Regresión lineal múltiple
La regresión lineal múltiple extiende la regresión simple a \(k\) predictores. Cada coeficiente mide el efecto de un predictor manteniendo todos los demás constantes, una distinción crucial respecto a la regresión simple donde cada coeficiente también absorbe los efectos de las variables omitidas.
El modelo
\[y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \cdots + \beta_k x_{ik} + \varepsilon_i, \qquad \varepsilon_i \sim N(0, \sigma^2)\]
En forma matricial, con \(\mathbf{y} \in \mathbb{R}^n\), matriz de diseño \(\mathbf{X} \in \mathbb{R}^{n \times (k+1)}\) (primera columna de unos) y \(\boldsymbol{\beta} \in \mathbb{R}^{k+1}\):
\[\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\varepsilon}, \qquad \boldsymbol{\varepsilon} \sim N(\mathbf{0}, \sigma^2 \mathbf{I})\]
El estimador MCO minimiza \(\|\mathbf{y} - \mathbf{X}\boldsymbol{\beta}\|^2\) y tiene la solución en forma cerrada:
\[\hat{\boldsymbol{\beta}} = (\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\mathbf{y}\]
Esto requiere que \(\mathbf{X}^T\mathbf{X}\) sea invertible: las columnas de \(\mathbf{X}\) deben ser linealmente independientes (sin multicolinealidad perfecta). Los valores ajustados son \(\hat{\mathbf{y}} = \mathbf{X}\hat{\boldsymbol{\beta}} = \mathbf{H}\mathbf{y}\) donde \(\mathbf{H} = \mathbf{X}(\mathbf{X}^T\mathbf{X})^{-1}\mathbf{X}^T\) es la matriz de proyección.
Teorema de Gauss-Markov: bajo linealidad, independencia, homocedasticidad y errores de media cero (sin requerir normalidad), el MCO es BLUE: el Mejor Estimador Lineal Insesgado (MELI). Ningún otro estimador lineal insesgado tiene menor varianza.
Interpretación de los coeficientes
Cada \(\hat{\beta}_j\) mide el cambio esperado en \(y\) por un incremento de una unidad en \(x_j\), manteniendo todos los demás predictores constantes. Este efecto parcial es fundamentalmente distinto de la pendiente en una regresión simple, que también captura la correlación entre \(x_j\) y los demás predictores.
\[\widehat{\text{Precio}} = 50.000 + 200 \cdot \text{Superficie} + 10.000 \cdot \text{Habitaciones} - 1.000 \cdot \text{Antigüedad}\]
- Coeficiente de superficie (200): cada m² adicional añade 200 € al precio predicho, manteniendo habitaciones y antigüedad fijos.
- Coeficiente de habitaciones (10.000): cada habitación adicional añade 10.000 €, manteniendo superficie y antigüedad fijas. Nótese que la superficie se mantiene constante: una casa más grande que casualmente tiene más habitaciones no se cuenta dos veces.
- Coeficiente de antigüedad ($-$1.000): cada año adicional reduce el precio en 1.000 €, manteniendo superficie y habitaciones fijas.
Bondad de ajuste
R² y R² ajustado
\(R^2 = 1 - \text{SCR}/\text{SCT}\) siempre aumenta cuando se añade un predictor, aunque sea ruido puro. El R² ajustado penaliza por el número de predictores \(k\):
\[\bar{R}^2 = 1 - \frac{\text{SCR}/(n-k-1)}{\text{SCT}/(n-1)} = 1 - (1-R^2)\frac{n-1}{n-k-1}\]
El R² ajustado puede disminuir al añadir un predictor irrelevante. Usa \(R^2\) para comunicar la varianza explicada; usa el R² ajustado o el AIC/BIC para la selección de modelos.
Contraste F de significación global
Contrasta \(H_0: \beta_1 = \beta_2 = \cdots = \beta_k = 0\) (ningún predictor es útil) frente a \(H_1\): al menos un \(\beta_j \neq 0\):
\[F = \frac{(\text{SCT}-\text{SCR})/k}{\text{SCR}/(n-k-1)} = \frac{\text{CMR}}{\text{CME}} \sim F(k, n-k-1) \text{ bajo } H_0\]
Un contraste F significativo indica que el modelo en su conjunto es útil. Los contrastes t individuales identifican luego qué predictores contribuyen.
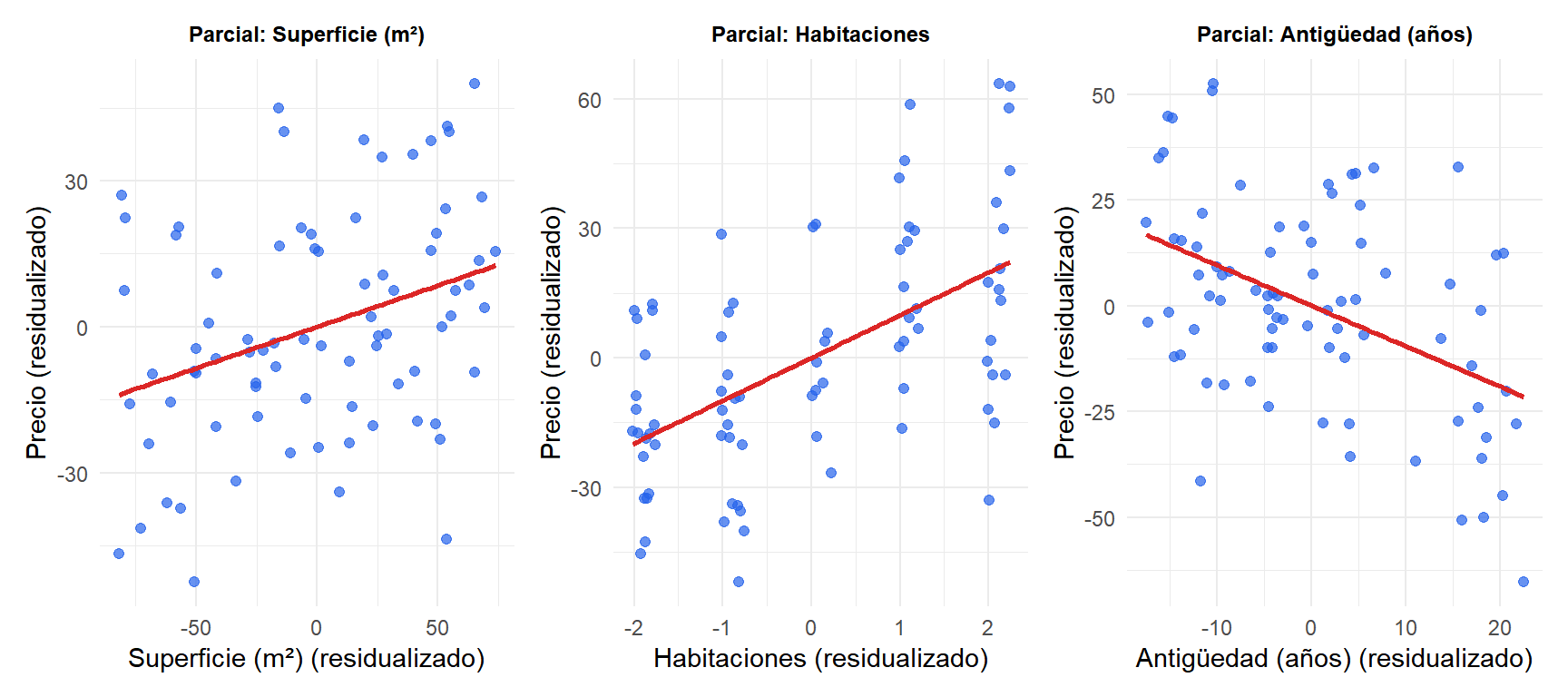
Los gráficos de regresión parcial muestran la relación entre cada predictor y la respuesta una vez eliminados los efectos de todos los demás. La pendiente en cada panel coincide con el coeficiente MCO correspondiente: el efecto de la superficie, las habitaciones y la antigüedad manteniendo los demás constantes.
Multicolinealidad
Cuando los predictores están muy correlacionados, \(\mathbf{X}^T\mathbf{X}\) se vuelve casi singular: las estimaciones de los coeficientes son inestables con errores estándar grandes. Los predictores comparten el mérito de explicar \(y\), haciendo imposible aislar sus efectos individuales.
El Factor de Inflación de la Varianza (VIF) cuantifica la multicolinealidad para cada predictor \(j\):
\[\text{VIF}_j = \frac{1}{1 - R_j^2}\]
donde \(R_j^2\) es el \(R^2\) de regresionar \(x_j\) sobre todos los demás predictores. Un \(\text{VIF}_j > 10\) (algunos usan 5) indica multicolinealidad problemática.
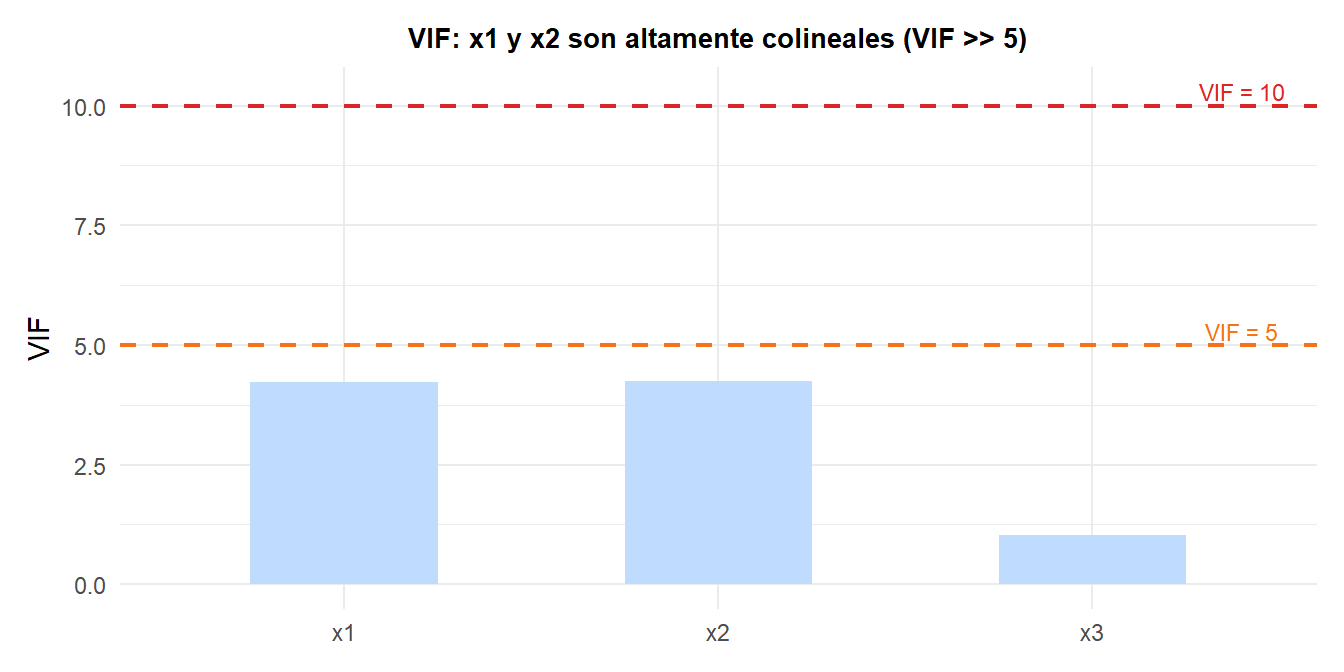
Cuando el VIF es alto para \(x_1\) y \(x_2\), los coeficientes individuales \(\hat{\beta}_1\) y \(\hat{\beta}_2\) tienen errores estándar grandes y pueden incluso tener signo incorrecto, mientras que su suma \(\hat{\beta}_1 + \hat{\beta}_2\) se estima con precisión. Soluciones: eliminar uno de los predictores colineales, combinarlos (p. ej., promediándolos) o usar regresión Ridge.
⚠️ Añadir predictores siempre aumenta el R² pero no la calidad del modelo
Cada predictor añadido al modelo aumentará (o, como mucho, no cambiará) el \(R^2\), aunque sea ruido aleatorio puro. Con \(n=20\) observaciones y \(k=19\) predictores, \(R^2 = 1\) por construcción, pero el modelo no predice nada útil en datos nuevos.
Usa siempre el R² ajustado, el AIC o el BIC para comparar modelos con distinto número de predictores. Mejor aún, evalúa con datos reservados mediante validación cruzada: solo las mejoras que generalizan a datos nuevos son reales.
💡 Regresión lineal múltiple en R
fit <- lm(price ~ size + bedrooms + age, data = df)
summary(fit) # coeficientes, contrastes t y F, R² y R² ajustado
confint(fit) # IC al 95% para todos los coeficientes
anova(fit) # tabla ANOVA
# Multicolinealidad
library(car)
vif(fit) # VIF de cada predictor; > 5 es preocupante
# Gráficos de regresión parcial
avPlots(fit)
# Comparación de modelos
AIC(fit1, fit2)
BIC(fit1, fit2)
