Muestreo sistemático
El muestreo sistemático selecciona cada \(k\)-ésima unidad de una lista ordenada, partiendo de una posición elegida aleatoriamente dentro del primer intervalo. Es más sencillo de aplicar que el muestreo aleatorio simple y puede ser más eficiente cuando la lista está bien ordenada, pero es vulnerable a la periodicidad oculta en la población.
Procedimiento
Dada una población de tamaño \(N\) y una muestra deseada de tamaño \(n\):
Paso 1: calcula el intervalo de muestreo:
\[k = \left\lfloor \frac{N}{n} \right\rfloor\]
Paso 2: elige un punto de inicio aleatorio \(r\) de forma uniforme entre \(\{1, 2, \ldots, k\}\).
Paso 3: selecciona las unidades \(r,\; r+k,\; r+2k,\; \ldots,\; r+(n-1)k\).
Cada unidad tiene probabilidad de selección \(1/k \approx n/N\), por lo que el muestreo sistemático es un método probabilístico. Sin embargo, solo son posibles \(k\) muestras distintas (una por cada punto de inicio), a diferencia del MAS donde son posibles \(\binom{N}{n}\) muestras.

Las unidades seleccionadas (rojas) forman un patrón regular: una por columna. El punto de inicio aleatorio \(r\) determina qué fila se selecciona en cada columna.
Eficiencia frente al MAS
El muestreo sistemático es más eficiente que el MAS cuando la lista está ordenada por la variable de interés, porque la muestra queda automáticamente estratificada a lo largo del ordenamiento. Para una población ordenada por edad, ingresos o tamaño, el muestreo sistemático garantiza que la muestra abarca todo el rango.
La varianza de la media del muestreo sistemático \(\bar{y}_{sys}\) satisface:
\[\text{Var}(\bar{y}_{sys}) \leq \text{Var}(\bar{y}_{MAS})\]
cuando la correlación intraclase dentro de los intervalos es positiva (las unidades dentro del mismo intervalo son similares). En la práctica, cualquier ordenamiento razonable de la lista (alfabético por nombre, cronológico por fecha, secuencial por orden de producción) tiende a hacer el muestreo sistemático al menos tan eficiente como el MAS.
Ejemplo
Un hospital quiere auditar 50 historias clínicas de una base de datos de 500 casos ordenados cronológicamente por fecha de ingreso.
\[k = \lfloor 500/50 \rfloor = 10\]
Se obtiene un número aleatorio entre 1 y 10: supongamos \(r = 4\). Las historias seleccionadas son: 4, 14, 24, 34, …, 494. El equipo de auditoría procesa cada décima historia en orden de ingreso, garantizando cobertura durante todo el año.
Una fábrica produce 8.000 componentes por turno. El equipo de calidad necesita inspeccionar 80 unidades. Intervalo de muestreo: \(k = 8000/80 = 100\). Se obtiene un punto de inicio aleatorio \(r = 37\). Se inspeccionan las unidades 37, 137, 237, …, 7937.
Esto es práctico porque el inspector simplemente cuenta las unidades en la línea en lugar de generar 80 números aleatorios y buscar unidades específicas. El resultado es equivalente al MAS en términos de probabilidad de selección, y el espaciado regular garantiza que los defectos que ocurran en cualquier punto del turno sean detectables.
El problema de la periodicidad
⚠️ La periodicidad en la lista puede sesgar gravemente las muestras sistemáticas
Si la lista tiene una estructura periódica con el mismo período que \(k\), la muestra coincidirá sistemáticamente con la misma fase del ciclo, produciendo una muestra sesgada y no representativa.
Ejemplos clásicos:
- Línea de producción: inspeccionar cada 8.ª unidad cuando la máquina produce una unidad defectuosa cada 8 unidades siempre incluirá o siempre evitará el defecto, según el punto de inicio.
- Programación semanal: si \(k = 7\) y la lista está ordenada por día, todas las unidades seleccionadas caen el mismo día de la semana. Una muestra solo de lunes ignora los efectos del fin de semana.
- Edificios de apartamentos: si \(k = 10\) y los pisos tienen 10 apartamentos numerados secuencialmente, el muestreo sistemático siempre selecciona la misma posición en cada piso (por ejemplo, siempre el apartamento de la esquina).
Detección: representa los valores de la lista frente a su índice antes de muestrear y busca patrones regulares. Si se sospecha periodicidad, usa MAS o muestreo estratificado.
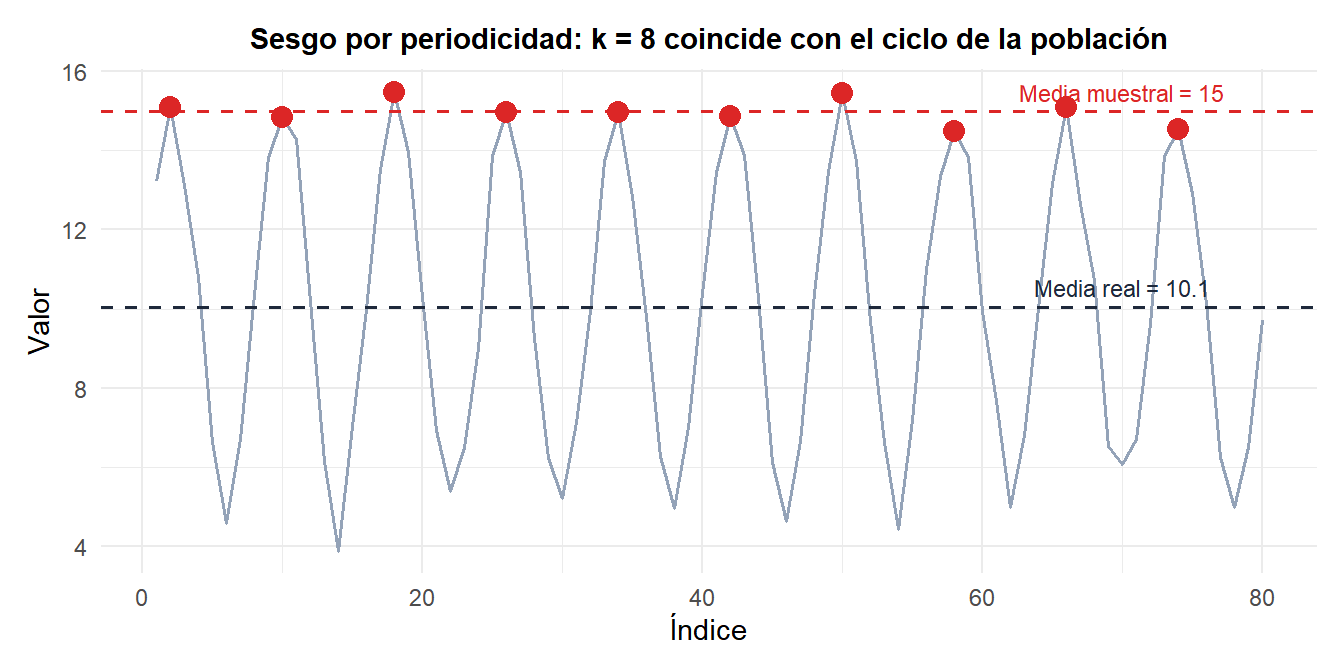
La muestra (puntos rojos) coincide sistemáticamente con los máximos del ciclo, produciendo una media muestral muy superior a la verdadera media poblacional.
Ventajas y limitaciones
El muestreo sistemático se usa ampliamente porque es fácil de aplicar y a menudo tan eficiente como el MAS. Sus principales ventajas son prácticas: no hay que generar muchos números aleatorios, es sencillo de ejecutar sobre el terreno y garantiza una distribución uniforme a lo largo de la lista. La principal limitación es el riesgo de periodicidad, que es fácil de detectar y evitar con una rápida inspección visual de la lista.
💡 Muestreo sistemático circular para k no entero
Cuando \(N/n\) no es un entero, \(k = \lfloor N/n \rfloor\) puede dar menos de \(n\) unidades. La solución es el muestreo sistemático circular: tratar la lista como circular (volver al principio tras la última unidad), extraer \(r\) de forma uniforme de \(\{1, \ldots, N\}\) y seleccionar las unidades \(r, r+k, r+2k, \ldots \pmod{N}\). Esto garantiza exactamente \(n\) unidades independientemente de si \(k\) divide exactamente \(N\).

