Regresión Lasso
La regresión Lasso (Least Absolute Shrinkage and Selection Operator) añade una penalización sobre la norma \(L_1\) de los coeficientes. A diferencia de Ridge, la penalización \(L_1\) fuerza algunos coeficientes exactamente a cero, realizando selección de variables automática. Esto hace el modelo más interpretable cuando se sospecha que solo unos pocos predictores son realmente relevantes.
El estimador Lasso
\[\hat{\boldsymbol{\beta}}^{\text{Lasso}} = \arg\min_{\boldsymbol{\beta}} \left\{\|\mathbf{y} - \mathbf{X}\boldsymbol{\beta}\|^2 + \lambda\|\boldsymbol{\beta}\|_1\right\}\]
donde \(\|\boldsymbol{\beta}\|_1 = \sum_j |\beta_j|\).
A diferencia de Ridge, no existe solución en forma cerrada porque la norma \(L_1\) no es diferenciable en cero. El problema es convexo (un único mínimo global) pero requiere algoritmos iterativos.
Umbralización suave
Para el caso ortogonal (\(\mathbf{X}^T\mathbf{X} = \mathbf{I}\)), la solución Lasso tiene una forma analítica llamada umbralización suave (soft-thresholding):
\[\hat{\beta}_j^{\text{Lasso}} = S_{\lambda/2}(\hat{\beta}_j^{\text{MCO}}) = \text{sign}(\hat{\beta}_j^{\text{MCO}}) \cdot \max\!\left(|\hat{\beta}_j^{\text{MCO}}| - \frac{\lambda}{2}, 0\right)\]
Esta operación: - Coeficientes pequeños (\(|\hat{\beta}_j^{\text{MCO}}| \leq \lambda/2\)): se ponen exactamente a cero. - Coeficientes grandes: se encogen en \(\lambda/2\) hacia cero pero mantienen su signo.
Comparado con Ridge que encoge todo proporcionalmente, el Lasso tiene un umbral duro que elimina los predictores con efecto pequeño.
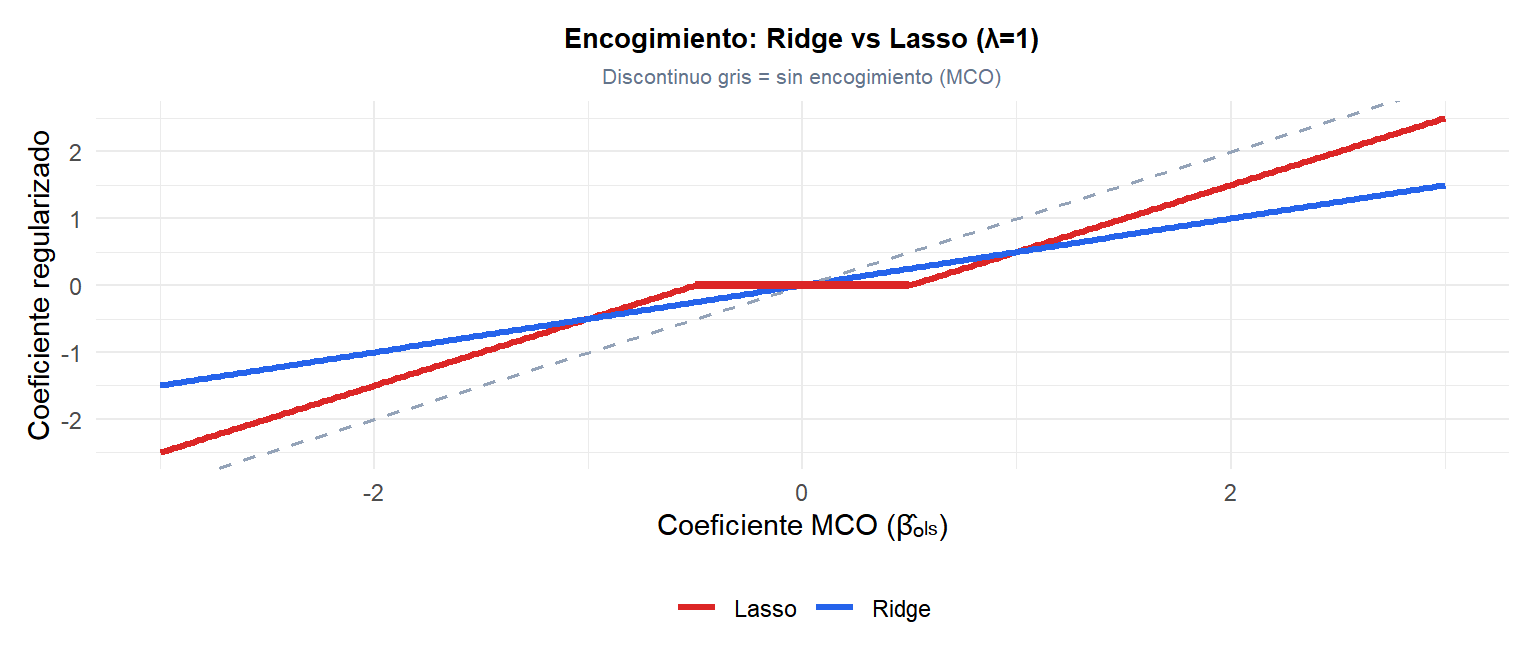
El segmento grueso rojo sobre el eje \(y=0\) muestra que para coeficientes MCO pequeños (entre \(-\lambda/2\) y \(+\lambda/2\)), Lasso devuelve exactamente cero. Esta zona muerta es la clave de la selección de variables.
Ruta de coeficientes
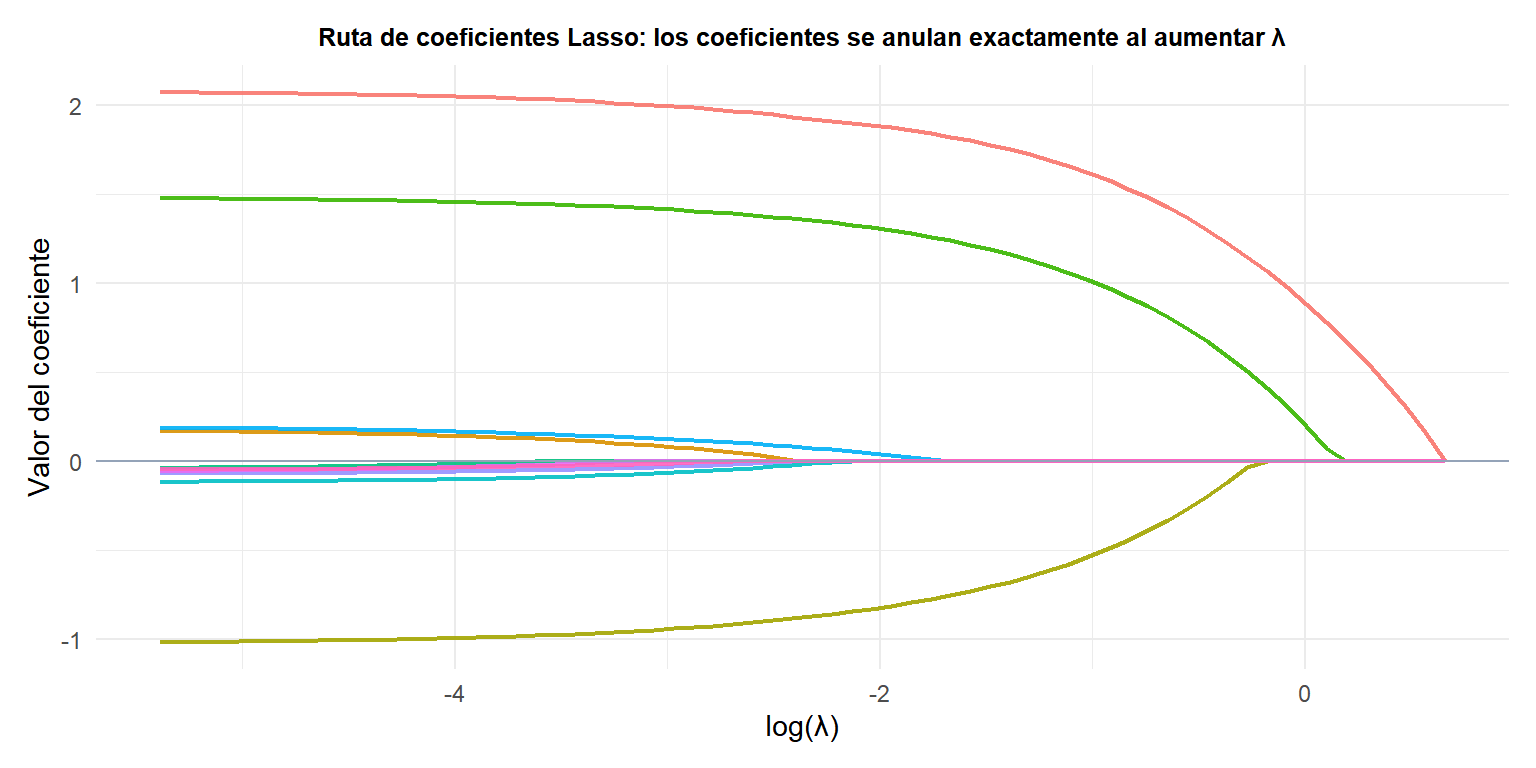
Cada línea de color es un predictor. Al aumentar \(\lambda\), los predictores irrelevantes se anulan exactamente (sus líneas tocan el eje \(y=0\)). Los tres últimos en anularse son los tres que tienen coeficiente verdadero no nulo.
Limitaciones del Lasso
Cuando hay predictores muy correlacionados, el Lasso tiene problemas:
- Selección arbitraria: entre dos predictores altamente correlacionados, el Lasso tiende a seleccionar uno y anular el otro arbitrariamente. ¿Cuál de los dos? Depende de pequeñas variaciones en los datos.
- Máximo \(\min(n, p)\) variables activas: la trayectoria del Lasso no puede seleccionar más de \(\min(n,p)\) variables activas simultáneamente.
Para estos casos, ElasticNet combina las penalizaciones \(L_1\) y \(L_2\) para aprovechar lo mejor de ambos métodos.
⚠️ Lasso no converge con multicolinealidad perfecta
Si dos predictores son perfectamente colineales (\(x_j = x_k\)), el Lasso no tiene una solución única: hay infinitas combinaciones de \(\beta_j\) y \(\beta_k\) con \(\beta_j + \beta_k\) constante que minimizan la pérdida. En la práctica, la multicolinealidad casi perfecta puede producir inestabilidad en los coeficientes seleccionados.
Comprueba la correlación entre predictores y el VIF antes de aplicar Lasso. Si hay variables con VIF muy alto, considera ElasticNet o agregar/eliminar predictores redundantes primero.
💡 Regresión Lasso en R
library(glmnet)
# Validación cruzada para Lasso (alpha=1)
cv_lasso <- cv.glmnet(X, y, alpha=1, nfolds=10)
plot(cv_lasso) # curva de validación cruzada
# Variables seleccionadas con lambda.min
coef(cv_lasso, s="lambda.min")
# Con lambda.1se (más parsimonioso, menos variables)
coef(cv_lasso, s="lambda.1se")
# Número de variables no nulas por lambda
fit_lasso <- glmnet(X, y, alpha=1)
fit_lasso$df # número de coeficientes != 0 por valor de lambda
# Ruta completa
plot(fit_lasso, xvar="lambda", label=TRUE)
