Muestreo polietápico
El muestreo polietápico, también llamado muestreo multietápico, aplica el muestreo por conglomerados de forma secuencial a través de dos o más niveles de la jerarquía de una población. Es el diseño estándar para las encuestas nacionales: los países son demasiado grandes para listar directamente a los individuos, pero las listas de regiones, municipios y hogares pueden combinarse en un procedimiento de muestreo viable.
Muestreo polietápico vs muestreo por conglomerados de una sola etapa
El muestreo por conglomerados de una sola etapa selecciona conglomerados y mide todas (o una muestra aleatoria de) las unidades dentro de ellos en un solo paso. El muestreo polietápico añade más etapas de selección dentro de los conglomerados seleccionados:
- Etapa 1: se seleccionan las unidades de muestreo primarias (UMP), por ejemplo, provincias o distritos.
- Etapa 2: dentro de cada UMP seleccionada, se seleccionan las unidades de muestreo secundarias (UMS), por ejemplo, municipios o secciones censales.
- Etapa 3: dentro de cada UMS seleccionada, se seleccionan las unidades terciarias, por ejemplo, hogares.
- Etapa final: dentro de los hogares seleccionados, se selecciona o entrevista a un individuo.
Cada etapa introduce su propia fracción de muestreo y, potencialmente, su propio método de muestreo (MAS, sistemático, PPT).
Probabilidades de selección entre etapas
Una propiedad clave de los diseños polietápicos: la probabilidad de selección global de cualquier unidad es el producto de las probabilidades de selección en cada etapa.
Para un diseño de tres etapas:
\[\pi_i = \pi_{i}^{(1)} \times \pi_{i}^{(2)} \times \pi_{i}^{(3)}\]
donde \(\pi_i^{(s)}\) es la probabilidad de que la unidad \(i\) sea seleccionada en la etapa \(s\). Si \(\pi_i\) es la misma para todas las unidades de la población, el diseño es autoponderado y la media muestral sin ponderación es un estimador insesgado de la media poblacional.
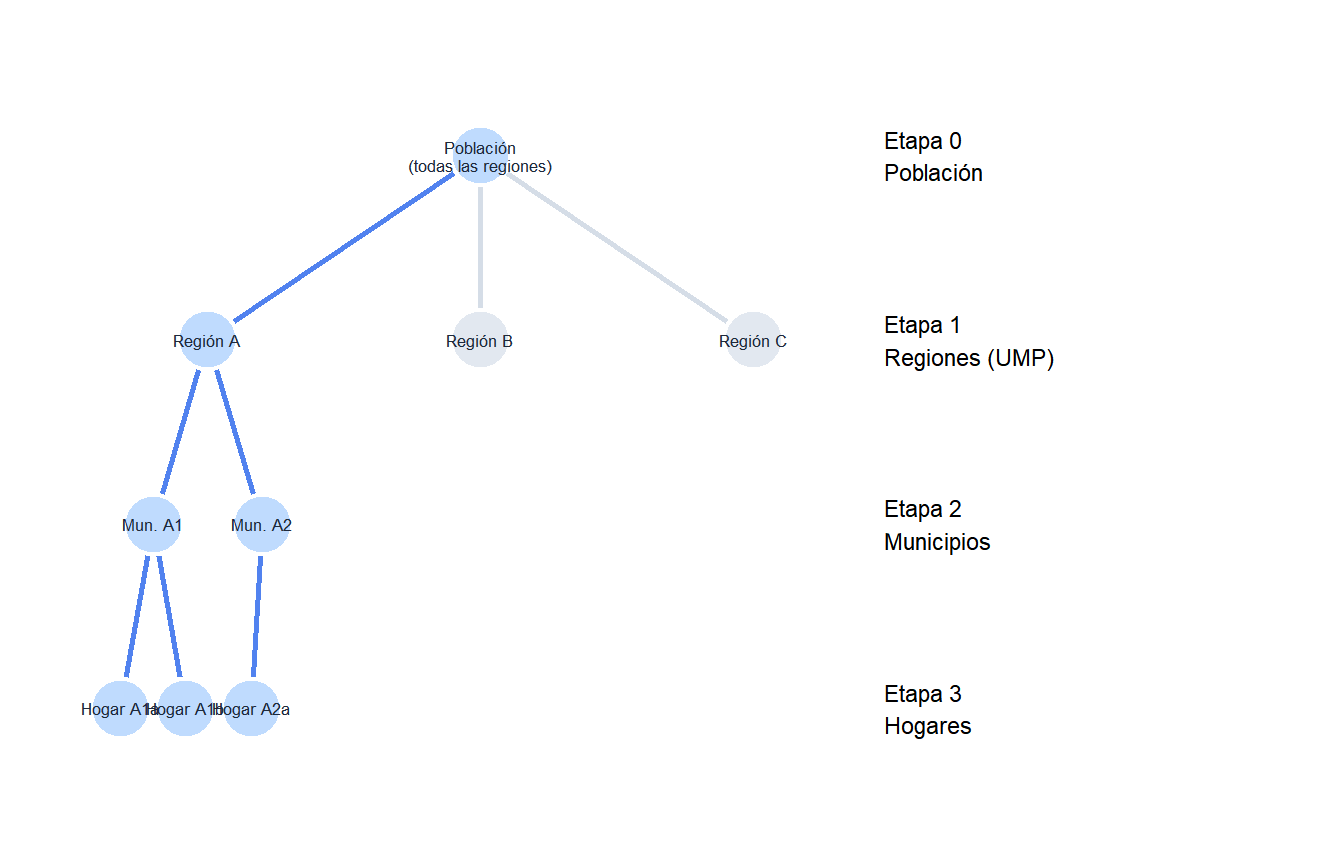
Los nodos y aristas en azul muestran la ruta seleccionada. Solo la región A se selecciona en la etapa 1; dentro de ella, los municipios A1 y A2; dentro de cada uno, hogares específicos.
Muestreo con probabilidad proporcional al tamaño (PPT)
En las encuestas nacionales, las UMP (regiones, municipios) varían enormemente en tamaño. Seleccionarlas con igual probabilidad daría a un municipio pequeño la misma oportunidad que a una gran ciudad, resultando en un diseño muy ineficiente. La solución estándar es el muestreo con probabilidad proporcional al tamaño (PPT) en la primera etapa:
\[\pi_i^{(1)} = m \cdot \frac{M_i}{\sum_j M_j}\]
donde \(m\) es el número de UMP a seleccionar y \(M_i\) es el tamaño (número de hogares, población) de la UMP \(i\). Las UMP más grandes tienen mayor probabilidad de ser seleccionadas.
La ventaja clave: si en la segunda etapa se selecciona un número fijo de unidades \(n_0\) de cada UMP seleccionada, la probabilidad de selección global es:
\[\pi_i = m \cdot \frac{M_i}{\sum M_j} \times \frac{n_0}{M_i} = \frac{m \cdot n_0}{\sum M_j}\]
Los términos \(M_i\) se cancelan, dando igual probabilidad de selección para todos los individuos: un diseño autoponderado. Esto simplifica enormemente la estimación.
Un país tiene \(\sum M_j = 10{.}000\) secciones censales. La encuesta selecciona:
- Etapa 1: \(m = 100\) secciones usando PPT.
- Etapa 2: \(n_0 = 10\) hogares por sección seleccionada usando MAS.
- Etapa 3: 1 adulto por hogar.
Muestra total: \(100 \times 10 \times 1 = 1{.}000\) adultos.
Probabilidad de selección de cualquier adulto en el país:
\[\pi = \frac{100 \times 10}{10{.}000} = \frac{1{.}000}{10{.}000} = 0{,}10 = 10\%\]
Cada adulto tiene la misma probabilidad del 10% de ser seleccionado, independientemente de la sección en la que viva. El diseño es autoponderado.
Para una sección con \(M_i = 80\) hogares: - Probabilidad en la etapa 1: \(100 \times 80/10{.}000 = 0{,}80\) - Probabilidad en la etapa 2: \(10/80 = 0{,}125\) - Global: \(0{,}80 \times 0{,}125 = 0{,}10\) ✓
Efecto de diseño en el muestreo polietápico
Cada etapa introduce agrupación, por lo que el efecto de diseño se acumula. Para un diseño de dos etapas con \(m\) UMP y \(n_0\) unidades por UMP:
\[\text{DEFF} \approx 1 + (n_0 - 1)\rho\]
donde \(\rho\) es el CIC dentro de las UMP. La misma fórmula que para el muestreo por conglomerados de una etapa, pero ahora se aplica al nivel de la UMP. Las etapas adicionales añaden más efectos de diseño.
Para conseguir un tamaño muestral efectivo de \(n_\text{ef}\), la muestra real debe ser:
\[n = n_\text{ef} \times \text{DEFF}\]
⚠️ Ten siempre en cuenta el diseño complejo al analizar datos polietápicos
Las fórmulas estándar para errores estándar, intervalos de confianza y p-valores asumen MAS. Las muestras polietápicas violan este supuesto en cada etapa. Ignorar el diseño:
- Subestima los errores estándar (a veces por un factor de 2 o más).
- Produce intervalos de confianza demasiado estrechos.
- Infla los estadísticos de contraste y los p-valores.
En R, usa el paquete survey, que gestiona correctamente la estratificación, el agrupamiento y las probabilidades de selección desiguales:
library(survey)
design <- svydesign(ids = ~ump + hogar,
weights = ~peso,
data = datos_encuesta)
svymean(~resultado, design)Las principales encuestas internacionales (DHS, PISA, Eurobarómetro, NHANES) proporcionan las variables de diseño precisamente para que los analistas puedan tener en cuenta el muestreo complejo.
Cuándo el muestreo polietápico es el diseño adecuado
El muestreo polietápico es el diseño estándar para:
- Encuestas nacionales de hogares: no existe un registro individual; las jerarquías administrativas (regiones → municipios → secciones censales → hogares) proporcionan las etapas naturales.
- Evaluaciones educativas: países → colegios → aulas → alumnos.
- Encuestas epidemiológicas: distritos → centros sanitarios → historias clínicas.
Casi siempre se combina con estratificación en la primera etapa (se divide el país en estratos y luego se seleccionan UMP dentro de cada estrato usando PPT) para mejorar la eficiencia y garantizar la cobertura geográfica.
Comparación de los cinco métodos de muestreo
| Método | Marco necesario | Eficiencia vs MAS | Mejor para |
|---|---|---|---|
| MAS | Lista individual completa | Línea base | Poblaciones pequeñas y homogéneas |
| Sistemático | Lista ordenada | \(\geq\) MAS | Listas ordenadas sin periodicidad |
| Estratificado | Lista + pertenencia a estrato | \(>\) MAS | Poblaciones heterogéneas con subgrupos conocidos |
| Conglomerados | Solo lista de conglomerados | \(<\) MAS | Poblaciones dispersas, restricciones de coste |
| Polietápico | Listas en cada nivel | \(<\) MAS | Encuestas nacionales, sin marco individual completo |

