Curva ROC y AUC
Un clasificador produce una puntuación para cada observación. Convertir puntuaciones en etiquetas de clase requiere elegir un umbral. La curva ROC muestra cómo se intercambian la sensibilidad y la especificidad a medida que el umbral varía por todo su rango. El AUC resume esta curva en un único número: la probabilidad de que el modelo clasifique una observación positiva aleatoria con una puntuación mayor que una negativa aleatoria.
De puntuaciones a predicciones: la matriz de confusión
Un clasificador binario asigna a cada observación una puntuación \(\hat{p} \in [0,1]\) y predice positivo si \(\hat{p} \geq t\) para algún umbral \(t\). Las predicciones resultantes se resumen en la matriz de confusión:
| Predicho positivo | Predicho negativo | |
|---|---|---|
| Realmente positivo | VP | FN |
| Realmente negativo | FP | VN |
Métricas clave derivadas de la matriz de confusión:
\[\text{Sensibilidad (Recall, TPR)} = \frac{VP}{VP+FN} \quad \text{(de todos los positivos, ¿cuántos detectamos?)}\]
\[\text{Especificidad} = \frac{VN}{VN+FP}, \quad \text{FPR} = 1 - \text{Especificidad} = \frac{FP}{FP+VN}\]
\[\text{Precisión (PPV)} = \frac{VP}{VP+FP} \quad \text{(de todos los predichos positivos, ¿cuántos son realmente positivos?)}\]
\[\text{Exactitud} = \frac{VP+VN}{n}\]
El umbral \(t\) controla el intercambio: un \(t\) menor detecta más positivos (TPR alta) pero también clasifica mal más negativos (FPR alta).
La curva ROC
La curva ROC (Receiver Operating Characteristic) representa la TPR (sensibilidad) en el eje y frente a la FPR (1-especificidad) en el eje x, para cada umbral posible \(t \in [0,1]\).
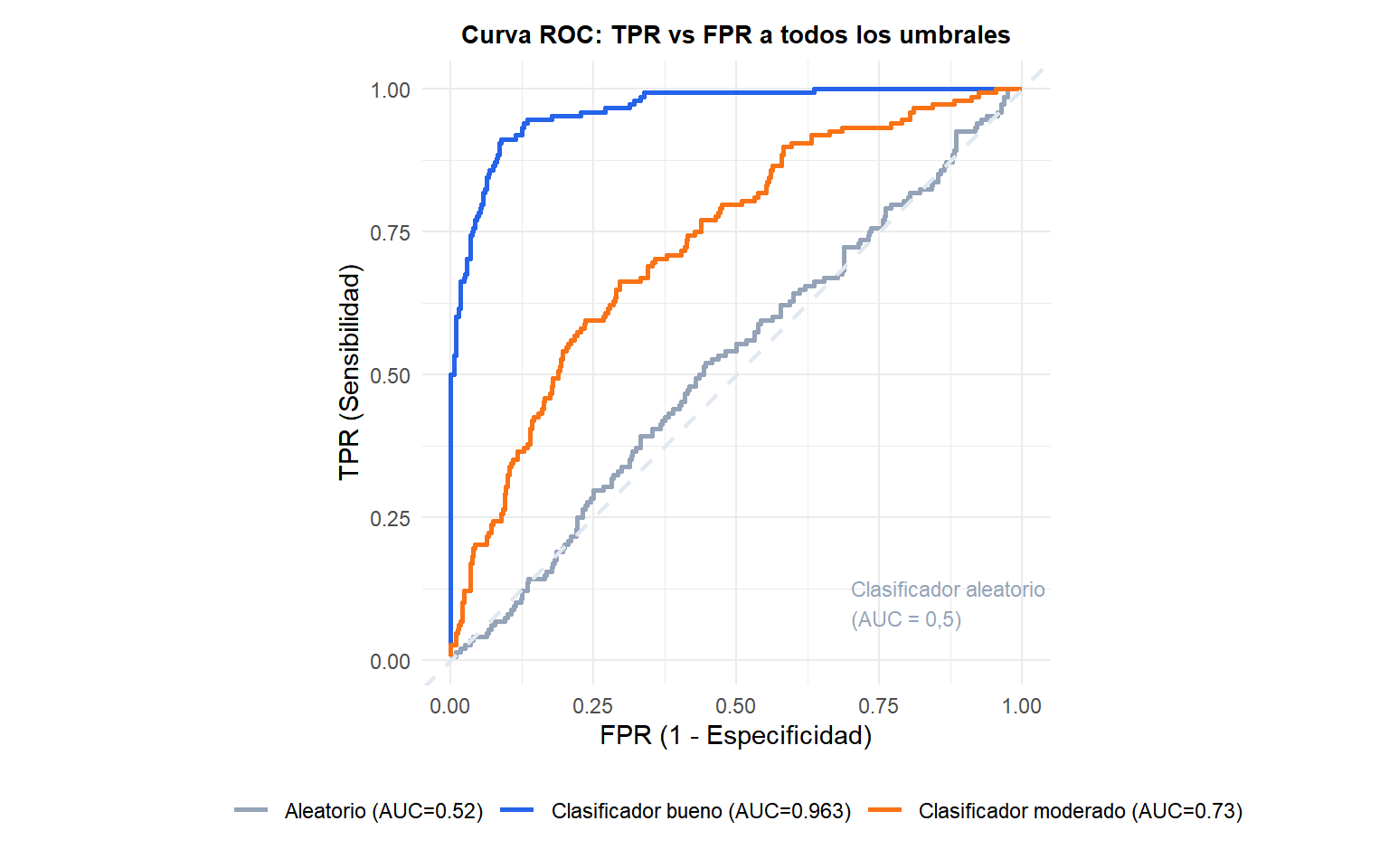
La línea diagonal representa un clasificador aleatorio (AUC = 0,5): logra la misma TPR que FPR a cada umbral, sin obtener nada de las puntuaciones. Un clasificador perfecto alcanzaría la esquina superior izquierda (TPR=1, FPR=0) y tendría AUC=1. Cuanto más se abomba la curva hacia la esquina superior izquierda, mejor es el clasificador.
AUC: área bajo la curva ROC
El AUC (Área Bajo la Curva) es la integral de la curva ROC:
\[\text{AUC} = \int_0^1 \text{TPR}(\text{FPR}^{-1}(t))\, dt\]
Tiene una interpretación probabilística clara (estadístico de Wilcoxon-Mann-Whitney):
\[\text{AUC} = P(\hat{p}_+ > \hat{p}_-)\]
La probabilidad de que una observación positiva elegida al azar reciba una puntuación mayor que una negativa elegida al azar. AUC = 0,5: ranking aleatorio. AUC = 1: ranking perfecto. AUC = 0: ranking perfectamente invertido.
Esta interpretación hace que el AUC sea independiente del umbral: mide la calidad del ranking de puntuaciones, no la calidad de ninguna decisión de umbral específica.
Elegir el umbral operativo
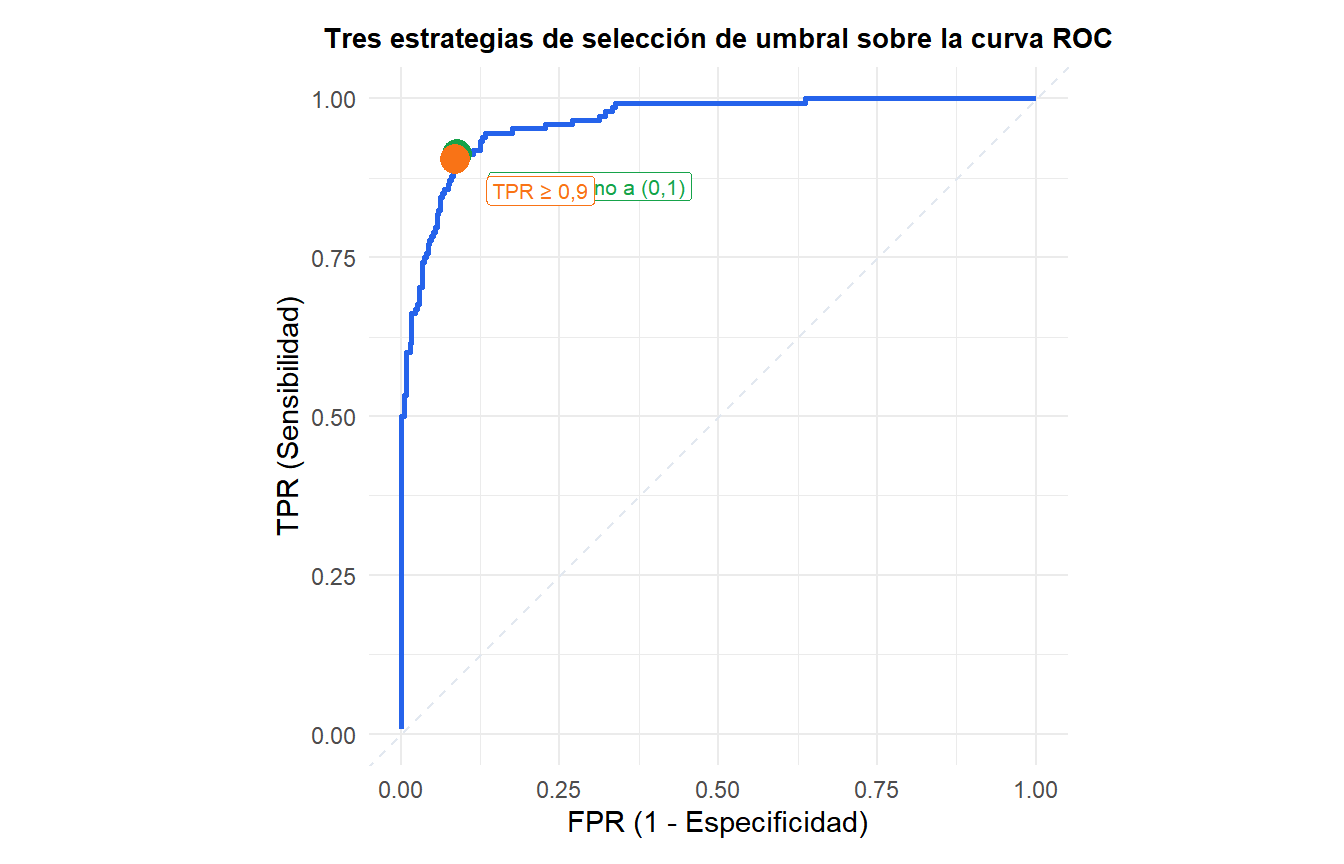
El AUC evalúa la calidad global del ranking, pero las decisiones reales requieren un umbral. Cómo elegir \(t\):
- Coste igual: maximizar la exactitud, o equivalentemente encontrar el umbral más cercano a la esquina superior izquierda de la curva ROC (distancia mínima a \((0,1)\)).
- Sensible al coste: si un falso negativo cuesta \(c\) veces más que un falso positivo, el umbral óptimo satisface la condición de pendiente sobre la curva ROC.
- Índice J de Youden: maximizar \(J = \text{TPR} - \text{FPR} = \text{Sensibilidad} + \text{Especificidad} - 1\).
- Restricción de dominio: fijar una FPR máxima aceptable (p. ej., en cribado, aceptar como máximo un 10% de falsos positivos) y encontrar el umbral que maximiza la TPR bajo esa restricción.
Curva de precisión-recuerdo
Para conjuntos de datos muy desequilibrados (p. ej., detección de fraude donde el 0,1% de los casos son positivos), la ROC y el AUC pueden ser engañosos: un clasificador que etiqueta todo como negativo logra FPR=0 y un AUC alto siendo completamente inútil.
La curva de Precisión-Recuerdo (PR) representa precisión vs recuerdo a todos los umbrales. Se centra en la clase positiva y es más informativa cuando:
- El conjunto de datos está muy desequilibrado.
- El coste de los falsos negativos y los falsos positivos es muy diferente.
- La clase rara es la clase de interés.
La precisión media (AP) resume la curva PR, análoga al AUC para la curva ROC.
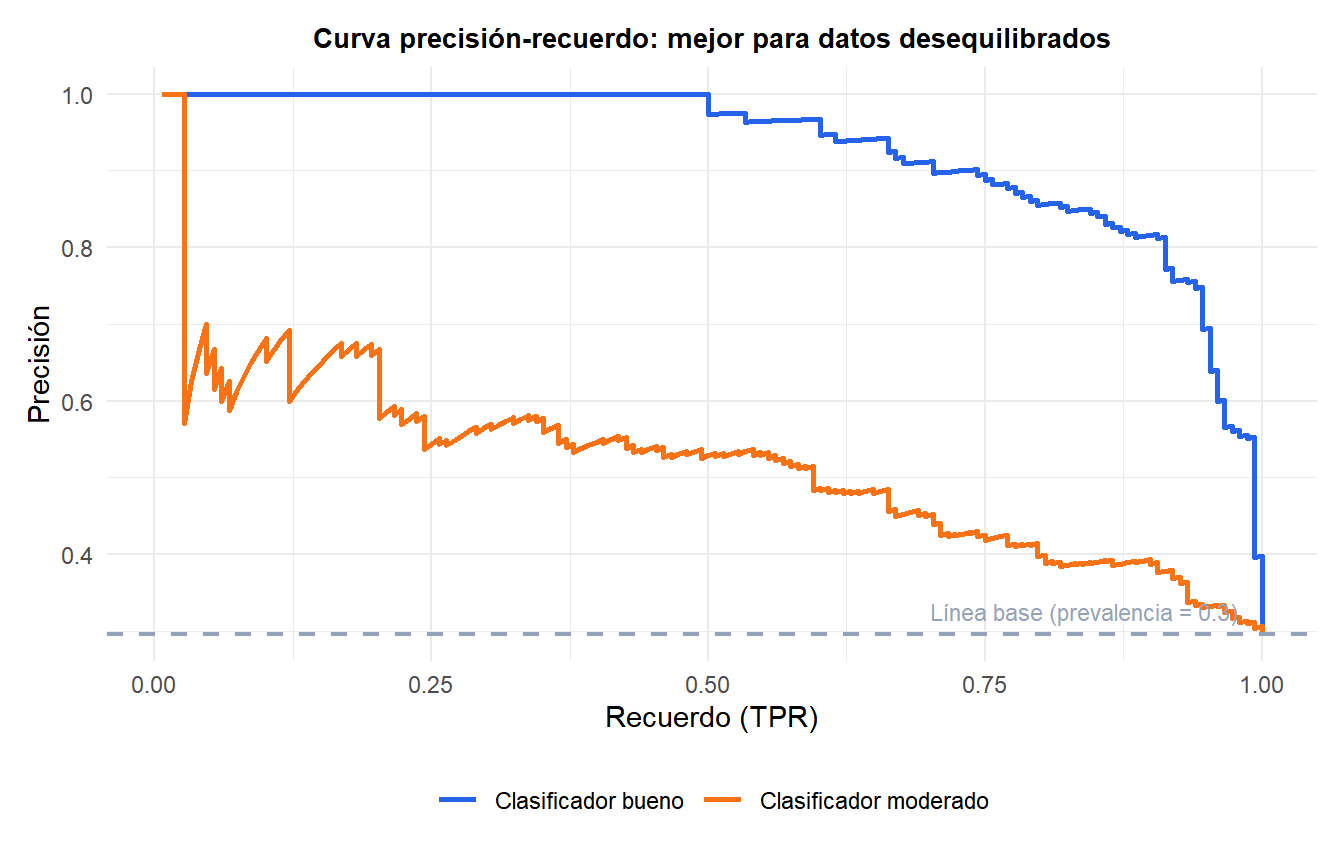
La línea base (discontinua) es la precisión lograda prediciendo aleatoriamente positivo con probabilidad igual a la prevalencia. Un clasificador útil debe mantenerse bien por encima de esta línea.
⚠️ El AUC no es la métrica correcta cuando las clases están gravemente desequilibradas
Considera un sistema de detección de fraude donde el 0,1% de las transacciones son fraudulentas. Un clasificador que siempre predice “no fraude” logra exactitud = 99,9%, AUC cercano a 0,5 (ligeramente superior, porque el azar aleatorio respeta el desequilibrio). Pero la precisión media podría ser cercana a cero.
Usa el AUC de la curva PR (o precisión media) en lugar del AUC-ROC cuando:
- La clase positiva es rara (prevalencia \(< 5\)-10%).
- Te preocupa principalmente detectar la clase rara.
- Los falsos positivos tienen costes muy diferentes a los falsos negativos.
Además: al comparar modelos con AUC, comprueba si la diferencia es estadísticamente significativa. El test de DeLong compara dos curvas ROC y proporciona un p-valor para la diferencia en AUC.
💡 ROC y AUC en R
library(pROC)
# Curva ROC y AUC
roc_obj <- roc(y_true, scores, levels=c(0,1), direction="<")
auc(roc_obj) # valor AUC
ci.auc(roc_obj) # IC 95% para AUC
plot(roc_obj, col="#2563EB") # gráfico ROC
# Comparar dos curvas ROC
roc1 <- roc(y_true, scores1)
roc2 <- roc(y_true, scores2)
roc.test(roc1, roc2) # test de DeLong
# Umbral óptimo por índice de Youden
coords(roc_obj, "best", best.method="youden")
# Precisión-Recuerdo
library(PRROC)
pr_obj <- pr.curve(scores.class1=scores[y_true==1],
scores.class0=scores[y_true==0],
curve=TRUE)
pr_obj$auc.integral # precisión media
plot(pr_obj)
# Evaluación completa con caret
library(caret)
confusionMatrix(pred_labels, true_labels, positive="1")
