Algoritmos voraces
Un algoritmo voraz toma la elección localmente óptima en cada paso y nunca reconsidera decisiones pasadas. Cuando el problema tiene la propiedad de elección voraz, esta estrategia tan simple produce una solución globalmente óptima. Los algoritmos voraces son más rápidos que la programación dinámica, pero aplicables a una clase más reducida de problemas.
La propiedad de elección voraz
Un problema tiene la propiedad de elección voraz si se puede construir una solución óptima global tomando elecciones localmente óptimas: en cada paso, la mejor opción disponible conduce a una solución óptima sin necesidad de reconsiderar elecciones anteriores.
Esto es más exigente que la subestructura óptima por sí sola (que la programación dinámica requiere). La PD también necesita subproblemas solapados. El enfoque voraz funciona cuando se cumplen:
- Subestructura óptima: la solución óptima del problema completo contiene soluciones óptimas de los subproblemas.
- Propiedad de elección voraz: la elección localmente óptima en cada paso forma siempre parte de alguna solución globalmente óptima.
Cuando se cumplen ambas, el algoritmo voraz es preferible a la PD: más sencillo, más rápido y con menos uso de memoria. Cuando solo se cumple la subestructura óptima pero no la propiedad de elección voraz, se necesita programación dinámica.
Demostrar la corrección de un algoritmo voraz siempre sigue la misma estructura: se asume una solución óptima que difiere de la solución voraz, se introduce la elección voraz mediante un intercambio y se demuestra que el resultado no empeora. Este argumento de intercambio es la técnica de demostración estándar.
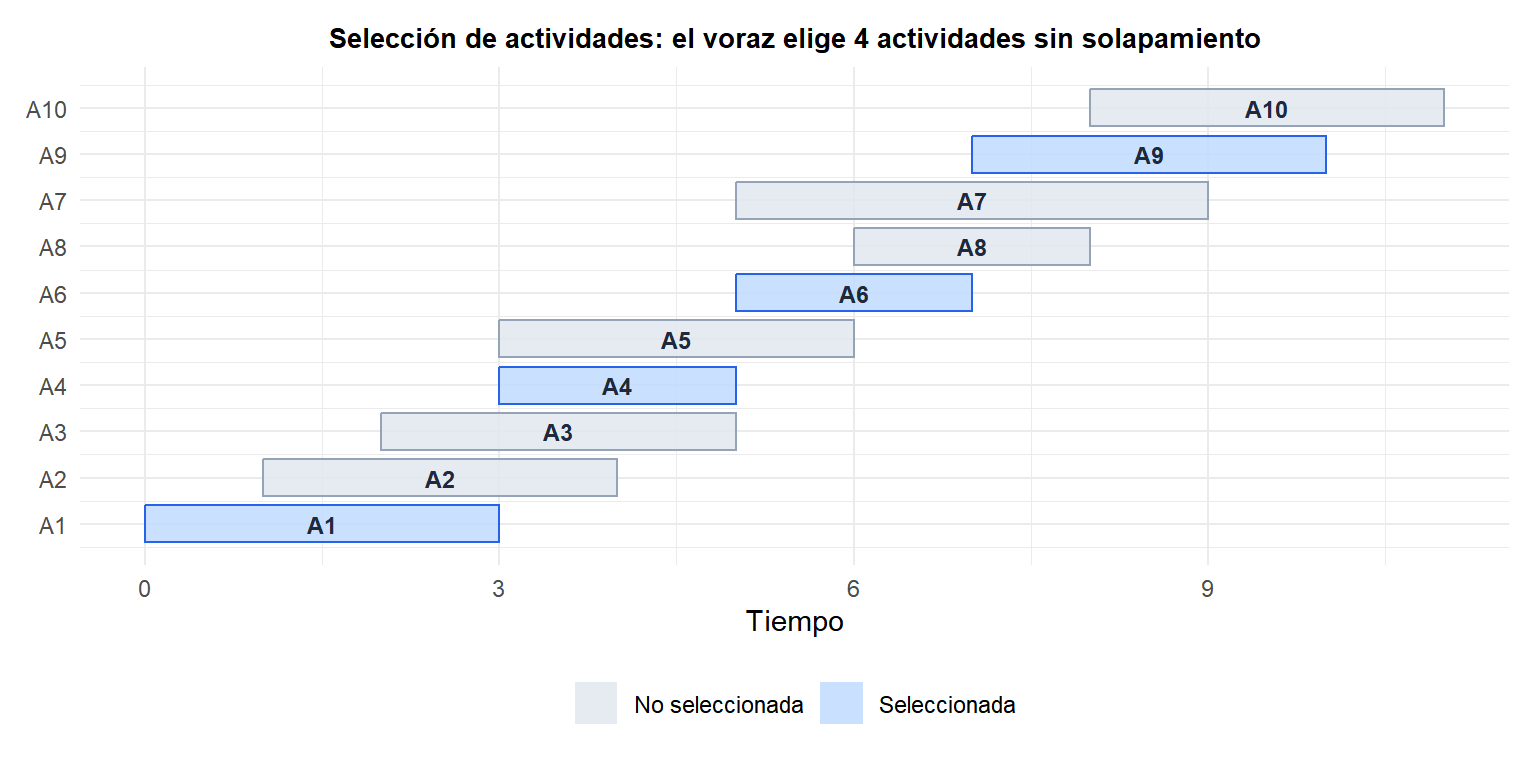
Ejemplo 1: selección de actividades
\(n\) actividades con tiempos de inicio \(s_i\) y fin \(f_i\). Seleccionar el máximo número de actividades sin solapamiento.
Estrategia voraz: elegir siempre la actividad que termina antes entre las compatibles con la selección actual.
Por qué funciona: elegir la actividad que termina antes deja el mayor tiempo restante para las demás actividades. Cualquier solución que omita la actividad de finalización más temprana compatible puede mejorarse intercambiándola (argumento de intercambio).
Algoritmo: ordenar las actividades por tiempo de fin. Recorrerlas de izquierda a derecha; añadir cada actividad si no se solapa con la última seleccionada.
Complejidad: \(O(n \log n)\) para la ordenación, \(O(n)\) para el recorrido.
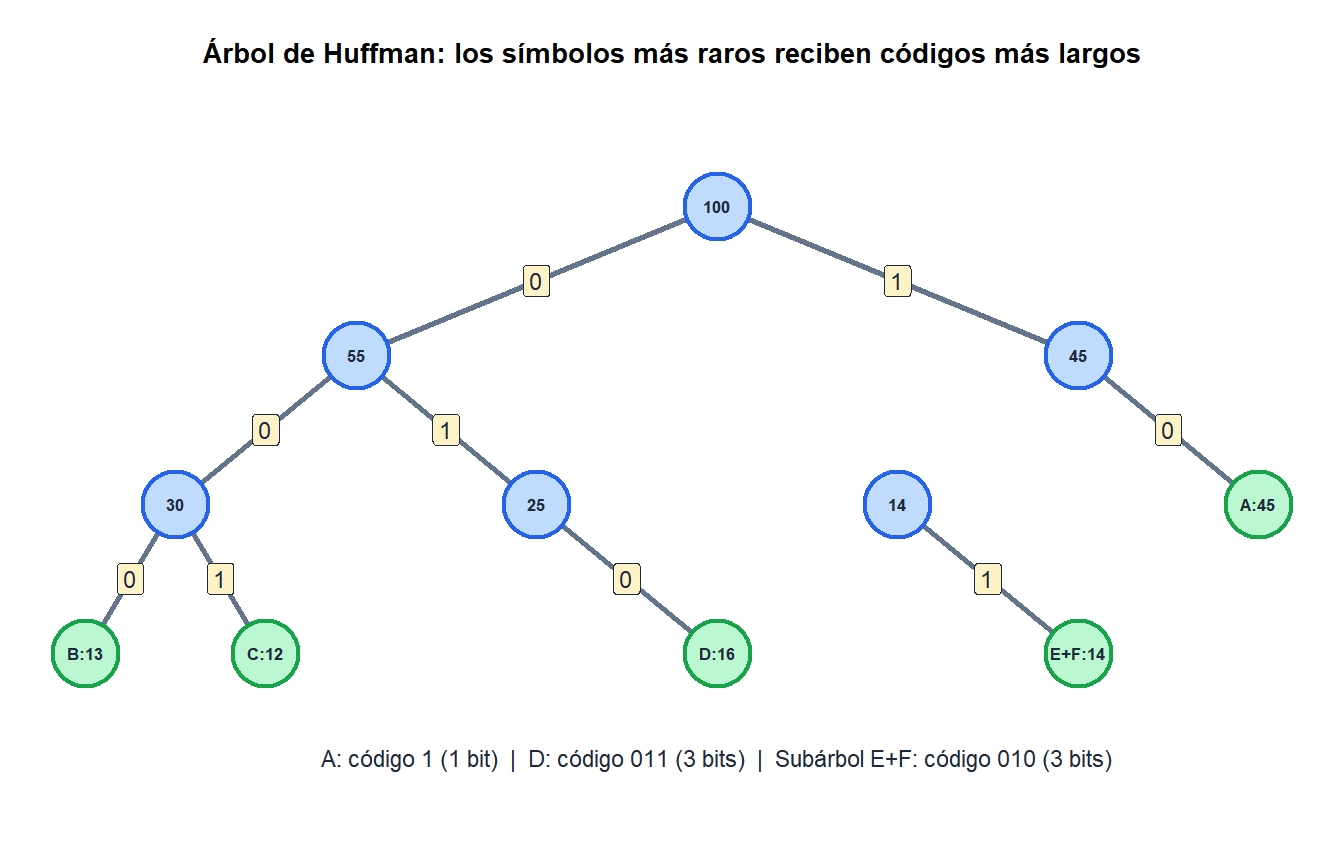
Ejemplo 2: codificación de Huffman
Asignar códigos binarios a \(n\) símbolos con frecuencias \(f_i\) para minimizar la longitud total codificada \(\sum_i f_i \cdot \text{profundidad}(i)\), donde la profundidad es la longitud del código.
Estrategia voraz: fusionar repetidamente los dos símbolos (o subárboles) con las frecuencias más bajas en un nuevo subárbol. La frecuencia del nodo fusionado es la suma de sus dos hijos.
Por qué funciona: los dos símbolos más raros deben estar más profundos en el árbol (códigos más largos), ya que su contribución \(f_i \cdot \text{profundidad}(i)\) a la longitud total se minimiza dándoles los códigos más largos. El argumento de intercambio demuestra que cualquier otra asignación no es mejor.
Resultado: la codificación de Huffman es óptima de forma demostrable entre todos los códigos sin prefijo. Es la base de la compresión DEFLATE (ZIP, PNG, HTTP/2).
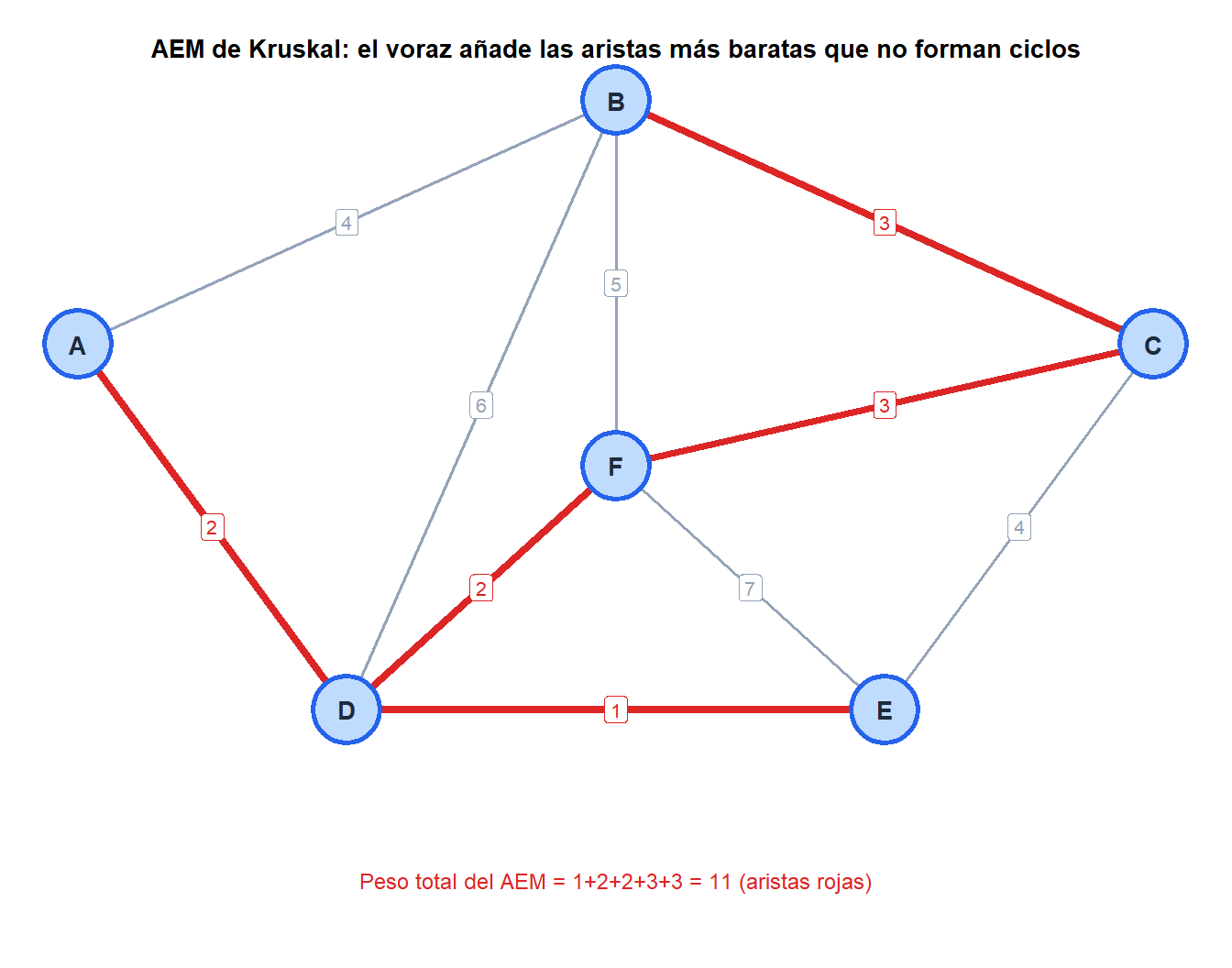
Ejemplo 3: árbol de expansión mínima (algoritmo de Kruskal)
Dado un grafo ponderado conexo, encontrar el árbol de expansión (subgrafo que conecta todos los vértices sin ciclos) de peso total mínimo.
Estrategia voraz de Kruskal: ordenar todas las aristas por peso. Añadir cada arista al árbol de expansión si no forma un ciclo.
Por qué funciona: la propiedad del corte de los árboles de expansión garantiza que la arista de mínimo peso que cruza cualquier corte (partición de vértices en dos conjuntos) es segura para incluir. Cada selección voraz de arista satisface esta propiedad.
Complejidad: \(O(E \log E)\) para la ordenación, casi \(O(E \alpha(V))\) para la detección de ciclos con la estructura Union-Find (\(\alpha\) es la función de Ackermann inversa, efectivamente constante).
Cuándo falla el enfoque voraz
La propiedad de elección voraz no siempre se cumple. El fallo clásico: el problema del cambio de monedas con denominaciones no estándar.
Con monedas \(\{1, 5, 6\}\) y objetivo 10:
- Voraz (moneda más grande primero): \(6 + 1 + 1 + 1 + 1 = 5\) monedas.
- Óptimo (PD): \(5 + 5 = 2\) monedas.
La elección voraz (tomar 6) es localmente óptima pero globalmente subóptima. La programación dinámica encuentra la respuesta correcta.
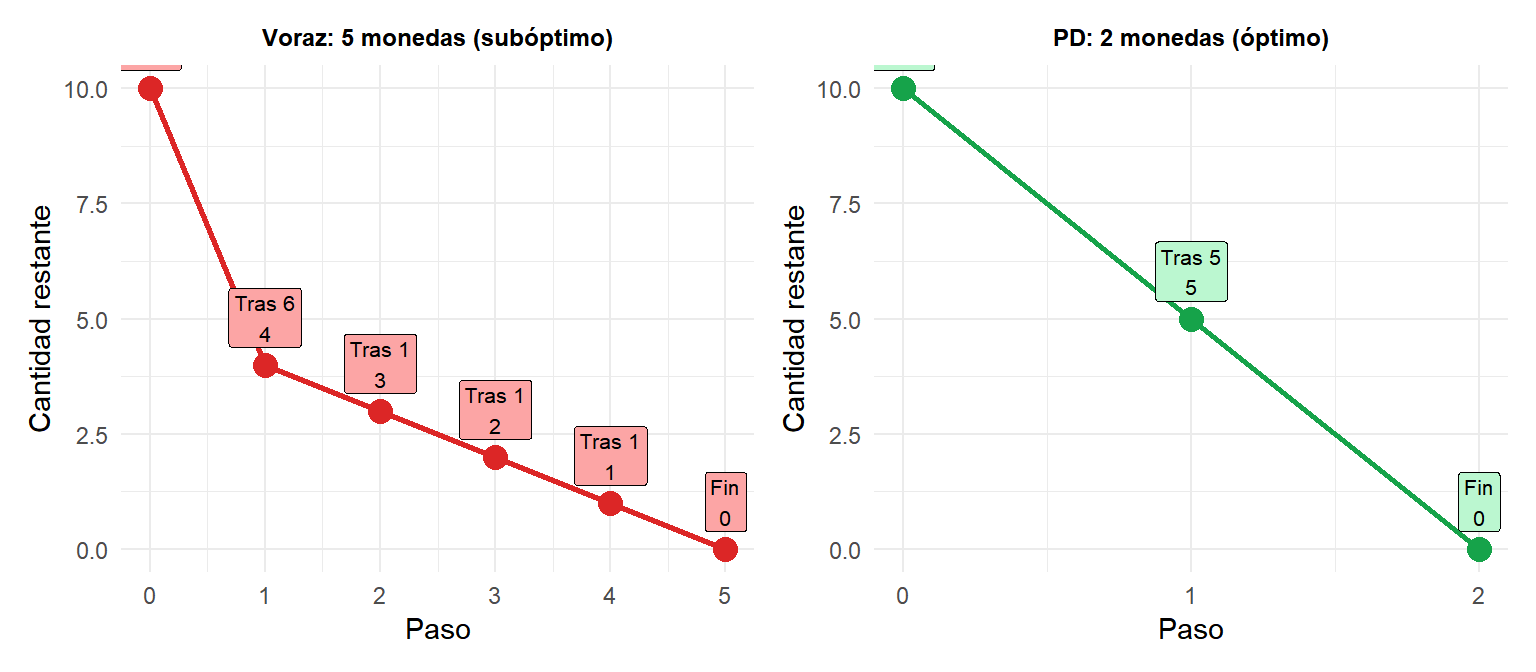
Con monedas \(\{1, 5, 6\}\) y objetivo 10, el voraz usa 5 monedas mientras la PD encuentra el óptimo de 2.
Voraz vs programación dinámica
| Voraz | Programación dinámica | |
|---|---|---|
| Enfoque | Elección óptima local en cada paso | Resolver todos los subproblemas, combinar |
| Reconsideración | Nunca | No (pero considera todas las opciones) |
| Corrección | Solo cuando se cumple la propiedad de elección voraz | Siempre que haya subestructura óptima |
| Complejidad temporal | Normalmente \(O(n \log n)\) o \(O(n)\) | Normalmente \(O(n^k)\) para algún \(k\) |
| Complejidad espacial | \(O(1)\) o \(O(n)\) | Tabla \(O(n^k)\) |
| Ejemplos | Selección de actividades, Huffman, Kruskal, Dijkstra | Mochila, LCS, distancia de edición, TSP |
El enfoque voraz es siempre preferible cuando funciona: más sencillo y más rápido. Se usa programación dinámica cuando el voraz falla por no cumplirse la propiedad de elección voraz.
⚠️ Demostrar la corrección del voraz requiere un argumento de intercambio
Los algoritmos voraces son fáciles de diseñar pero difíciles de demostrar correctos. Nunca hay que asumir que una estrategia voraz funciona solo porque parece intuitiva. Para cada algoritmo voraz hay que demostrar la propiedad de elección voraz: que incluir la elección voraz en la solución no impide encontrar una continuación óptima.
La plantilla de demostración estándar: asumir una solución óptima \(OPT\) que no hace la elección voraz en el paso \(k\). Construir \(OPT'\) introduciendo la elección voraz mediante un intercambio. Demostrar que \(OPT'\) es factible y no peor que \(OPT\). Por tanto, existe una solución óptima que hace la elección voraz y el algoritmo es correcto.
Sin esta demostración, una estrategia voraz plausible puede fallar en entradas específicas, como muestra el ejemplo del cambio de monedas.
💡 Algoritmos voraces en R
# Selección de actividades
activity_selection <- function(start, finish) {
n <- length(start)
idx <- order(finish) # ordenar por tiempo de fin
sel <- idx[1] # elegir siempre el primero
last <- finish[idx[1]]
for (i in 2:n) {
j <- idx[i]
if (start[j] >= last) {
sel <- c(sel, j)
last <- finish[j]
}
}
sel
}
# AEM de Kruskal con igraph
library(igraph)
g <- graph_from_data_frame(
data.frame(from=c("A","A","B","B","B","C","C","D","D","E"),
to =c("B","D","C","D","F","E","F","E","F","F"),
weight=c(4,2,3,6,5,4,3,1,2,7)),
directed=FALSE
)
mst_g <- mst(g, weights=E(g)$weight) # Kruskal internamente
sum(E(mst_g)$weight) # 11
