Muestreo por conglomerados
El muestreo por conglomerados selecciona grupos (conglomerados) en lugar de unidades individuales. Es la opción práctica cuando no existe un marco muestral completo o cuando la dispersión geográfica hace que el muestreo individual sea excesivamente costoso. El coste es una menor eficiencia estadística: las muestras por conglomerados contienen menos información por unidad que el MAS porque las unidades del mismo conglomerado tienden a ser similares entre sí.
Cuándo es necesario el muestreo por conglomerados
El muestreo por conglomerados se usa cuando:
- No existe una lista completa de las unidades de la población, pero sí una lista de grupos naturales (colegios, hospitales, municipios, empresas).
- La población está geográficamente dispersa y visitar unidades individuales resulta demasiado costoso.
- La conveniencia administrativa exige trabajar con grupos en lugar de con individuos.
Ejemplos: encuestas nacionales de salud (se muestrean distritos y luego hogares), investigación educativa (se muestrean colegios y luego alumnos), investigación de mercado (se muestrean códigos postales y luego hogares).
Muestreo por conglomerados de una vs dos etapas
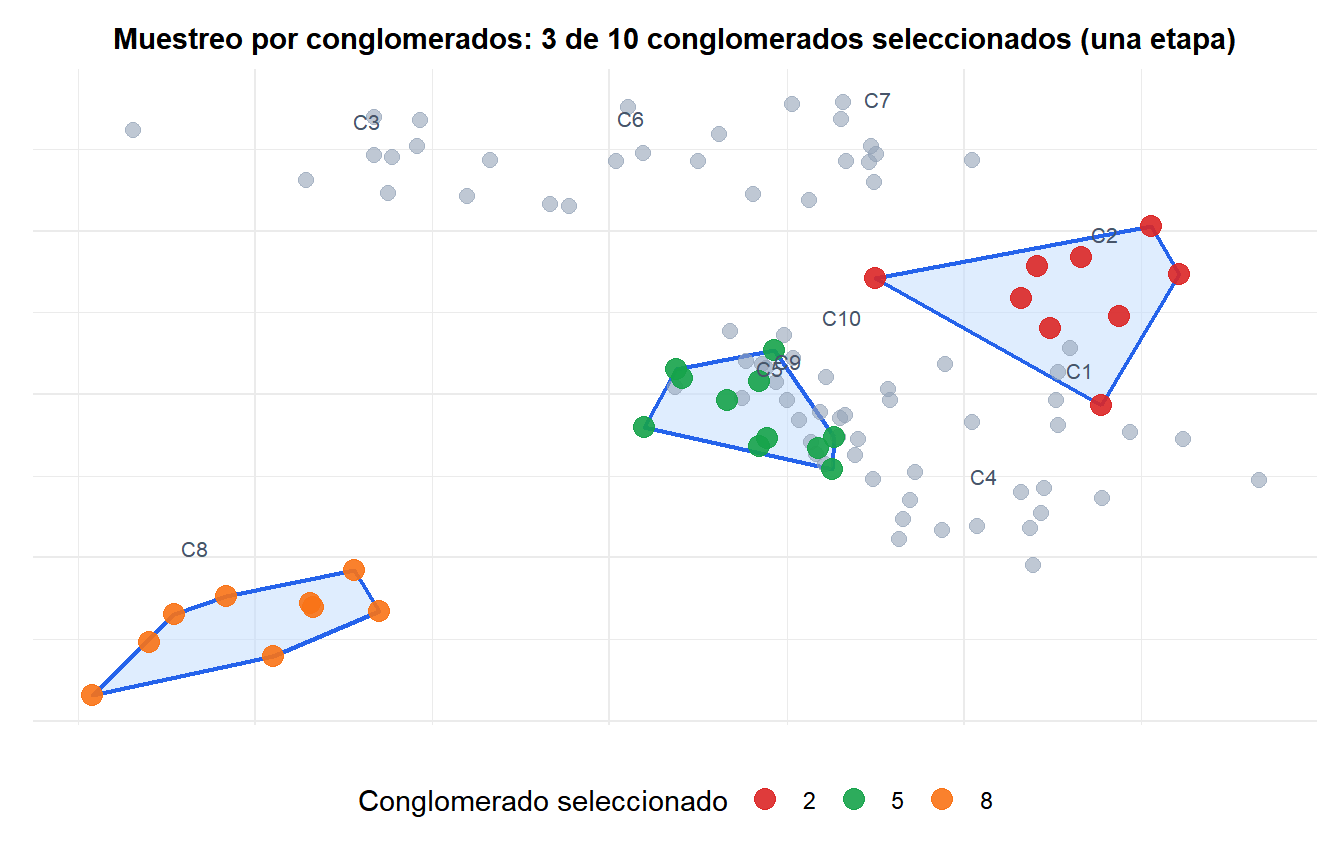
Muestreo por conglomerados de una etapa
Se seleccionan \(m\) conglomerados de los \(M\) disponibles. Se miden todas las unidades dentro de los conglomerados seleccionados. Sencillo, pero puede dar muestras muy grandes si los conglomerados son grandes.
Muestreo por conglomerados de dos etapas
Se seleccionan \(m\) conglomerados (primera etapa) y luego se extrae una muestra aleatoria de unidades dentro de cada conglomerado seleccionado (segunda etapa). Más flexible: el tamaño de la muestra dentro del conglomerado puede controlarse independientemente del tamaño del conglomerado.
Correlación intraclase y efecto de diseño
La cantidad clave en el muestreo por conglomerados es el coeficiente de correlación intraclase (CIC), \(\rho\):
\[\rho = \frac{\text{varianza entre medias de conglomerados}}{\text{varianza total}}\]
El CIC mide la similitud de las unidades dentro del mismo conglomerado. Va de 0 (los conglomerados no son más homogéneos que la población) a 1 (todas las unidades de un conglomerado son idénticas).
El efecto de diseño (DEFF) mide la pérdida de eficiencia del muestreo por conglomerados respecto al MAS del mismo tamaño total \(n\):
\[\text{DEFF} = 1 + (m_0 - 1)\rho\]
donde \(m_0\) es el número medio de unidades muestreadas por conglomerado. El tamaño muestral efectivo es \(n_\text{ef} = n / \text{DEFF}\).
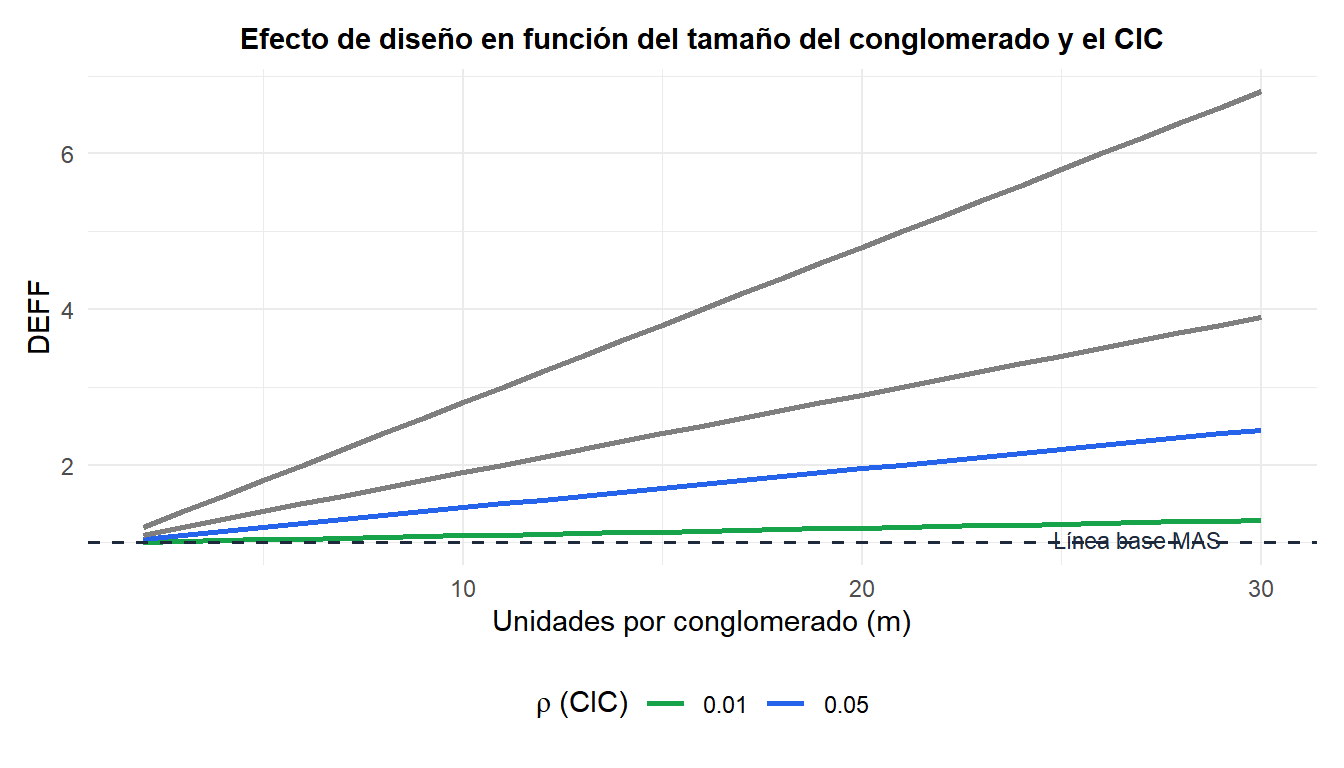
Incluso un CIC pequeño de 0,05 con 20 unidades por conglomerado da DEFF = \(1 + 19 \times 0{,}05 = 1{,}95\): se necesitan casi el doble de observaciones para conseguir la misma precisión que el MAS.
⚠️ Nunca trates las observaciones de un conglomerado como independientes
El error más frecuente y grave en el análisis de muestreo por conglomerados: tratar las \(n\) unidades individuales como si fueran \(n\) observaciones MAS independientes. Esto subestima los errores estándar, estrecha los intervalos de confianza e infla los estadísticos de contraste, produciendo resultados espuriamente significativos.
Cualquier análisis de datos con muestreo por conglomerados debe tener en cuenta la agrupación, ya sea:
- Usando errores estándar ponderados por el diseño (por ejemplo, paquete
surveyen R consvycluster()). - Incluyendo efectos aleatorios a nivel de conglomerado en un modelo mixto.
- Usando el efecto de diseño para inflar los errores estándar: \(\text{EE}_\text{ajustado} = \text{EE}_\text{naive} \times \sqrt{\text{DEFF}}\).
Este problema afecta a investigaciones publicadas en medicina, educación y ciencias sociales cuando los ensayos aleatorizados por conglomerados o los estudios multicéntricos se analizan incorrectamente.
Ejemplo: encuesta nacional de salud
Un ministerio de salud quiere estimar la proporción de adultos con hipertensión en un país de 5 millones de adultos. No existe un registro individual, pero sí una lista de 2.000 centros de atención primaria.
Diseño (dos etapas):
- Se seleccionan aleatoriamente 50 centros (conglomerados) de los 2.000 disponibles.
- Dentro de cada centro seleccionado, se muestrean aleatoriamente 30 pacientes.
Muestra total: \(n = 50 \times 30 = 1{.}500\) pacientes.
Supón que el CIC para la hipertensión dentro de los centros es \(\rho = 0{,}08\).
\[\text{DEFF} = 1 + (30 - 1) \times 0{,}08 = 1 + 2{,}32 = 3{,}32\]
\[n_\text{ef} = \frac{1{.}500}{3{,}32} \approx 452\]
Las 1.500 observaciones agrupadas proporcionan la misma precisión que solo 452 observaciones MAS. Para igualar un MAS de 1.500, el diseño por conglomerados necesitaría \(1{.}500 \times 3{,}32 \approx 4{.}980\) observaciones.
Con un coste total fijo, reducir el tamaño del conglomerado \(m_0\) y aumentar el número de conglomerados \(m\) casi siempre mejora la precisión. Esto se debe a que:
- Más conglomerados significa más información independiente.
- Menos unidades por conglomerado reduce la redundancia del agrupamiento.
Si muestrear un conglomerado cuesta \(c_1\) (desplazamiento, preparación) y muestrear una unidad cuesta \(c_2\) (entrevista), el tamaño óptimo del conglomerado es:
\[m_\text{opt} = \sqrt{\frac{c_1}{c_2} \cdot \frac{1-\rho}{\rho}}\]
Si \(c_1 = 200\), \(c_2 = 10\), \(\rho = 0{,}05\): \(m_\text{opt} = \sqrt{20 \times 19} \approx 19\) unidades por conglomerado. Muestrear más de 19 por conglomerado malgasta el presupuesto en información redundante.
💡 Muestreo por conglomerados vs estratificado: la distinción clave
Ambos métodos implican grupos, pero funcionan de manera opuesta:
- Estratificado: todos los estratos están representados; la ganancia proviene de la homogeneidad dentro del estrato.
- Por conglomerados: solo se seleccionan algunos conglomerados; la pérdida proviene de la homogeneidad dentro del conglomerado (CIC > 0).
El muestreo estratificado se elige para aumentar la eficiencia. El muestreo por conglomerados se elige por necesidad práctica (coste, ausencia de marco) y casi siempre reduce la eficiencia. Cuando ambos se usan conjuntamente (se seleccionan conglomerados y luego se estratifica dentro de ellos), el diseño se llama muestreo por conglomerados estratificado o muestreo polietápico.

