¿Qué es un estimador?
Un estimador es una función de los datos muestrales usada para aproximar un parámetro poblacional desconocido. Elegir un buen estimador no es evidente: dos estimadores distintos del mismo parámetro pueden tener precisión, varianza y comportamiento ante violaciones de supuestos muy diferentes.
Definición
Un parámetro poblacional es una característica fija y desconocida de una población: la media \(\mu\), la varianza \(\sigma^2\), la proporción \(p\), etc. Como no es posible medir toda la población, se recoge una muestra \(x_1, x_2, \ldots, x_n\) y se usa una función de esas observaciones para aproximar el parámetro.
Un estimador \(\hat{\theta}\) es cualquier función de los datos muestrales utilizada para estimar un parámetro poblacional \(\theta\):
\[\hat{\theta} = g(x_1, x_2, \ldots, x_n)\]
El resultado de aplicar el estimador a un conjunto de datos concreto se llama estimación. El estimador es la regla; la estimación es el número.
⚠️ Estimador vs estimación: dos cosas distintas
Un estimador es una variable aleatoria: antes de recoger datos puede tomar muchos valores posibles según la muestra que se obtenga. Una estimación es el valor concreto que toma el estimador una vez que se tienen los datos.
La media muestral \(\bar{X} = \frac{1}{n}\sum X_i\) es un estimador. El valor \(\bar{x} = 47{,}3\) calculado a partir de un conjunto de datos específico es una estimación. Esta distinción importa al hablar de propiedades como la insesgadez, que es una propiedad del estimador (su comportamiento promedio sobre todas las muestras posibles), no de ninguna estimación concreta.
Los estimadores se dividen en dos grandes categorías:
- Estimadores puntuales: producen un único valor como estimación (\(\hat{\mu} = \bar{x}\)).
- Estimadores por intervalo: producen un rango de valores plausibles (intervalos de confianza).
Este post se centra en los estimadores puntuales.
Propiedades deseables de los estimadores
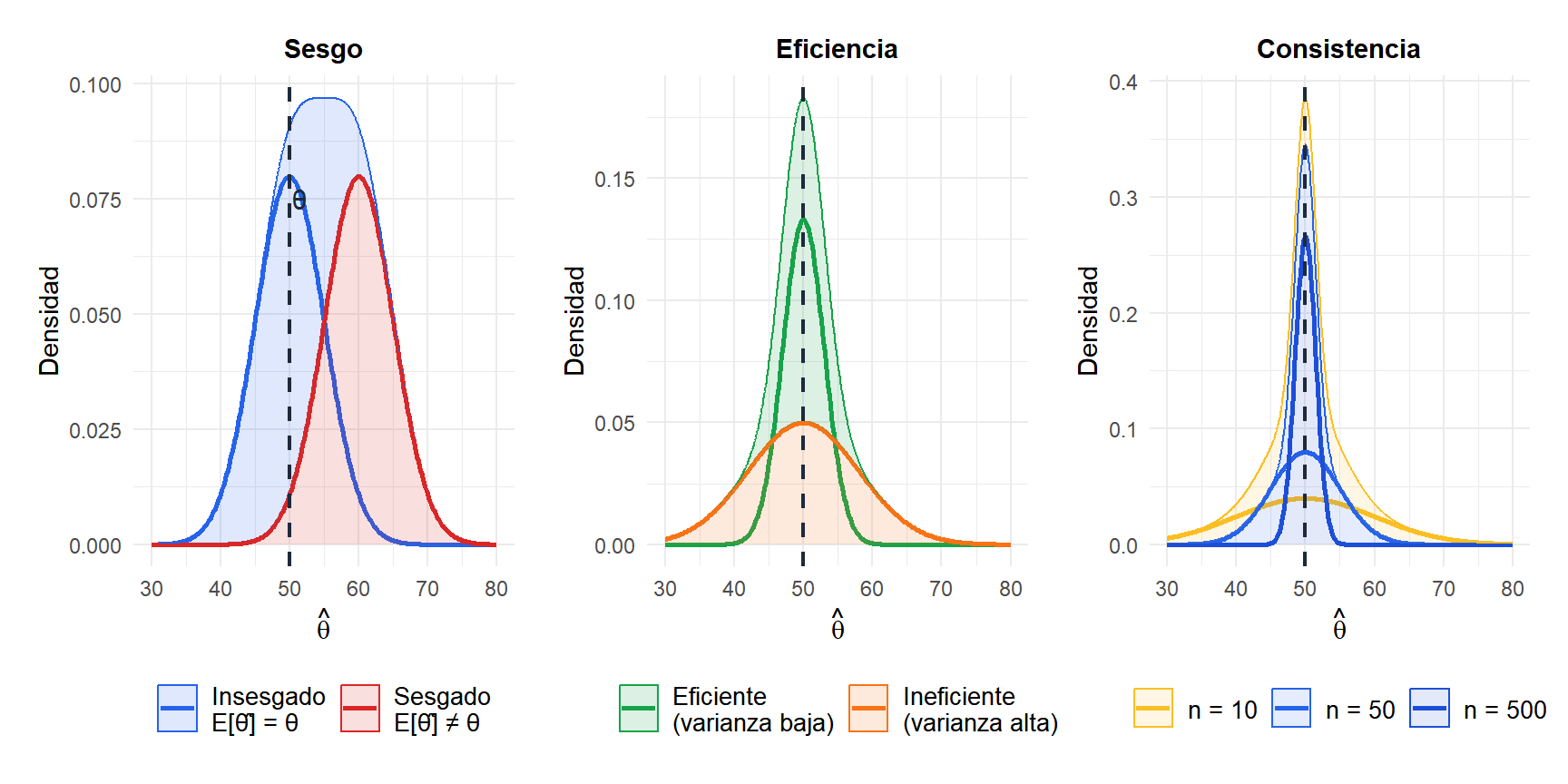
- Insesgadez
Un estimador \(\hat{\theta}\) es insesgado si su valor esperado es igual al verdadero parámetro:
\[E[\hat{\theta}] = \theta\]
La media muestral \(\bar{X}\) es un estimador insesgado de \(\mu\): en promedio sobre todas las muestras posibles, da en el blanco. La varianza muestral \(S^2 = \frac{1}{n-1}\sum(X_i - \bar{X})^2\) es un estimador insesgado de \(\sigma^2\): obsérvese el \(n-1\) en el denominador (corrección de Bessel). Usar \(n\) en su lugar da un estimador sesgado.
- Consistencia
Un estimador es consistente si converge al valor verdadero a medida que crece el tamaño muestral:
\[\lim_{n \to \infty} P(|\hat{\theta} - \theta| > \varepsilon) = 0 \quad \text{para cualquier } \varepsilon > 0\]
Un estimador consistente se vuelve más preciso con más datos. La media muestral es consistente para \(\mu\); la mediana muestral también es consistente para \(\mu\) en distribuciones simétricas.
- Eficiencia
Entre todos los estimadores insesgados, el estimador eficiente tiene la menor varianza. La cota teórica inferior viene dada por la cota de Cramér-Rao:
\[\text{Var}(\hat{\theta}) \geq \frac{1}{I(\theta)}\]
donde \(I(\theta)\) es la información de Fisher. Un estimador que alcanza esta cota se llama estimador insesgado de varianza mínima (MVUE). Para datos normales, \(\bar{X}\) es el MVUE para \(\mu\).
- Suficiencia
Un estimador es suficiente si captura toda la información de la muestra relevante para \(\theta\). Una vez que se conoce un estadístico suficiente, el resto de los datos no añade nada. La media muestral es suficiente para \(\mu\) en poblaciones normales.
- Robustez
Un estimador robusto funciona bien incluso cuando se violan los supuestos, especialmente en presencia de outliers. La mediana es más robusta que la media: una única observación extrema puede desplazar mucho la media, pero apenas mueve la mediana.
Error cuadrático medio
En la práctica, la insesgadez y la eficiencia están a menudo en tensión: un estimador ligeramente sesgado pero con varianza mucho menor puede ser más útil que un estimador insesgado con varianza alta. El error cuadrático medio (ECM) unifica ambos aspectos:
\[\text{ECM}(\hat{\theta}) = E[(\hat{\theta} - \theta)^2] = \text{Var}(\hat{\theta}) + \text{Sesgo}(\hat{\theta})^2\]
Un buen estimador minimiza el ECM, no necesariamente el sesgo por sí solo. Este es el fundamento del compromiso sesgo-varianza, central tanto en la estadística clásica como en el machine learning.
Dos estimadores para la varianza poblacional \(\sigma^2\):
- \(S^2 = \frac{1}{n-1}\sum(X_i - \bar{X})^2\): insesgado, \(E[S^2] = \sigma^2\).
- \(\hat{\sigma}^2 = \frac{1}{n}\sum(X_i - \bar{X})^2\): sesgado, \(E[\hat{\sigma}^2] = \frac{n-1}{n}\sigma^2\).
El estimador sesgado tiene una varianza ligeramente menor. Para \(n\) grande la diferencia es despreciable, pero para muestras pequeñas se prefiere la versión insesgada. En la estimación por máxima verosimilitud se usa habitualmente \(\hat{\sigma}^2\) (con \(n\) en el denominador), aceptando un pequeño sesgo a cambio de otras propiedades favorables.
Estimadores habituales
| Parámetro | Estimador | ¿Insesgado? | Notas |
|---|---|---|---|
| Media \(\mu\) | \(\bar{X} = \frac{1}{n}\sum X_i\) | Sí | MVUE para datos normales |
| Varianza \(\sigma^2\) | \(S^2 = \frac{1}{n-1}\sum(X_i-\bar{X})^2\) | Sí | Corrección de Bessel |
| Proporción \(p\) | \(\hat{p} = X/n\) | Sí | \(X\) = número de éxitos |
| Mediana | Mediana muestral | Sí (dist. simétricas) | Más robusto que la media |
| Máximo de Uniforme\((0,\theta)\) | \(\frac{n+1}{n}X_{(n)}\) | Sí | El MLE \(X_{(n)}\) es sesgado |
💡 Cómo elegir entre estimadores
Ningún criterio domina en todas las situaciones:
- Si los supuestos se cumplen (normalidad, sin outliers): prefiere el MVUE, generalmente la media muestral.
- Si los datos tienen colas pesadas u outliers: prefiere estimadores robustos (mediana, media recortada).
- Si el tamaño muestral es pequeño: la insesgadez importa más; prefiere \(S^2\) frente a \(\hat{\sigma}^2\).
- Si la precisión de predicción importa más que la interpretabilidad: minimiza el ECM, aceptando cierto sesgo.
En la práctica, conviene examinar los datos, verificar los supuestos y comparar estimadores mediante simulación cuando la mejor opción no sea evidente.

