila para eliminar la variable entrante de todas las demás filas, incluida la fila del objetivo. Se actualiza la etiqueta de la base.
Se repite hasta que se cumple la condición de optimalidad.
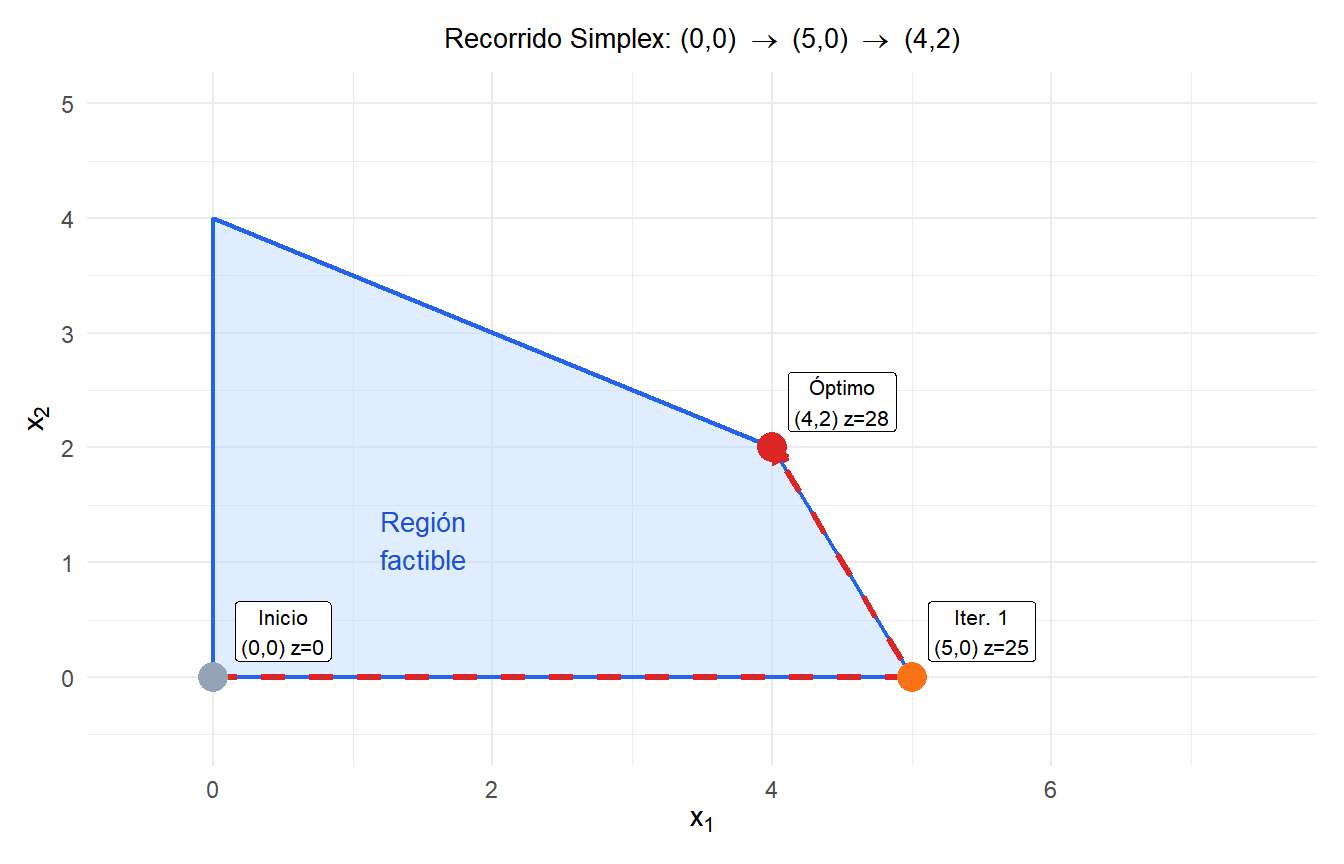
Ejemplo completo: dos iteraciones
Maximizar \(z = 5x_1 + 4x_2\) sujeto a:
\[x_1 + 2x_2 \leq 8, \qquad 2x_1 + x_2 \leq 10, \qquad x_1, x_2 \geq 0\]
Tableau inicial (SFB: \(x_1=x_2=0\), \(s_1=8\), \(s_2=10\), \(z=0\)):
\[\begin{array}{c|cccc|c} \text{Base} & x_1 & x_2 & s_1 & s_2 & \text{LD} \\\hline s_1 & 1 & 2 & 1 & 0 & 8 \\ s_2 & \mathbf{2} & 1 & 0 & 1 & 10 \\\hline -z & -5 & -4 & 0 & 0 & 0 \end{array}\]
Iteración 1:
Entrante: \(x_1\) (más negativo: \(-5\)). Razones: \(8/1 = 8\), \(10/2 = 5\). El mínimo es 5, así que \(s_2\) sale. Elemento pivote: 2 (fila 2, columna \(x_1\)).
Se divide la fila 2 entre 2. Se elimina \(x_1\) de la fila 1 (restando \(1 \times\) la nueva fila 2) y de la fila del objetivo (sumando \(5 \times\) la nueva fila 2):
\[\begin{array}{c|cccc|c} \text{Base} & x_1 & x_2 & s_1 & s_2 & \text{LD} \\\hline s_1 & 0 & \mathbf{1{,}5} & 1 & -0{,}5 & 3 \\ x_1 & 1 & 0{,}5 & 0 & 0{,}5 & 5 \\\hline -z & 0 & -1{,}5 & 0 & 2{,}5 & 25 \end{array}\]
SFB: \(x_1=5\), \(x_2=0\), \(s_1=3\), \(z=25\). Coeficiente del objetivo \(-1{,}5 < 0\): todavía no es óptimo.
Iteración 2:
Entrante: \(x_2\) (único negativo: \(-1{,}5\)). Razones: \(3/1{,}5 = 2\), \(5/0{,}5 = 10\). El mínimo es 2, así que \(s_1\) sale. Elemento pivote: 1,5.
Se divide la fila 1 entre 1,5. Se elimina \(x_2\) de la fila 2 y de la fila del objetivo:
\[\begin{array}{c|cccc|c} \text{Base} & x_1 & x_2 & s_1 & s_2 & \text{LD} \\\hline x_2 & 0 & 1 & 2/3 & -1/3 & 2 \\ x_1 & 1 & 0 & -1/3 & 2/3 & 4 \\\hline -z & 0 & 0 & 1 & 2 & 28 \end{array}\]
Todos los coeficientes del objetivo \(\geq 0\). Solución óptima: \(x_1 = 4\), \(x_2 = 2\), \(z = 28\).
Encontrar una SFB inicial: el método de la M grande
El origen (\(x = 0\), \(s = \mathbf{b}\)) es una SFB inicial válida solo cuando todos los \(b_i \geq 0\). Si algunas restricciones son de tipo \(\geq\) o \(=\), las variables de holgura solas no dan una SFB. El método de la M grande añade variables artificiales \(a_i \geq 0\) a esas filas y las penaliza fuertemente en el objetivo:
\[\max z = \mathbf{c}^T x - M \sum_i a_i\]
donde \(M\) es un número muy grande. La SFB inicial usa las variables artificiales como base. Si el PL es factible, el Simplex llevará todos los \(a_i\) a cero. Si algún \(a_i > 0\) en el óptimo, el PL original es infactible.
Maximizar \(z = 3x_1 + 2x_2\) sujeto a \(x_1 + x_2 = 4\), \(x_1, x_2 \geq 0\).
La restricción de igualdad no tiene variable de holgura. Se añade la variable artificial \(a_1\):
\[\max z = 3x_1 + 2x_2 - M a_1 \qquad x_1 + x_2 + a_1 = 4, \quad a_1 \geq 0\]
SFB inicial: \(x_1 = x_2 = 0\), \(a_1 = 4\). El Simplex pivoteará \(a_1\) fuera de la base y encontrará el óptimo \(x_1 = 4\), \(x_2 = 0\), \(z = 12\).
Una alternativa es el método de las dos fases: la Fase I minimiza \(\sum a_i\) para encontrar una SFB factible (ignorando el objetivo original); la Fase II optimiza el objetivo original partiendo de esa SFB.
Precios sombra y análisis de sensibilidad
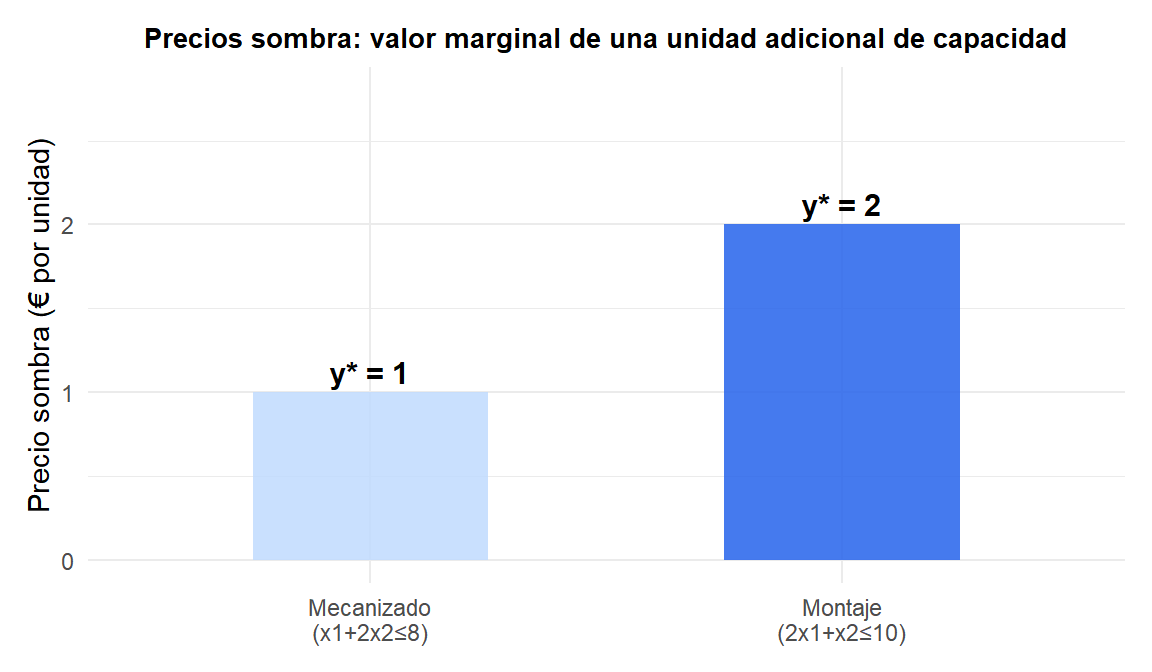
El tableau final contiene más información que solo la solución óptima. Los coeficientes de la fila del objetivo para las variables de holgura son los precios sombra (variables duales) \(y_i^*\): miden cuánto aumenta \(z\) por cada unidad de aumento en el lado derecho \(b_i\).
Del tableau final anterior: el coeficiente de \(s_1\) es 1 y el de \(s_2\) es 2. Por tanto:
- Relajar la restricción 1 (\(x_1 + 2x_2 \leq 8\)) en 1 unidad aumenta el óptimo de \(z\) en 1 €.
- Relajar la restricción 2 (\(2x_1 + x_2 \leq 10\)) en 1 unidad aumenta el óptimo de \(z\) en 2 €.
La restricción 2 (montaje) es más valiosa: añadir una hora de capacidad de montaje vale el doble que añadir una hora de mecanizado.
Los precios sombra solo son válidos dentro de un rango de cambios en \(b_i\) (el análisis de rango del lado derecho). Más allá de ese rango, la base óptima cambia y se necesita una nueva ejecución del Simplex.
Degeneración y ciclado
Una SFB es degenerada si una o más variables básicas valen cero. En un vértice degenerado, un pivote puede dejar el valor del objetivo sin cambios (pivote degenerado). En casos raros esto provoca ciclado: el algoritmo revisita la misma SFB repetidamente sin terminar.
La regla de Bland evita el ciclado: entre todas las variables entrantes elegibles, se elige la de índice más pequeño; entre las salientes elegibles, también la de índice más pequeño. Esto garantiza la terminación a costa de una convergencia posiblemente más lenta. En la práctica, el ciclado es extremadamente raro y la mayoría de implementaciones usan métodos de perturbación.
Simplex vs métodos de punto interior
| Simplex | Punto interior (Karmarkar) | |
|---|---|---|
| Recorrido | Por vértices y aristas | Por el interior de la región factible |
| Complejidad en el peor caso | Exponencial | Polinomial |
| Rendimiento práctico | Muy rápido (normalmente \(O(m)\) pivotes) | Competitivo para PL muy grandes |
| Warm starting | Sencillo (reutilizar base) | Más difícil |
| Análisis de sensibilidad | Directo desde el tableau final | Requiere cálculo adicional |
| Ideal para | PL medianos, reoptimización, ramificación y poda en MIP | PL muy grandes (\(> 10^6\) variables) |
Los solvers modernos (Gurobi, CPLEX, HiGHS) implementan ambos y cambian automáticamente según el tamaño y la estructura del problema.
⚠️ El Simplex puede ser exponencialmente lento con entradas adversariales
Klee y Minty (1972) construyeron una familia de PL con \(n\) variables donde el Simplex estándar visita los \(2^n\) vértices. El problema parece un hipercubo distorsionado. Sin embargo, estas entradas adversariales no aparecen nunca en aplicaciones reales. Para problemas prácticos, el Simplex es notablemente rápido pese a la garantía del peor caso. Si encuentras una ejecución del Simplex que no termina rápido, sospecha de degeneración o mal escalado antes que de estructura adversarial.
💡 Simplex en R
library(lpSolve)
obj <- c(5, 4)
mat <- matrix(c(1, 2, 2, 1), nrow=2, byrow=TRUE)
rhs <- c(8, 10)
dir <- c("<=", "<=")
sol <- lp("max", obj, mat, dir, rhs, compute.sens=TRUE)
sol$solution # x1=4, x2=2
sol$objval # 28
sol$duals # precios sombra: c(1, 2, 0, 0)
sol$sens.coef.from # límite inferior del rango de coeficientes del objetivo
sol$sens.coef.to # límite superior del rango de coeficientes del objetivoPara problemas más grandes, el solver HiGHS (via el paquete highs) es más rápido y robusto que lpSolve.

