ElasticNet
ElasticNet combina las penalizaciones \(L_1\) (Lasso) y \(L_2\) (Ridge) en una sola función de pérdida. Hereda las ventajas de ambos: fuerza algunos coeficientes exactamente a cero como Lasso y agrupa predictores correlacionados como Ridge. Es el método de regularización más flexible cuando no se sabe a priori si el modelo verdadero es denso (muchos predictores pequeños) o disperso (pocos predictores grandes).
El estimador ElasticNet
\[\hat{\boldsymbol{\beta}}^{\text{EN}} = \arg\min_{\boldsymbol{\beta}} \left\{\|\mathbf{y} - \mathbf{X}\boldsymbol{\beta}\|^2 + \lambda\left[\alpha\|\boldsymbol{\beta}\|_1 + \frac{1-\alpha}{2}\|\boldsymbol{\beta}\|_2^2\right]\right\}\]
El parámetro \(\alpha \in [0,1]\) controla la mezcla:
- \(\alpha = 1\): Lasso puro (selección de variables, puede ser inestable con predictores correlacionados).
- \(\alpha = 0\): Ridge puro (encogimiento sin anular coeficientes).
- \(\alpha \in (0,1)\): ElasticNet (selección de variables + agrupamiento).
Valores habituales: \(\alpha = 0{,}5\) para comenzar; afinar con validación cruzada en una rejilla de \(\alpha\).
El efecto de agrupamiento
La principal ventaja de ElasticNet sobre Lasso es el efecto de agrupamiento: cuando dos predictores \(x_j\) y \(x_k\) están altamente correlacionados, ElasticNet tiende a incluirlos o excluirlos juntos y asignarles coeficientes similares. Lasso puede seleccionar uno y excluir el otro de forma arbitraria, lo que dificulta la interpretación.
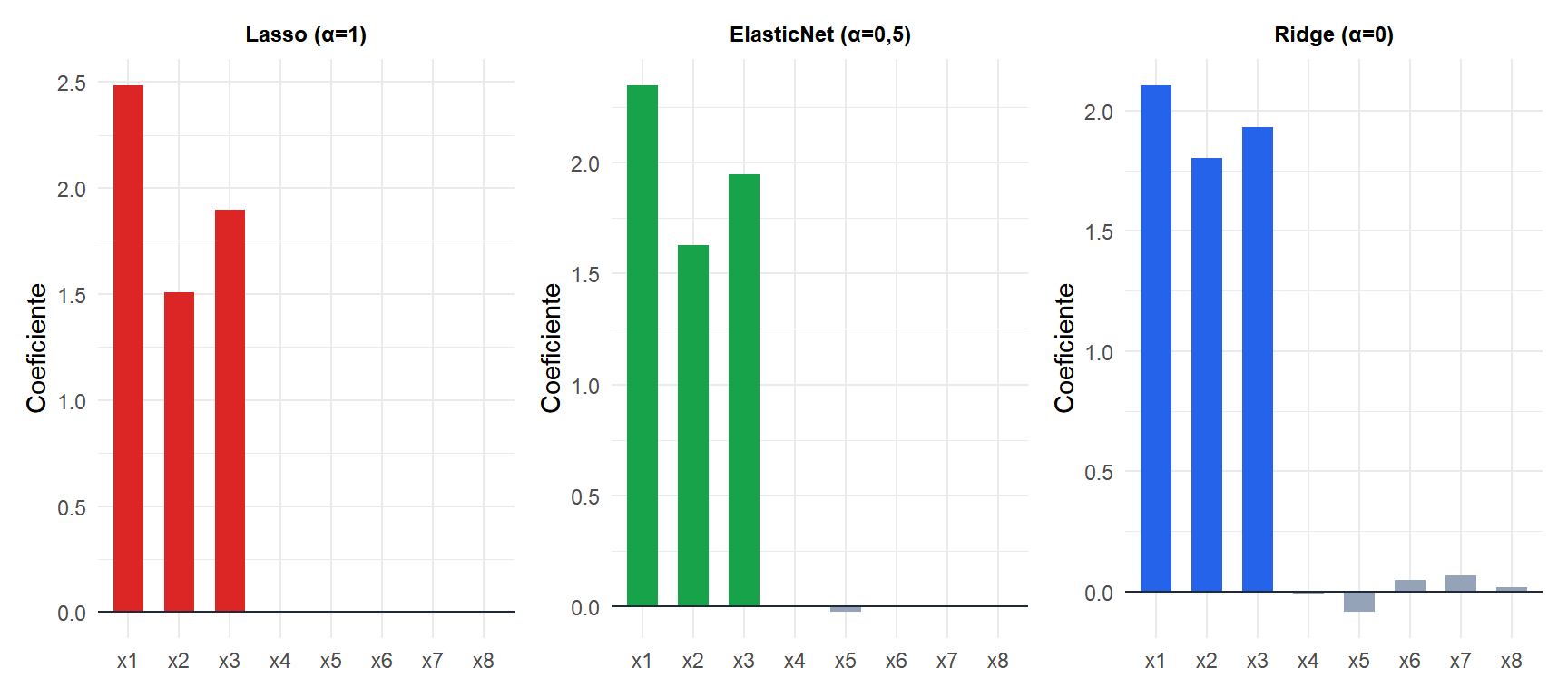
Con \(x_1, x_2, x_3\) altamente correlacionados (los tres deberían tener coeficiente \(\approx 2\), en azul oscuro), Lasso suele elegir solo uno y anular los otros. ElasticNet los selecciona todos con coeficientes similares. Ridge los incluye todos pero con coeficientes más pequeños.
Selección de hiperparámetros: rejilla sobre alpha y lambda
ElasticNet tiene dos hiperparámetros: \(\alpha\) y \(\lambda\). La selección estándar usa una rejilla bidimensional con validación cruzada:
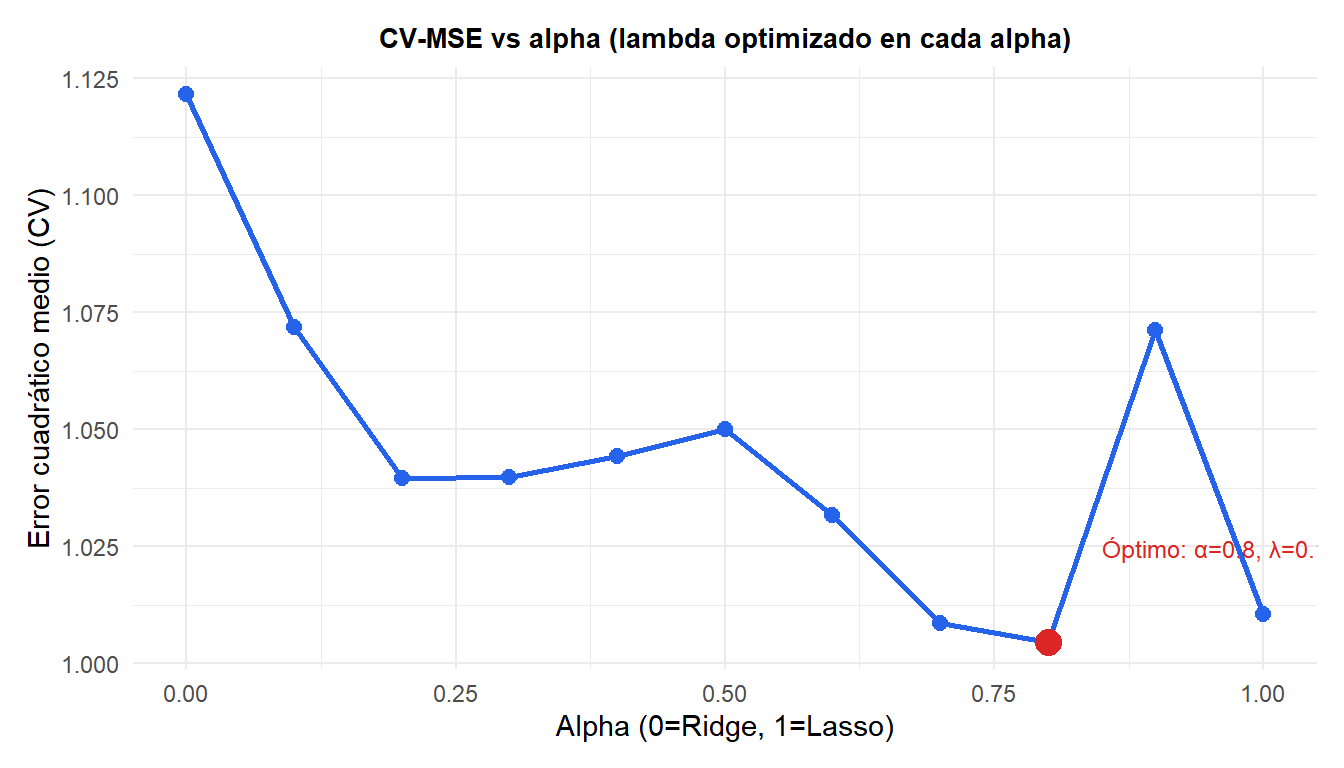
Resumen: Ridge, Lasso y ElasticNet
| Método | Penalización | Coeficientes a cero | Predictores correlacionados |
|---|---|---|---|
| Ridge | \(L_2\): \(\sum\beta_j^2\) | No (solo se encogen) | Agrupa, coeficientes similares |
| Lasso | \(L_1\): \(\sum|\beta_j|\) | Sí (selección automática) | Selecciona uno, anula los demás |
| ElasticNet | \(\alpha L_1 + (1-\alpha) L_2\) | Sí (con \(\alpha > 0\)) | Agrupa y selecciona |
Cuándo usar cada uno: - Ridge: muchos predictores con efectos pequeños; gran multicolinealidad; el objetivo es predicción, no interpretabilidad. - Lasso: sospechas de dispersión (pocos predictores relevantes); se desea un modelo interpretable. - ElasticNet: grupos de predictores correlacionados; incertidumbre sobre la dispersión del modelo; número de predictores mayor que \(n\).
💡 ElasticNet en R
library(glmnet)
# ElasticNet con alpha fijo
cv_en <- cv.glmnet(X, y, alpha=0.5, nfolds=10)
coef(cv_en, s="lambda.min")
plot(cv_en)
# Búsqueda en rejilla de alpha y lambda
alphas <- seq(0, 1, by=0.1)
results <- sapply(alphas, function(a) {
min(cv.glmnet(X, y, alpha=a, nfolds=10)$cvm)
})
best_alpha <- alphas[which.min(results)]
# Ajuste final con mejor alpha
cv_final <- cv.glmnet(X, y, alpha=best_alpha, nfolds=10)
coef(cv_final, s="lambda.min")
