Cálculo del tamaño muestral
El cálculo del tamaño muestral es el paso que determina cuántas observaciones se necesitan para estimar un parámetro con el nivel de precisión y confianza deseados. Una muestra demasiado pequeña da un intervalo demasiado amplio para ser útil; una demasiado grande malgasta recursos. El objetivo es encontrar el \(n\) mínimo que cumpla los requisitos.
Principio general
Un intervalo de confianza tiene la forma:
\[\text{estimación} \pm \underbrace{z_{\alpha/2} \cdot \text{EE}}_{\text{margen de error } d}\]
El margen de error \(d\) disminuye al crecer \(n\) (ya que \(\text{EE} \propto 1/\sqrt{n}\)). Para lograr un margen de error objetivo \(d\), se despeja \(n\). El tamaño muestral necesario siempre depende de tres cosas:
- El nivel de confianza \((1-\alpha)\): mayor confianza requiere \(n\) más grande.
- El margen de error \(d\): menor \(d\) requiere \(n\) más grande.
- La variabilidad poblacional (\(\sigma\) o \(p\)): poblaciones más variables requieren \(n\) más grande.
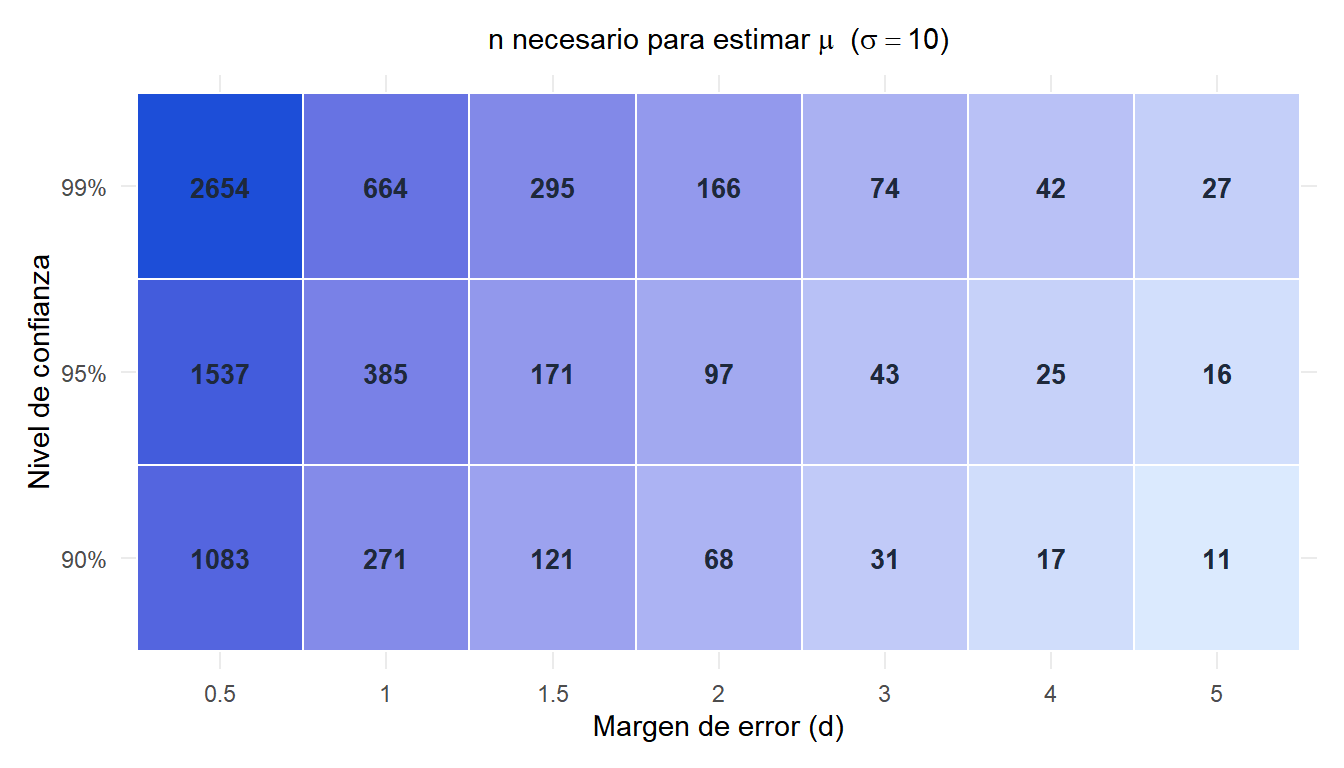
El mapa de calor muestra que márgenes de error pequeños con niveles de confianza altos exigen muestras muy grandes. Reducir el margen de error a la mitad cuadruplica el \(n\) necesario.
Tamaño muestral para estimar una media
Para estimar \(\mu\) con margen de error \(d\) al nivel de confianza \(1-\alpha\), cuando \(\sigma\) es conocida:
\[n \geq \left(\frac{z_{\alpha/2} \cdot \sigma}{d}\right)^2\]
Cuando \(\sigma\) es desconocida, sustitúyela por una estimación piloto \(S\) y usa \(t_{\alpha/2, n-1}\) en lugar de \(z_{\alpha/2}\). Como \(t\) depende de \(n\), itera: empieza con \(z\), calcula \(n\), luego comprueba con \(t_{n-1}\) y ajusta si es necesario.
Valores habituales de \(z_{\alpha/2}\):
| Nivel de confianza | \(z_{\alpha/2}\) |
|---|---|
| 90% | 1,645 |
| 95% | 1,960 |
| 99% | 2,576 |
Un hospital quiere estimar la estancia media para un grupo diagnóstico con una precisión de \(\pm 0{,}5\) días al 95% de confianza. De un estudio piloto, \(S \approx 3{,}1\) días.
\[n \geq \left(\frac{1{,}960 \times 3{,}1}{0{,}5}\right)^2 = \left(\frac{6{,}076}{0{,}5}\right)^2 = 12{,}152^2 \approx 147{,}7 \to 148\]
Se necesitan al menos 148 pacientes. Si el presupuesto solo permite 50 pacientes, el margen de error alcanzable sería:
\[d = 1{,}960 \times \frac{3{,}1}{\sqrt{50}} \approx 0{,}86 \text{ días}\]
El hospital debe decidir si un margen de \(\pm 0{,}86\) días es aceptable.
Tamaño muestral para estimar una proporción
Para estimar \(p\) con margen de error \(d\):
\[n \geq \frac{z_{\alpha/2}^2 \cdot p(1-p)}{d^2}\]
Como \(p\) es desconocida, usa una estimación previa si se dispone de ella. Si no, usa \(p = 0{,}5\), que maximiza \(p(1-p) = 0{,}25\) y da el tamaño muestral más conservador (mayor).
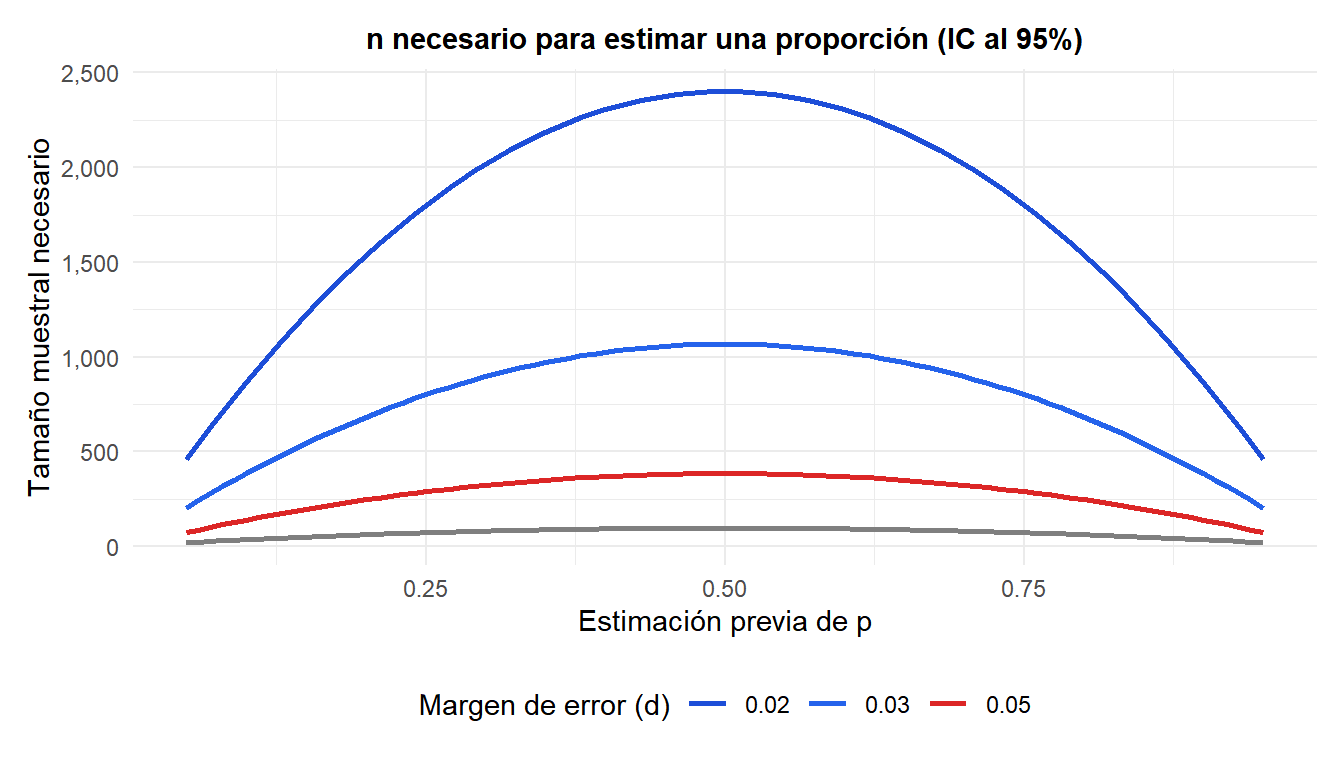
El gráfico muestra que el \(n\) máximo necesario se produce siempre en \(p = 0{,}5\), y que reducir \(d\) del 5% al 2% aproximadamente cuadruplica el tamaño muestral necesario.
Una fábrica quiere estimar su tasa de defectos con una precisión de \(\pm 2\%\) al 95% de confianza. Una auditoría previa encontró una tasa de defectos de aproximadamente el 8%.
Usando la estimación previa \(p = 0{,}08\):
\[n \geq \frac{1{,}960^2 \times 0{,}08 \times 0{,}92}{0{,}02^2} = \frac{3{,}842 \times 0{,}0736}{0{,}0004} = \frac{0{,}2828}{0{,}0004} \approx 707\]
Usando el valor conservador \(p = 0{,}5\):
\[n \geq \frac{1{,}960^2 \times 0{,}25}{0{,}02^2} = \frac{0{,}9604}{0{,}0004} = 2{.}401\]
La estimación previa ahorra 1.694 inspecciones. Cuando \(p\) está lejos de 0,5, usar información previa es eficiente.
Tamaño muestral para comparar dos medias
Para detectar una diferencia de \(\delta = \mu_1 - \mu_2\) con margen de error \(d\) al nivel de confianza \(1-\alpha\), asumiendo tamaños muestrales iguales \(n_1 = n_2 = n\) y varianzas iguales \(\sigma^2\):
\[n \geq 2\left(\frac{z_{\alpha/2} \cdot \sigma}{d}\right)^2\]
Para un contraste de hipótesis que detecte una diferencia \(\delta\) con potencia \(1-\beta\):
\[n \geq \frac{2\sigma^2(z_{\alpha/2} + z_\beta)^2}{\delta^2}\]
donde \(z_\beta\) es el cuantil de la normal estándar para la potencia deseada (por ejemplo, \(z_{0{,}80} = 0{,}842\) para una potencia del 80%, \(z_{0{,}90} = 1{,}282\) para el 90%).
Un ensayo compara la reducción de la presión arterial entre dos fármacos. De datos previos, \(\sigma \approx 12\) mmHg. La diferencia clínicamente relevante es \(\delta = 5\) mmHg. Se diseña el ensayo con un 95% de confianza y un 80% de potencia.
\[n \geq \frac{2 \times 144 \times (1{,}960 + 0{,}842)^2}{25} = \frac{288 \times 7{,}852}{25} = \frac{2{.}261}{25} \approx 91\]
Cada grupo necesita al menos 91 pacientes (182 en total). Para el 90% de potencia:
\[n \geq \frac{2 \times 144 \times (1{,}960 + 1{,}282)^2}{25} = \frac{288 \times 10{,}511}{25} \approx 121 \text{ por grupo}\]
Pasar del 80% al 90% de potencia aumenta el total muestral de 182 a 242.
Consideraciones prácticas
⚠️ El n calculado es un mínimo, no un objetivo
La fórmula da el \(n\) mínimo en condiciones ideales. En la práctica, auméntalo siempre para tener en cuenta:
- Abandonos y no respuesta: si se espera un 15% de abandono, divide entre 0,85. Un estudio que necesita 148 observaciones completas requiere inscribir \(148/0{,}85 \approx 175\) participantes.
- Comparaciones múltiples: si se contrastan varias hipótesis, el \(\alpha\) efectivo por contraste es menor, lo que requiere \(n\) mayor.
- Muestreo por conglomerados: las observaciones dentro de los conglomerados están correlacionadas. Multiplica \(n\) por el efecto de diseño \(\text{DEFF} = 1 + (m-1)\rho\), donde \(m\) es el tamaño del conglomerado y \(\rho\) es la correlación intraclase.
- Análisis de subgrupos: si se necesita estimar parámetros dentro de subgrupos, cada subgrupo necesita su propio \(n\) mínimo.
Una buena regla práctica: calcula el \(n\) mínimo, añade un 20% como margen de seguridad y luego revisa la viabilidad.
💡 Qué hacer cuando el n necesario es demasiado grande
Si el tamaño muestral calculado supera el presupuesto o los plazos:
- Aumenta \(d\): acepta un margen de error mayor. Duplicar \(d\) divide \(n\) entre cuatro.
- Reduce el nivel de confianza: pasar del 99% al 95% reduce \(n\) en aproximadamente un 30%.
- Usa una mejor estimación previa de \(p\) o \(\sigma\): un estudio piloto para estimar la variabilidad puede reducir sustancialmente el \(n\) necesario.
- Usa un contraste unilateral: si solo importa una dirección, \(z_{\alpha}\) en lugar de \(z_{\alpha/2}\) reduce \(n\).
- Acepta menor potencia: reducir la potencia del 90% al 80% ahorra aproximadamente el 25% de las observaciones en un contraste de dos muestras.
Documenta explícitamente cualquier compromiso: los revisores y los organismos reguladores preguntarán.

