t-SNE y UMAP
t-SNE y UMAP son métodos de reducción de dimensionalidad no lineal diseñados para visualización. A diferencia del PCA, que encuentra una proyección lineal que maximiza la varianza, preservan la estructura de vecindad local de los datos: los puntos cercanos en el espacio de alta dimensión permanecen cercanos en 2D. El resultado es un mapa que revela clusters, estructura de variedades y subpoblaciones invisibles en un gráfico PCA.
Por qué el PCA no es suficiente para visualización
El PCA es una proyección lineal: encuentra el mejor plano 2D plano a través de los datos de alta dimensión. Si los datos se encuentran en una variedad curva (p.ej., un rollo suizo, una esfera, o una colección de clusters conectados por puentes delgados), la proyección lineal aplasta la estructura y superpone regiones distantes.
t-SNE y UMAP aprenden un mapeo no lineal que “despliega” la variedad, separando regiones que son genuinamente distintas en alta dimensión aunque se proyecten en la misma región bajo el PCA.
t-SNE: Inserción de Vecinos Estocástica con distribución t
t-SNE (van der Maaten y Hinton, 2008) convierte las distancias en probabilidades por separado en los espacios de alta y baja dimensión, y luego minimiza la divergencia KL entre ellas.
En el espacio de alta dimensión: define una similitud gaussiana entre los puntos \(i\) y \(j\):
\[p_{j|i} = \frac{\exp(-\|x_i - x_j\|^2 / 2\sigma_i^2)}{\sum_{k \neq i} \exp(-\|x_i - x_k\|^2 / 2\sigma_i^2)}, \quad p_{ij} = \frac{p_{j|i} + p_{i|j}}{2n}\]
El ancho de banda \(\sigma_i\) se ajusta para que el número efectivo de vecinos (perplejidad) sea aproximadamente el parámetro perplexity especificado por el usuario.
En el espacio de baja dimensión: usa una distribución t de Student con 1 grado de libertad (colas más pesadas que la gaussiana):
\[q_{ij} = \frac{(1 + \|y_i - y_j\|^2)^{-1}}{\sum_{k \neq l}(1 + \|y_k - y_l\|^2)^{-1}}\]
Objetivo: minimizar la divergencia KL \(\text{KL}(P \| Q) = \sum_{ij} p_{ij} \log(p_{ij}/q_{ij})\) mediante descenso de gradiente.
¿Por qué la distribución t? Una gaussiana en baja dimensión está demasiado concentrada: los puntos moderadamente distantes en alta dimensión necesitarían estar todos juntos en 2D (el problema del apiñamiento). Las colas pesadas de la distribución t permiten separar más los puntos moderadamente similares, dando espacio a los clusters para respirar.
UMAP: Aproximación y Proyección de Variedades Uniformes
UMAP (McInnes et al., 2018) se basa en una fundamento matemático distinto (conjuntos simpliciales difusos y geometría riemanniana) pero comparte la misma idea de alto nivel: preservar la estructura de vecindad. Diferencias clave respecto a t-SNE:
- Más rápido: \(O(n \log n)\) frente al \(O(n^2)\) de t-SNE (aproximación Barnes-Hut).
- Mejor estructura global: UMAP intenta preservar tanto las relaciones locales como las globales, no solo las locales.
- Más estable: menos sensible a la inicialización aleatoria; múltiples ejecuciones dan resultados más similares.
- De propósito general: puede proyectar a dimensiones arbitrarias, no solo 2D.
UMAP construye una representación topológica difusa de los datos, encuentra una representación de baja dimensión con estructura topológica similar, y optimiza la entropía cruzada entre los dos conjuntos difusos.
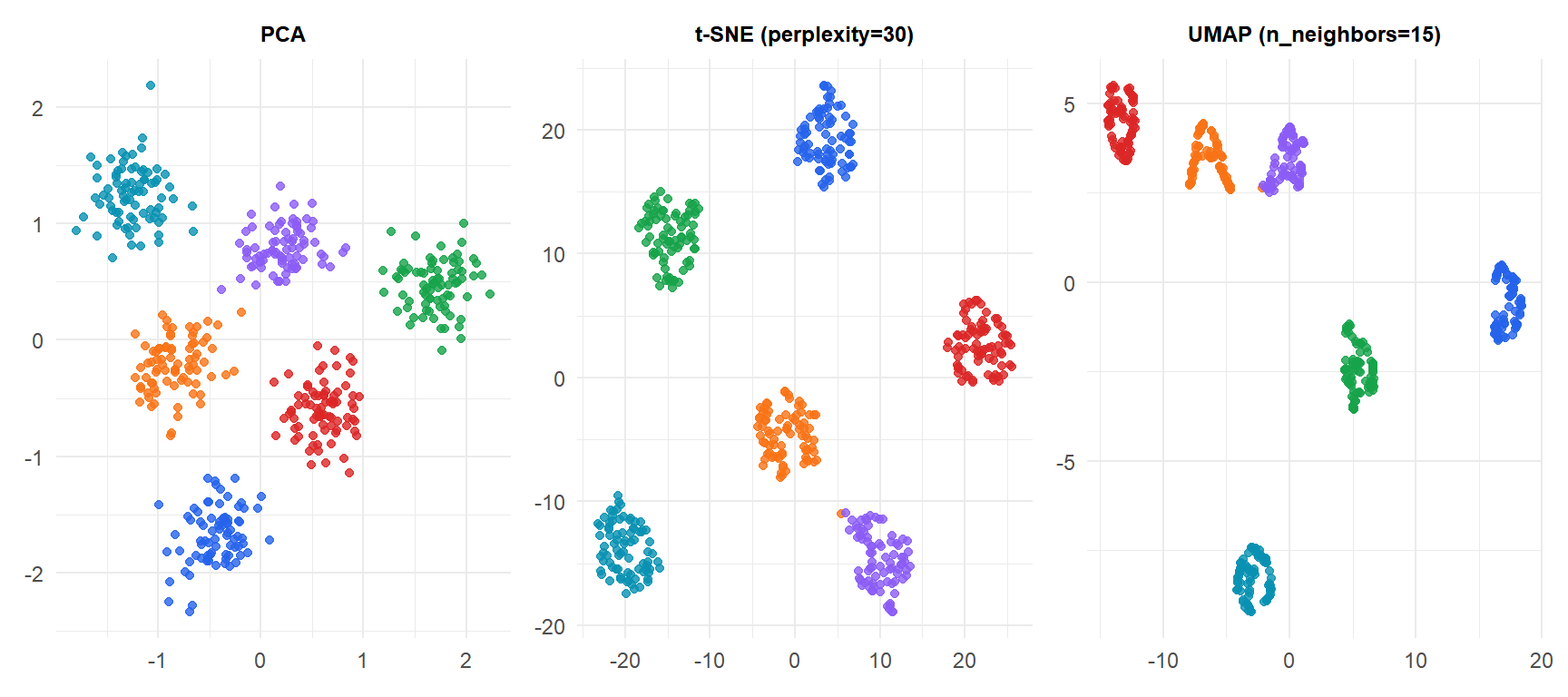
Los tres métodos separan correctamente los seis clusters en este sencillo conjunto de datos 2D. La ventaja de t-SNE y UMAP se hace evidente con datos de alta dimensión (p.ej., imágenes, genómica, RNA-seq de célula única) donde el PCA superpone subpoblaciones distintas.
Hiperparámetros clave
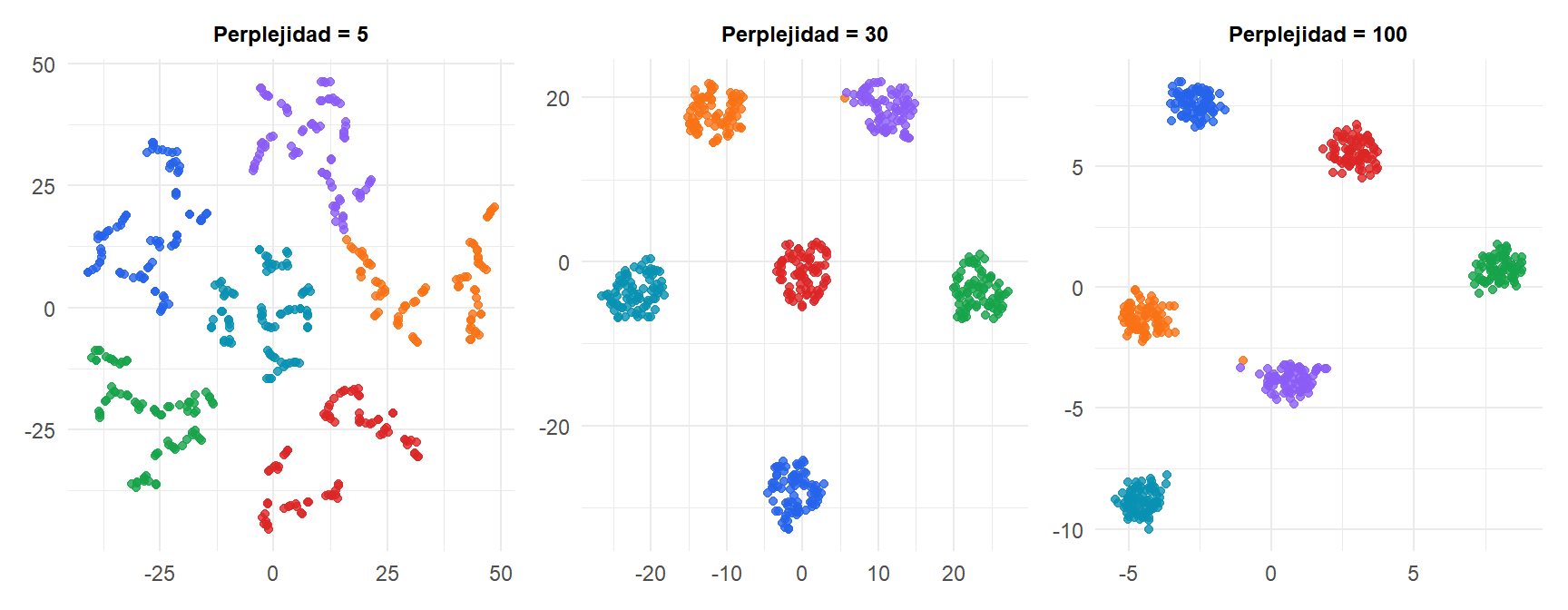
t-SNE: perplejidad
La perplejidad controla el número efectivo de vecinos que cada punto considera. Equilibra aproximadamente la atención entre la estructura local y global:
- Perplejidad baja (5-10): muy local, clusters compactos, puede fragmentar clusters grandes en subclusters.
- Perplejidad alta (50-100): más global, los clusters pueden fusionarse.
- Rango típico: 5 a 50. Valor predeterminado: 30.
Regla práctica: la perplejidad debe ser menor que \(n/3\).
UMAP: n_neighbors y min_dist
n_neighbors controla el tamaño de la vecindad local (como la perplejidad): valores mayores capturan más estructura global. min_dist controla cuán apretados están los puntos en la representación: valores pequeños producen clusters compactos; valores grandes dispersan más los puntos.
Errores críticos de interpretación
⚠️ Cuatro cosas que los gráficos t-SNE y UMAP NO dicen
1. Los tamaños de los clusters no tienen significado. t-SNE expande clusters pequeños y densos y comprime los grandes y dispersos. El tamaño visual de un cluster no refleja el número de puntos ni la dispersión de los datos originales.
2. Las distancias entre clusters no son interpretables. t-SNE optimiza la estructura local; la distancia entre dos clusters bien separados en el gráfico 2D no tiene significado cuantitativo. Que el cluster A esté el doble de lejos del cluster B que del C no significa que sea el doble de diferente.
3. El número de clusters no es fiable. Ambos métodos pueden dividir una única población continua en subclusters aparentes (especialmente t-SNE con baja perplejidad) o fusionar clusters distintos (con alta perplejidad). Valida siempre los clusters aparentes con un algoritmo de clustering sobre los datos originales de alta dimensión.
4. Los resultados cambian con la semilla aleatoria. t-SNE no es determinista; cada ejecución con una semilla diferente produce una disposición distinta. UMAP es más estable pero también varía. Nunca bases conclusiones en una sola ejecución. Para t-SNE, inicializa con PCA (pca_init=TRUE) y usa múltiples semillas.
t-SNE vs UMAP: cuándo usar cada uno
| t-SNE | UMAP | |
|---|---|---|
| Velocidad | Lento (\(O(n^2)\), Barnes-Hut \(O(n \log n)\)) | Rápido (\(O(n \log n)\)) |
| Estructura global | Deficiente | Mejor |
| Estabilidad | Baja (varía según semilla) | Mayor |
| Escalabilidad | \(n < 100{,}000\) | \(n > 100{,}000\) factible |
| Interpretabilidad | Muy limitada | Ligeramente mejor |
| Uso típico | Biología, RNA-seq de célula única | Propósito general, grandes conjuntos |
Para la mayoría de proyectos nuevos: empieza con UMAP. Es más rápido, más estable y preserva más estructura. Usa t-SNE cuando compares con trabajo publicado que lo usa, o en genómica donde es el estándar del campo.
💡 t-SNE y UMAP en R
library(Rtsne)
# t-SNE (eliminar duplicados primero, init PCA para estabilidad)
set.seed(42)
tsne_res <- Rtsne(X, dims=2, perplexity=30, max_iter=1000,
pca=TRUE, pca_center=TRUE, normalize=TRUE,
check_duplicates=FALSE)
df_tsne <- data.frame(D1=tsne_res$Y[,1], D2=tsne_res$Y[,2])
# UMAP
library(umap)
set.seed(42)
umap_res <- umap(X, n_neighbors=15, min_dist=0.1, n_components=2)
df_umap <- data.frame(D1=umap_res$layout[,1], D2=umap_res$layout[,2])
# Paquete uwot (UMAP más rápido, más control)
library(uwot)
embedding <- uwot::umap(X, n_neighbors=15, min_dist=0.1,
metric="euclidean", n_epochs=200)
