¿Qué es el muestreo?
El muestreo es el proceso de seleccionar un subconjunto de individuos de una población para estimar las características del conjunto. Es el puente entre la recogida de datos y la inferencia estadística: casi todas las conclusiones en ciencia, medicina y empresa se basan en una muestra, no en un censo completo.
Conceptos clave
- Población
La población es el conjunto completo de individuos, objetos o medidas sobre los que se quieren extraer conclusiones. La define la pregunta de investigación, no la conveniencia.
- La población de interés para un ensayo clínico podría ser “todos los adultos mayores de 18 años con hipertensión en España”.
- Para un estudio de control de calidad: “todas las unidades producidas por la máquina 3 durante el turno de noche”.
- Para una encuesta: “todos los votantes registrados en las próximas elecciones”.
La población suele ser demasiado grande, costosa o imposible de medir en su totalidad.
- Muestra
Una muestra es el subconjunto de la población que se observa realmente. Una buena muestra es:
- Representativa: refleja las características de la población.
- De tamaño adecuado: suficientemente grande para estimar el parámetro con una precisión aceptable.
- Seleccionada mediante un procedimiento definido: de modo que el proceso de selección pueda evaluarse y reproducirse.
- Parámetro vs estadístico
Un parámetro es una característica numérica de la población (generalmente desconocida): \(\mu\), \(\sigma^2\), \(p\). Un estadístico es la cantidad correspondiente calculada a partir de la muestra: \(\bar{x}\), \(S^2\), \(\hat{p}\). La inferencia estadística usa estadísticos para estimar parámetros.
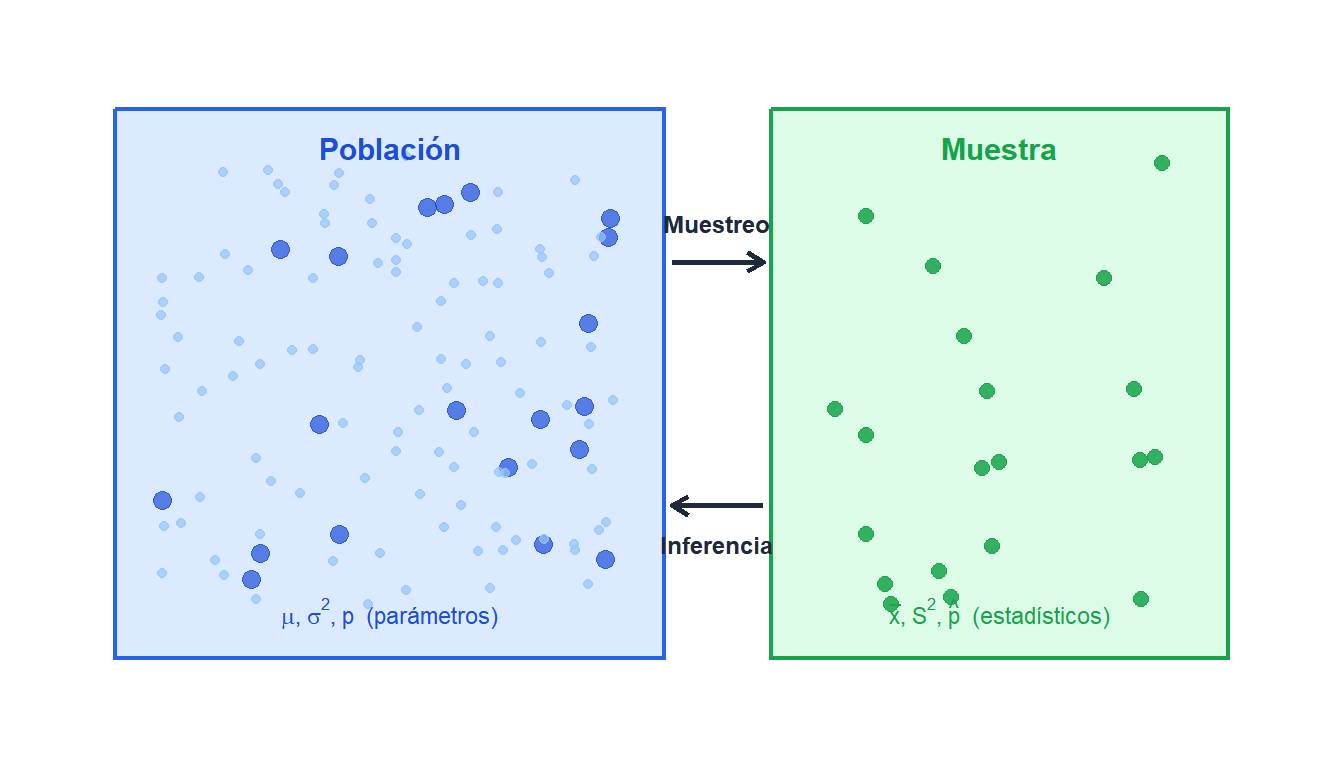
¿Por qué muestrear en lugar de hacer un censo?
Un censo mide todas las unidades de la población. En la mayoría de los casos esto no es práctico:
- Coste y tiempo: entrevistar a todos los votantes de un país, o probar todos los componentes de una producción.
- Pruebas destructivas: medir la resistencia a la rotura de un cable requiere destruirlo. No se puede probar cada unidad.
- Poblaciones infinitas o dinámicas: la población de clientes futuros aún no existe; la de bacterias en un cultivo cambia continuamente.
- Exactitud: una muestra bien diseñada con mediciones cuidadosas puede ser más precisa que un censo mal ejecutado con muchos errores de medición.
Una muestra bien extraída de 1.000 personas puede estimar la opinión de 40 millones de votantes con un margen de error de ±3%.
Muestreo probabilístico vs no probabilístico
La distinción más importante en muestreo es si cada unidad tiene una probabilidad conocida y no nula de ser seleccionada.
Muestreo probabilístico:
- Cada unidad tiene una probabilidad de selección conocida.
- La selección es aleatoria.
- El error muestral puede cuantificarse y controlarse.
- Válido para la inferencia estadística sobre la población.
- Ejemplos: aleatorio simple, sistemático, estratificado, por conglomerados.
Muestreo no probabilístico:
- Las probabilidades de selección son desconocidas.
- Se basa en la conveniencia, el juicio o la respuesta voluntaria.
- El error muestral no puede estimarse formalmente.
- Los resultados pueden no generalizarse a la población.
- Ejemplos: muestreo de conveniencia, muestreo en bola de nieve, muestreo intencional.
⚠️ Las muestras no probabilísticas no permiten inferencia estadística válida
Las muestras de conveniencia (estudiantes de una clase de psicología, voluntarios en línea, seguidores en redes sociales) no son representativas de ninguna población bien definida. Los intervalos de confianza y los p-valores calculados a partir de muestras de conveniencia no tienen interpretación válida, porque las fórmulas asumen muestreo probabilístico. Esto no significa que las muestras de conveniencia sean inútiles: son habituales en la investigación exploratoria, los estudios piloto y el trabajo cualitativo. Pero las conclusiones deben formularse como “entre los participantes de este estudio”, no como generalizaciones a una población.
Error muestral vs sesgo
Dos tipos de problemas pueden afectar a las estimaciones basadas en muestras:
Error muestral
Variación aleatoria debida al hecho de que se mide una muestra, no la población completa. Disminuye al aumentar \(n\) (proporcional a \(1/\sqrt{n}\)). Es inevitable pero cuantificable mediante el error estándar y los intervalos de confianza. Con muestreo probabilístico, puede controlarse eligiendo un \(n\) adecuado.
Sesgo
Error sistemático que empuja las estimaciones de forma consistente en una dirección alejada del verdadero parámetro. A diferencia del error muestral, no disminuye con muestras más grandes: un estudio sesgado de 1.000.000 de personas sigue siendo sesgado.
Fuentes habituales de sesgo:
- Sesgo de selección: ciertas unidades tienen más probabilidad de ser incluidas. Las encuestas en línea atraen a respondentes autoseleccionados que se sienten fuertemente respecto a un tema.
- Sesgo de no respuesta: las unidades que no responden difieren sistemáticamente de las que sí lo hacen. En encuestas de salud, las personas más enfermas pueden tener menos capacidad de participar.
- Sesgo de medición: el instrumento de medida sobreestima o subestima sistemáticamente. Una báscula que marca 2 kg de más produce estimaciones de peso sesgadas independientemente del tamaño muestral.
- Sesgo de supervivencia: solo están disponibles las unidades que han “sobrevivido” algún proceso de selección. Estudiar el rendimiento de las empresas actualmente en funcionamiento ignora las que quebraron.
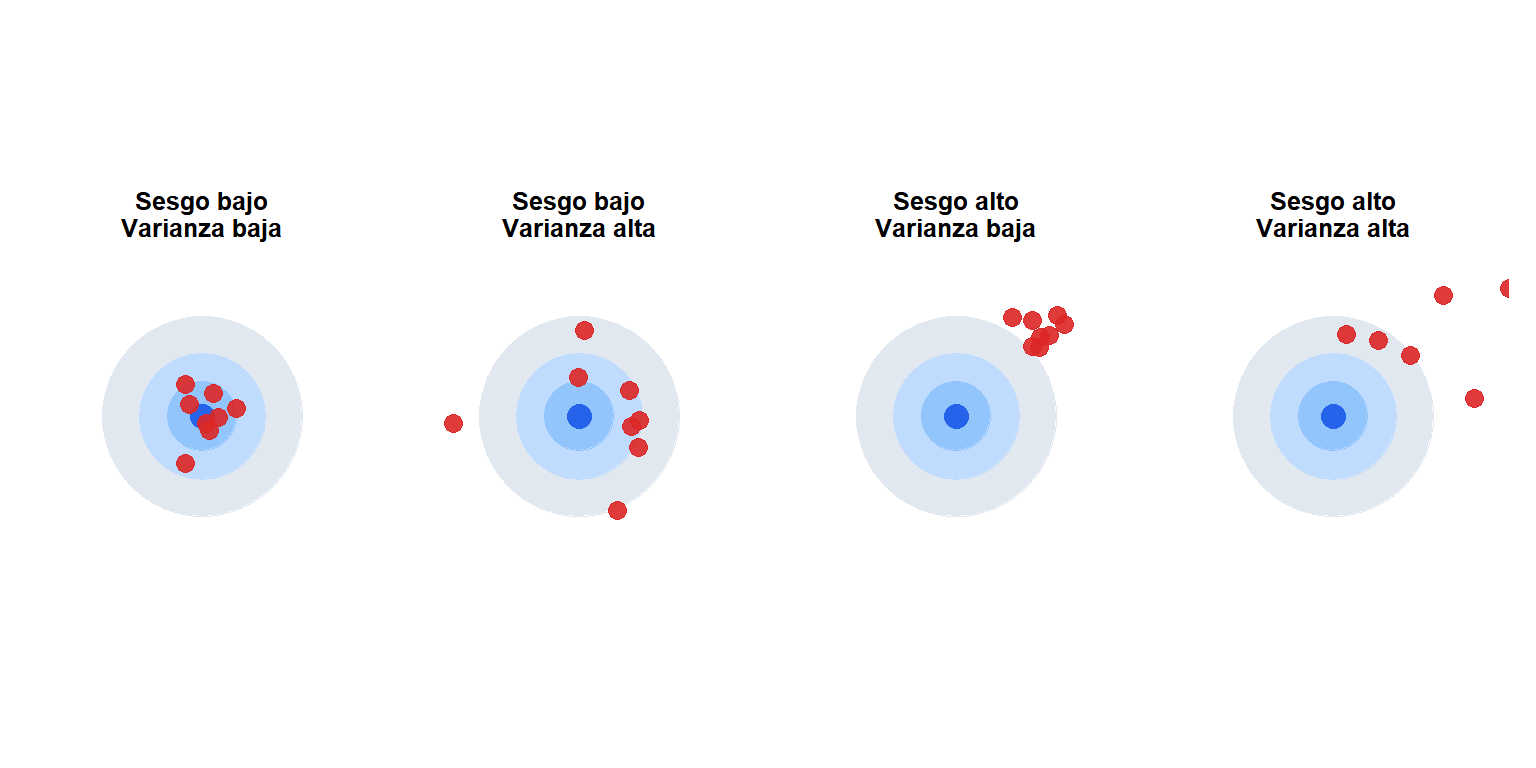
El estimador ideal (arriba a la izquierda) tiene sesgo bajo y varianza baja. Aumentar el tamaño muestral desplaza las estimaciones de varianza alta a varianza baja, pero no corrige el sesgo.
Resumen de los métodos de muestreo
Los siguientes posts de esta sección cubren los principales métodos de muestreo probabilístico:
| Método | Cuándo usarlo | Propiedad clave |
|---|---|---|
| Aleatorio simple | Población homogénea, lista completa disponible | Todas las unidades con igual probabilidad |
| Sistemático | Lista ordenada disponible, sin periodicidad | Se selecciona cada \(k\)-ésima unidad |
| Estratificado | La población tiene subgrupos identificables | Garantiza la representación de cada estrato |
| Por conglomerados | Población agrupada naturalmente, sin lista completa | Se seleccionan grupos y luego unidades dentro |
| Polietápico | Poblaciones grandes y geográficamente dispersas | Selección secuencial de conglomerados y unidades |
💡 La elección del método de muestreo importa
Un método de muestreo mal elegido puede introducir sesgo o ineficiencia incluso con una muestra grande. Preguntas clave antes de elegir el método:
- ¿Está disponible una lista completa de la población (marco muestral)?
- ¿Es la población homogénea o tiene subgrupos identificables?
- ¿Están las unidades concentradas geográficamente o dispersas?
- ¿Cuál es el presupuesto y tiempo disponibles?
El muestreo estratificado es más eficiente que el aleatorio simple cuando la población tiene subgrupos diferenciados. El muestreo por conglomerados es más práctico para poblaciones geográficamente dispersas, pero suele ser menos eficiente por unidad.

