Desviación típica y varianza en estadística
La varianza y la desviación típica miden cuánto se dispersan los valores de un conjunto de datos alrededor de la media. Son las medidas de dispersión más utilizadas en estadística, y entender sus diferencias, incluido cuándo dividir por \(n\) o por \(n-1\), es fundamental.
Definiciones
Varianza
La varianza mide la distancia cuadrática media de cada observación respecto a la media. Elevar al cuadrado las diferencias tiene dos propósitos: hace que todos los valores sean positivos y penaliza las desviaciones grandes más que las pequeñas.
Existen dos versiones según se trabaje con una población completa o con una muestra.
Varianza poblacional (cuando se tienen datos de toda la población):
\[ \sigma^2 = \frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})^2 \]
Varianza muestral (cuando se trabaja con una muestra y se quiere estimar la varianza poblacional):
\[ s^2 = \frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2 \]
⚠️ Varianza poblacional vs. varianza muestral: la corrección de n-1
Dividir por (n-1) en lugar de (n) en la fórmula muestral se llama corrección de Bessel. El motivo: al calcular la media a partir de una muestra, ya se está usando los datos para estimar un parámetro. Esto deja solo (n-1) piezas de información independientes. Dividir por (n) subestima sistemáticamente la varianza poblacional real. Dividir por (n-1) corrige ese sesgo.
En la práctica: si los datos son la población completa, usa \(n\). Si los datos son una muestra (que es casi siempre el caso), usa \(n-1\). La mayoría del software, incluyendo la función var() de R, usa \(n-1\) por defecto.
Desviación típica
La desviación típica es la raíz cuadrada de la varianza. Su ventaja principal sobre la varianza es que se expresa en las mismas unidades que los datos originales, lo que la hace directamente interpretable.
Desviación típica poblacional:
\[ \sigma = \sqrt{\frac{1}{n} \sum_{i=1}^{n} (x_i - \bar{x})^2} \]
Desviación típica muestral:
\[ s = \sqrt{\frac{1}{n-1} \sum_{i=1}^{n} (x_i - \bar{x})^2} \]
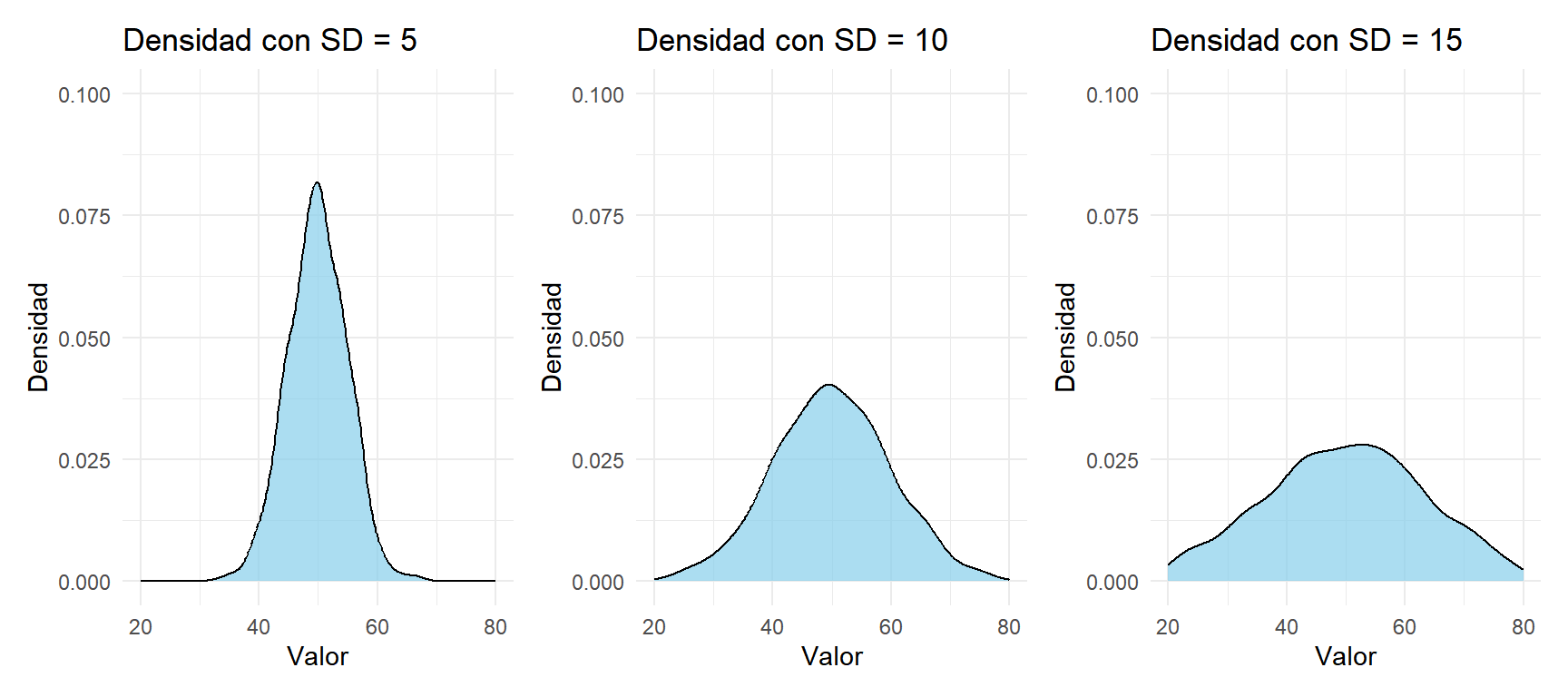
Figure 1: Misma media, distintas desviaciones típicas: mayor SD implica una distribución más ancha y aplanada
Propiedades
- No negativas: tanto la varianza como la desviación típica son siempre \(\geq 0\). Valen cero solo cuando todos los valores son idénticos.
- Mismas unidades: la desviación típica está en las mismas unidades que los datos. La varianza está en unidades al cuadrado, por eso la desviación típica es preferible para la interpretación.
- Sensibles a los outliers: ambas medidas se ven afectadas por los valores extremos, ya que las desviaciones se elevan al cuadrado. Un único outlier puede inflar la varianza considerablemente.
- Transformación lineal: si \(Y = aX + b\), entonces \(\sigma_Y = |a| \cdot \sigma_X\) y \(\sigma_Y^2 = a^2 \cdot \sigma_X^2\). Sumar una constante no cambia la dispersión; multiplicar la escala.
⚠️ Varianza y desviación típica no son intercambiables
Un error frecuente es usar la varianza y la desviación típica como si midieran lo mismo en la misma escala. Si la desviación típica de las notas de un examen es 8 puntos, la varianza es 64 puntos². Reportar una varianza de 64 como si fueran “64 puntos de dispersión” es incorrecto: son 64 puntos al cuadrado. Usa siempre la desviación típica cuando necesites una medida de dispersión interpretable en las unidades originales.
Ejemplos
Ejemplo 1: cálculo paso a paso
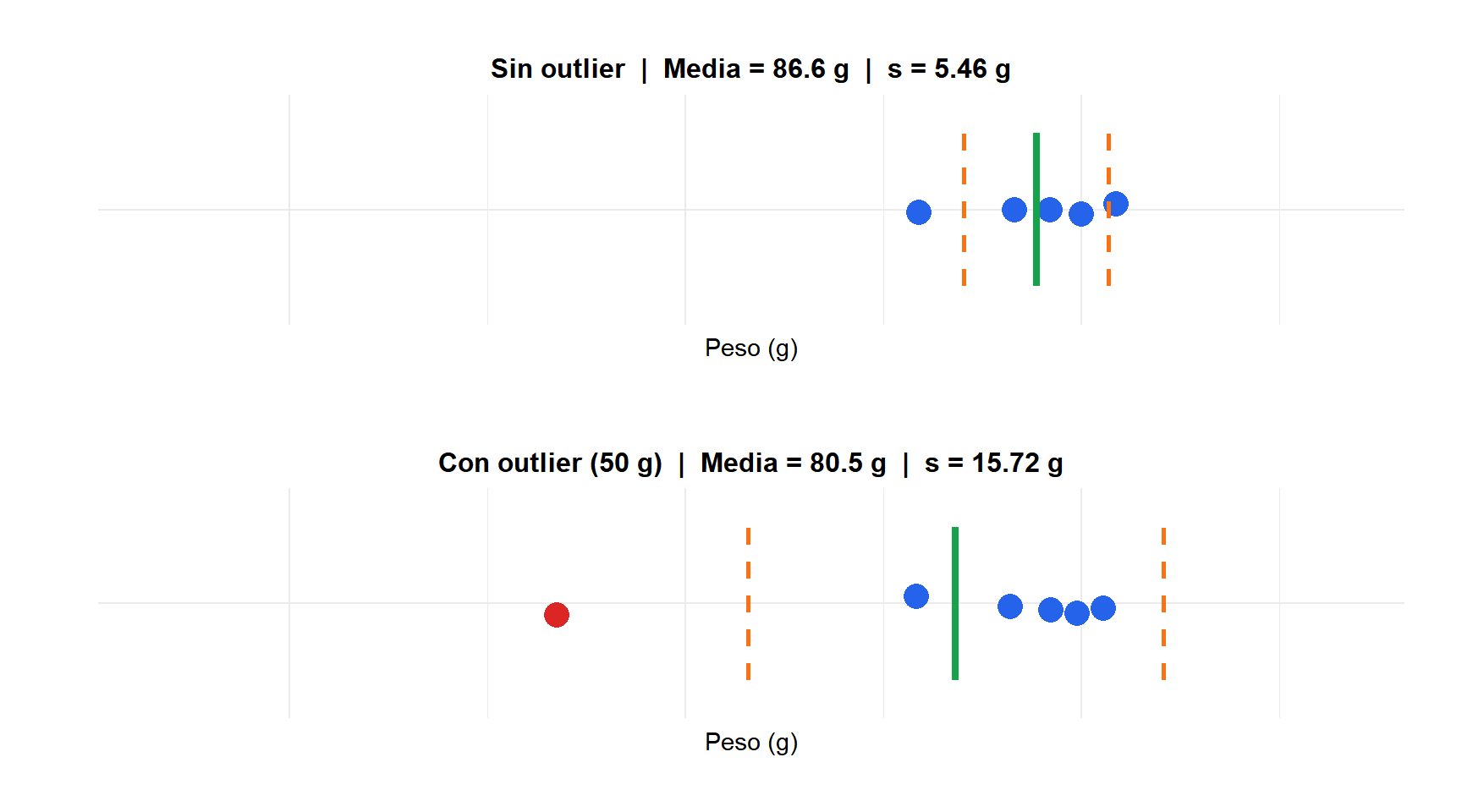
Un equipo de control de calidad mide el peso (en gramos) de 5 piezas de un lote de producción: \(85, 90, 88, 92, 78\).
Paso 1: calcular la media.
\[\bar{x} = \frac{85 + 90 + 88 + 92 + 78}{5} = 86{,}6 \text{ g}\]
Paso 2: calcular las desviaciones al cuadrado respecto a la media.
| \(x_i\) | \(x_i - \bar{x}\) | \((x_i - \bar{x})^2\) |
|---|---|---|
| 85 | \(-1{,}6\) | \(2{,}56\) |
| 90 | \(3{,}4\) | \(11{,}56\) |
| 88 | \(1{,}4\) | \(1{,}96\) |
| 92 | \(5{,}4\) | \(29{,}16\) |
| 78 | \(-8{,}6\) | \(73{,}96\) |
| Suma | \(119{,}2\) |
Paso 3: calcular la varianza y la desviación típica.
Como se trata de una muestra (no el lote completo), usamos \(n - 1 = 4\):
\[s^2 = \frac{119{,}2}{4} = 29{,}8 \text{ g}^2\]
\[s = \sqrt{29{,}8} \approx 5{,}46 \text{ g}\]
La pieza típica se desvía unos 5,5 gramos respecto al peso medio.
Ejemplo 2: el efecto de un outlier
Supongamos que se cuela una pieza defectuosa con un peso de 50 g. El nuevo conjunto de datos es: \(85, 90, 88, 92, 78, 50\).
\[\bar{x} = \frac{85 + 90 + 88 + 92 + 78 + 50}{6} = 80{,}5 \text{ g}\]
\[s^2 = \frac{(85-80{,}5)^2 + (90-80{,}5)^2 + (88-80{,}5)^2 + (92-80{,}5)^2 + (78-80{,}5)^2 + (50-80{,}5)^2}{5} = \frac{1215{,}5}{5} = 243{,}1 \text{ g}^2\]
\[s = \sqrt{243{,}1} \approx 15{,}59 \text{ g}\]
Una sola pieza defectuosa triplicó la desviación típica, de 5,46 g a 15,59 g. Por eso la desviación típica es sensible a los outliers: el término al cuadrado amplifica las desviaciones extremas.
💡 Cuándo usar la desviación típica frente a otras medidas de dispersión

