Contraste z de una muestra para la media
El contraste z de una muestra para la media se usa cuando la desviación típica poblacional \(\sigma\) es conocida. En la práctica esto es raro: \(\sigma\) casi nunca se conoce de verdad, y debe usarse el contraste \(t\) en su lugar. El contraste z sigue siendo útil como herramienta didáctica y en algunos contextos aplicados específicos.
Cuándo usar el contraste z frente al contraste t
Ambos contrastes evalúan \(H_0: \mu = \mu_0\), pero difieren en lo que se asume sobre \(\sigma\):
| Contraste z | Contraste t | |
|---|---|---|
| \(\sigma\) | Conocida | Desconocida (estimada por \(S\)) |
| Distribución de referencia | \(N(0,1)\) | \(t(n-1)\) |
| Cuándo usar | \(\sigma\) realmente conocida por datos previos o teoría | Prácticamente siempre |
Para \(n\) grande, la distribución \(t\) converge a la normal estándar y ambos contrastes dan resultados casi idénticos. Para \(n\) pequeño, el contraste \(t\) es más conservador (región crítica más amplia) y correcto.
⚠️ Usar S en lugar de σ y llamarlo contraste z es incorrecto
Un error frecuente: calcular \(Z = (\bar{X} - \mu_0)/(S/\sqrt{n})\) y compararlo con \(z_{\alpha/2} = 1{,}96\). Esto es incorrecto. Cuando \(\sigma\) se sustituye por \(S\), el estadístico ya no sigue una normal estándar: sigue una distribución \(t\). Usar valores críticos de \(z\) subestima la incertidumbre y produce contrastes anticonservadores.
Las únicas situaciones en que \(\sigma\) puede considerarse realmente conocida:
- Datos históricos de control de procesos con muestras de referencia muy grandes (por ejemplo, un proceso de fabricación monitorizado durante años).
- Exámenes estandarizados donde la desviación típica poblacional está establecida por el organismo evaluador.
- Distribuciones teóricas con parámetro de desviación típica conocido (por ejemplo, un recuento de Poisson donde \(\sigma = \sqrt{\mu}\)).
En todos los demás casos, usa t.test() en R, no un contraste z.
Fórmula
Dada una muestra de tamaño \(n\) con media muestral \(\bar{x}\) y desviación típica poblacional conocida \(\sigma\):
\[Z = \frac{\bar{x} - \mu_0}{\sigma / \sqrt{n}}\]
Bajo \(H_0\), \(Z \sim N(0,1)\). El p-valor se calcula a partir de la distribución normal estándar.
Ejemplos
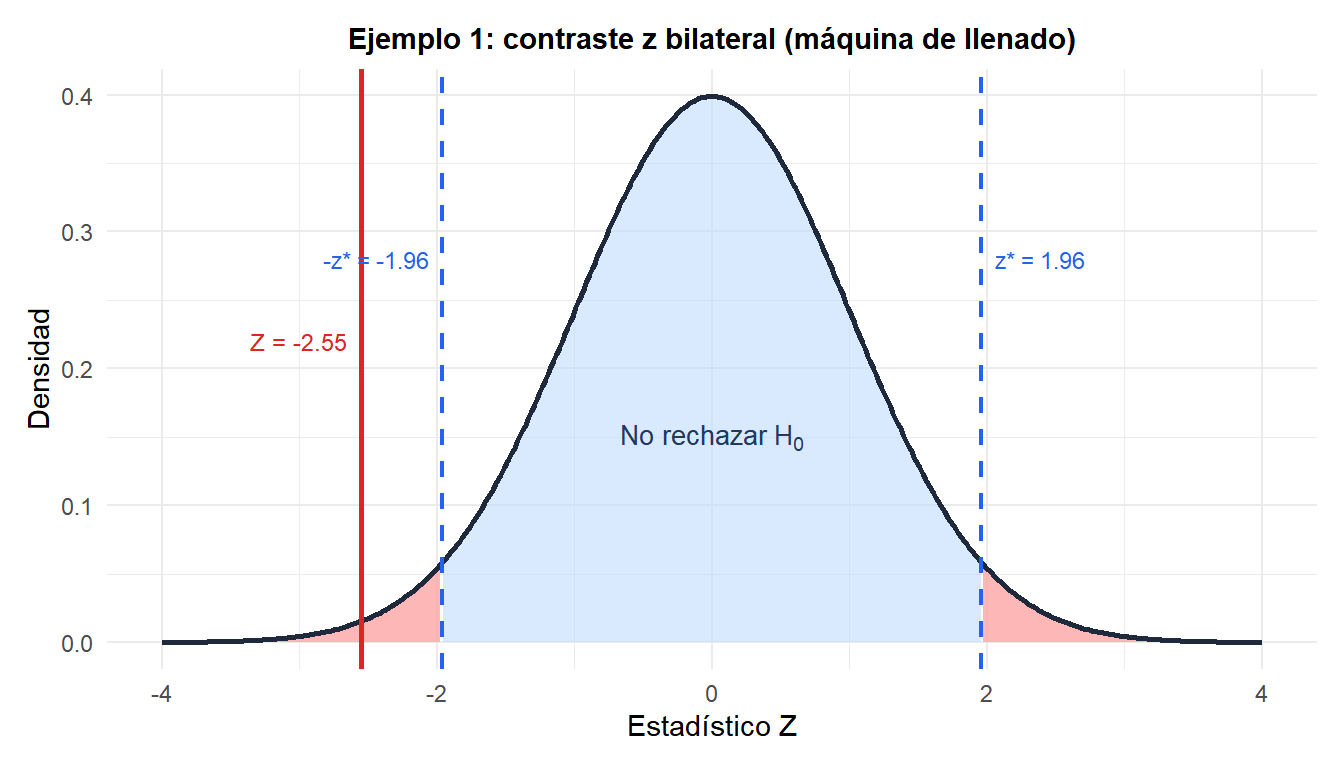
Ejemplo 1: control de calidad (bilateral)
Una máquina de llenado está calibrada para dispensar \(\mu_0 = 500\) ml por botella. La variabilidad de la máquina está bien establecida por años de registros de producción: \(\sigma = 4\) ml. Un ingeniero de calidad muestrea 36 botellas y obtiene \(\bar{x} = 498{,}3\) ml. ¿Ha derivado la calibración?
Hipótesis: \(H_0: \mu = 500\) frente a \(H_1: \mu \neq 500\).
Estadístico del contraste:
\[Z = \frac{498{,}3 - 500}{4/\sqrt{36}} = \frac{-1{,}7}{0{,}667} \approx -2{,}550\]
P-valor (bilateral):
\[p = 2 \times P(Z \leq -2{,}550) = 2 \times 0{,}0054 = 0{,}011\]
Decisión: \(p = 0{,}011 < 0{,}05\), rechazamos \(H_0\).
La producción de la máquina ha derivado significativamente por debajo del objetivo. Es necesaria la recalibración.
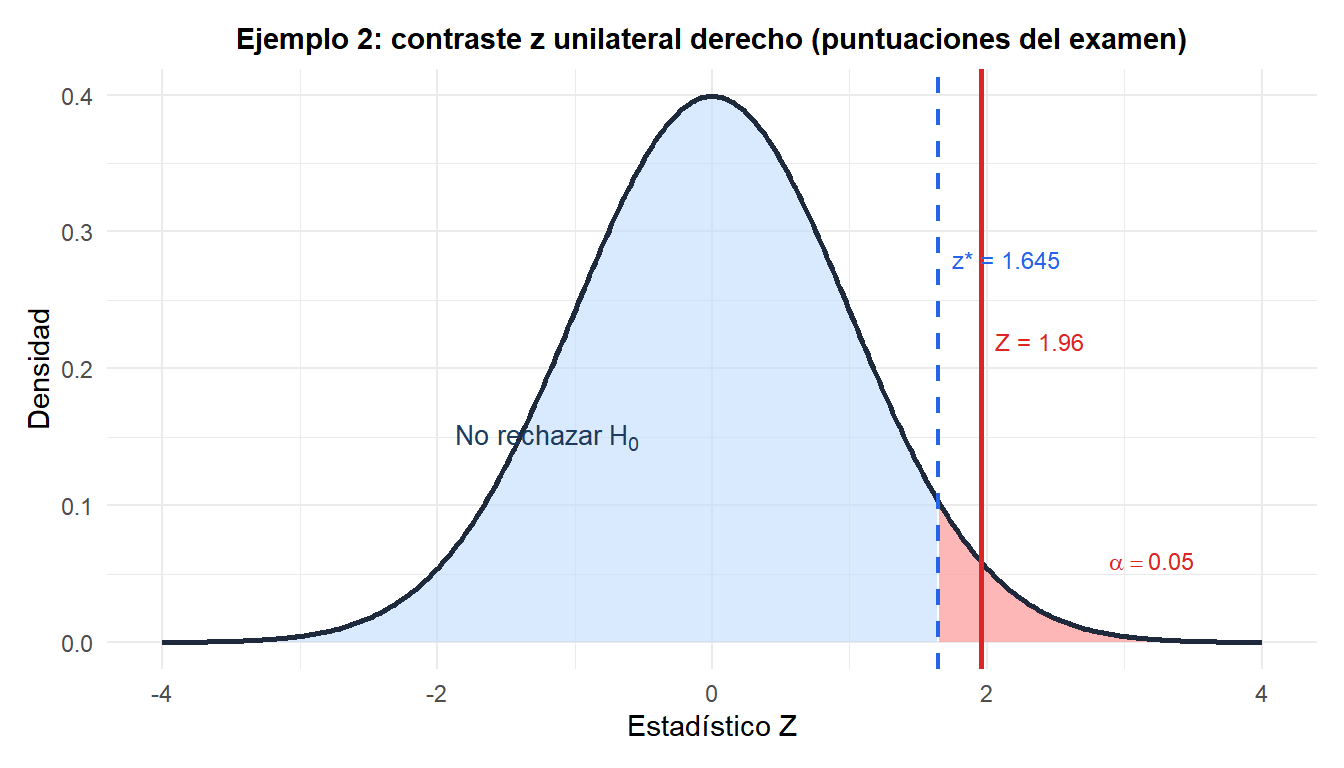
Ejemplo 2: puntuaciones en un examen estandarizado (unilateral derecho)
Un examen nacional estandarizado tiene una desviación típica poblacional conocida de \(\sigma = 15\) puntos (establecida a partir de millones de administraciones anteriores). Un distrito escolar evalúa a 49 alumnos tras implantar un nuevo currículo y obtiene \(\bar{x} = 104{,}2\). ¿Hay evidencia de que el currículo mejoró las puntuaciones por encima de la media nacional de \(\mu_0 = 100\)?
Hipótesis: \(H_0: \mu = 100\) frente a \(H_1: \mu > 100\).
Estadístico del contraste:
\[Z = \frac{104{,}2 - 100}{15/\sqrt{49}} = \frac{4{,}2}{2{,}143} \approx 1{,}960\]
P-valor (unilateral derecho):
\[p = P(Z \geq 1{,}960) = 0{,}025\]
Decisión: \(p = 0{,}025 < 0{,}05\), rechazamos \(H_0\).
Hay evidencia significativa al nivel del 5% de que el nuevo currículo mejoró las puntuaciones por encima de la media nacional.
Conexión con el intervalo de confianza
Cuando \(\sigma\) es conocida, el IC al \((1-\alpha)\) para \(\mu\) usa \(z_{\alpha/2}\) en lugar de \(t_{\alpha/2,n-1}\):
\[\bar{x} \pm z_{\alpha/2} \cdot \frac{\sigma}{\sqrt{n}}\]
Para el ejemplo 1: \(498{,}3 \pm 1{,}96 \times 4/\sqrt{36} = 498{,}3 \pm 1{,}307 = (496{,}99;\; 499{,}61)\).
Como \(\mu_0 = 500\) cae fuera de este intervalo, el contraste bilateral rechaza \(H_0\) al nivel del 5%, consistente con \(p = 0{,}011\).
Realizar el contraste en R
R base no tiene una función dedicada z.test() porque el contraste \(t\) cubre todos los casos prácticos. Para las raras situaciones en que \(\sigma\) es realmente conocida:
# Contraste z manual
x_bar <- 498.3
mu0 <- 500
sigma <- 4
n <- 36
z_stat <- (x_bar - mu0) / (sigma / sqrt(n))
p_two <- 2 * pnorm(-abs(z_stat)) # bilateral
p_one <- pnorm(z_stat) # unilateral izquierdo
# El paquete BSDA proporciona z.test()
library(BSDA)
z.test(x, mu = 500, sigma.x = 4, alternative = "two.sided")💡 Contraste z vs contraste t: la regla práctica
- \(\sigma\) desconocida → usa siempre
t.test(). Este es el caso en prácticamente todas las aplicaciones reales. - \(\sigma\) conocida a partir de una línea de base histórica muy grande (miles de observaciones) → el contraste z es aceptable.
- \(n\) grande (\(\geq 100\)) y \(\sigma\) desconocida → el contraste \(t\) y el z dan resultados casi idénticos, pero el contraste \(t\) sigue siendo el correcto.
El contraste z es principalmente útil para enseñar la lógica de los contrastes de hipótesis: usa la distribución normal estándar, más sencilla, y evita la complicación de los grados de libertad.

