Análisis discriminante
El Análisis Discriminante Lineal (LDA) y el Análisis Discriminante Cuadrático (QDA) clasifican observaciones modelando la distribución condicional de las características dado cada clase como gaussianas multivariantes y aplicando el teorema de Bayes. El LDA asume que todas las clases comparten la misma matriz de covarianza, dando fronteras de decisión lineales; el QDA permite a cada clase su propia covarianza, dando fronteras cuadráticas.
El modelo generativo
Tanto LDA como QDA modelan cada clase \(k\) como una gaussiana multivariante:
\[P(\mathbf{x} \mid C=k) = \frac{1}{(2\pi)^{p/2}|\boldsymbol{\Sigma}_k|^{1/2}} \exp\!\left(-\frac{1}{2}(\mathbf{x}-\boldsymbol{\mu}_k)^T\boldsymbol{\Sigma}_k^{-1}(\mathbf{x}-\boldsymbol{\mu}_k)\right)\]
Aplicando el teorema de Bayes, la probabilidad a posteriori de la clase \(k\) es:
\[P(C=k \mid \mathbf{x}) \propto \pi_k \cdot P(\mathbf{x} \mid C=k)\]
donde \(\pi_k = P(C=k)\) es la probabilidad a priori de la clase \(k\), estimada como la proporción de la clase en los datos de entrenamiento.
Análisis Discriminante Lineal (LDA)
El LDA añade la restricción \(\boldsymbol{\Sigma}_1 = \boldsymbol{\Sigma}_2 = \cdots = \boldsymbol{\Sigma}_K = \boldsymbol{\Sigma}\) (matrices de covarianza iguales). Bajo esta restricción, el cociente de log-posteriores entre dos clases se simplifica a una función lineal de \(\mathbf{x}\):
\[\delta_k(\mathbf{x}) = \mathbf{x}^T\boldsymbol{\Sigma}^{-1}\boldsymbol{\mu}_k - \frac{1}{2}\boldsymbol{\mu}_k^T\boldsymbol{\Sigma}^{-1}\boldsymbol{\mu}_k + \log\pi_k\]
\[\hat{c} = \arg\max_k \delta_k(\mathbf{x})\]
El término cuadrático \(\mathbf{x}^T\boldsymbol{\Sigma}^{-1}\mathbf{x}\) es el mismo para todas las clases y se cancela en la comparación, dejando una función lineal de \(\mathbf{x}\). La frontera de decisión entre las clases \(j\) y \(k\) es el conjunto de puntos donde \(\delta_j(\mathbf{x}) = \delta_k(\mathbf{x})\): un hiperplano.
Estimación de parámetros: \(\hat{\boldsymbol{\mu}}_k\) = medias muestrales por clase; \(\hat{\boldsymbol{\Sigma}}\) = covarianza muestral ponderada dentro de clase.
Criterio de Fisher: maximizar la separación entre clases
Una forma equivalente de derivar el LDA: encontrar la dirección de proyección \(\mathbf{w}\) que maximiza el cociente entre la varianza entre clases y la varianza dentro de clase tras proyectar los datos sobre \(\mathbf{w}\):
\[\mathbf{w}^* = \arg\max_{\mathbf{w}} \frac{\mathbf{w}^T \mathbf{S}_B \mathbf{w}}{\mathbf{w}^T \mathbf{S}_W \mathbf{w}}\]
donde \(\mathbf{S}_B = \sum_k n_k(\boldsymbol{\mu}_k - \boldsymbol{\mu})(\boldsymbol{\mu}_k - \boldsymbol{\mu})^T\) es la matriz de dispersión entre clases y \(\mathbf{S}_W = \sum_k \sum_{i \in C_k}(\mathbf{x}_i - \boldsymbol{\mu}_k)(\mathbf{x}_i - \boldsymbol{\mu}_k)^T\) es la matriz de dispersión dentro de clase.
La solución es \(\mathbf{w}^* = \mathbf{S}_W^{-1}(\boldsymbol{\mu}_1 - \boldsymbol{\mu}_2)\) para dos clases. Para \(K\) clases, las primeras \(K-1\) direcciones discriminantes son los vectores propios de \(\mathbf{S}_W^{-1}\mathbf{S}_B\) correspondientes a los mayores valores propios.
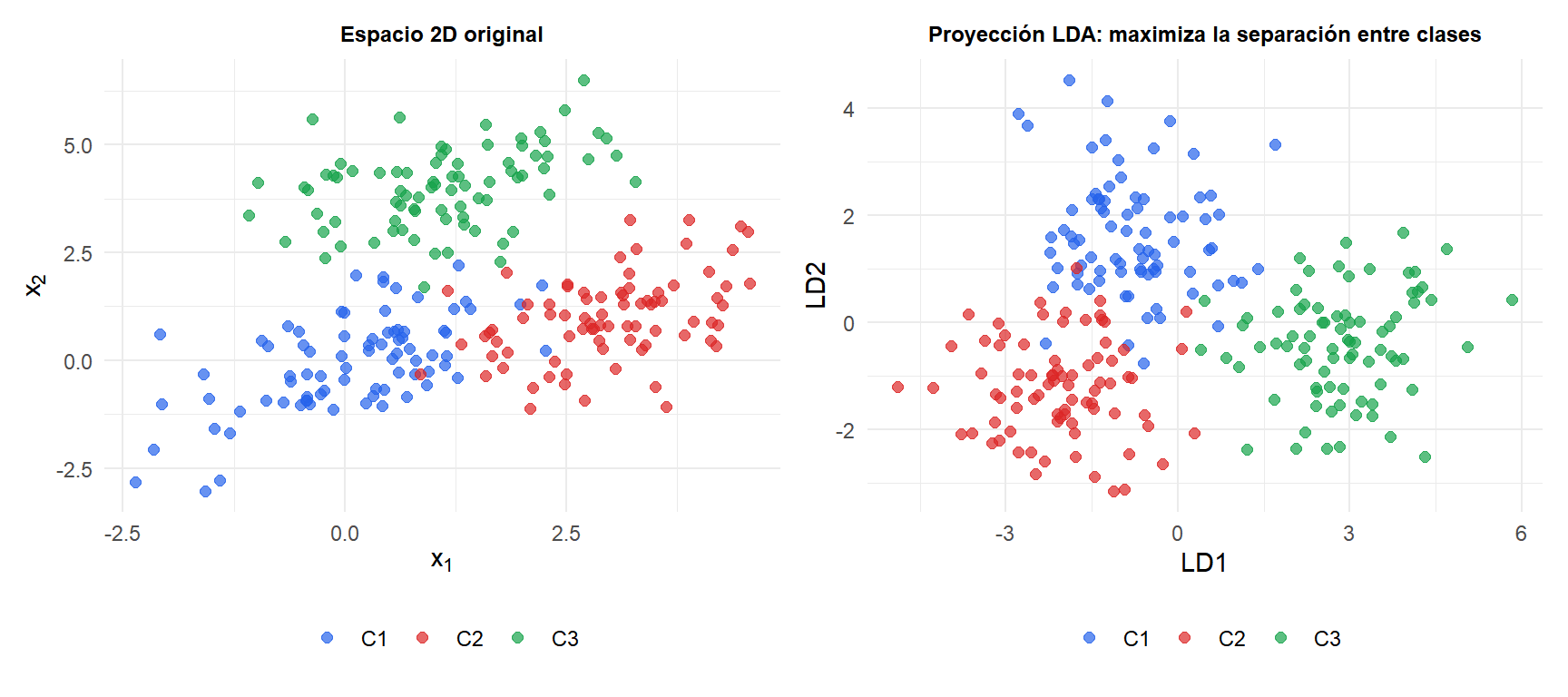
Esta es la perspectiva de reducción de dimensionalidad del LDA: proyectar sobre las \(K-1\) direcciones que mejor separan las clases, y luego clasificar en el espacio reducido.
Análisis Discriminante Cuadrático (QDA)
El QDA relaja el supuesto de covarianza igual. Cada clase tiene su propia covarianza \(\boldsymbol{\Sigma}_k\), y el log-posterior no se simplifica a una función lineal:
\[\delta_k(\mathbf{x}) = -\frac{1}{2}\log|\boldsymbol{\Sigma}_k| - \frac{1}{2}(\mathbf{x}-\boldsymbol{\mu}_k)^T\boldsymbol{\Sigma}_k^{-1}(\mathbf{x}-\boldsymbol{\mu}_k) + \log\pi_k\]
El término \((\mathbf{x}-\boldsymbol{\mu}_k)^T\boldsymbol{\Sigma}_k^{-1}(\mathbf{x}-\boldsymbol{\mu}_k)\) es la distancia de Mahalanobis al cuadrado desde \(\mathbf{x}\) hasta el centroide de la clase \(k\), ponderada por la covarianza de la clase. La frontera de decisión entre las clases \(j\) y \(k\) es una superficie cuadrática (elipse, parábola o hipérbola en 2D).
El QDA estima \(p(p+1)/2\) parámetros por clase para la matriz de covarianza, frente a la única \(\boldsymbol{\Sigma}\) agrupada del LDA. Con \(K\) clases: QDA tiene \(K \cdot p(p+1)/2\) parámetros de covarianza frente a \(p(p+1)/2\) del LDA.
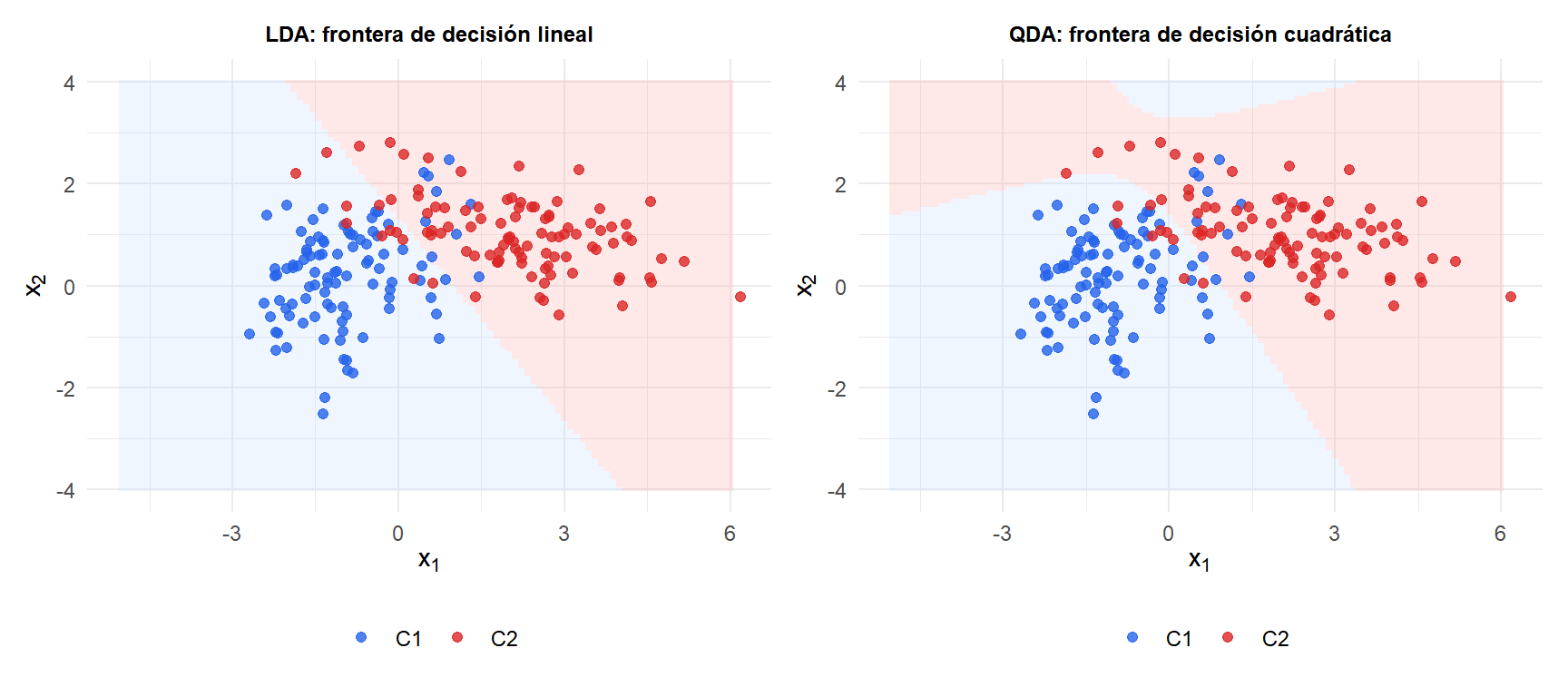
Con covarianzas desiguales (C2 tiene mayor varianza y correlación negativa), el LDA fuerza una frontera recta que clasifica mal los puntos en las colas. El QDA curva la frontera para ajustarse mejor a la estructura real de las clases.
LDA como reducción de dimensionalidad
Para \(K\) clases en \(p\) dimensiones, el LDA proyecta los datos sobre como máximo \(K-1\) direcciones discriminantes antes de clasificar. Esto hace del LDA un paso de preprocesamiento útil:
- Reduce \(p\) dimensiones a \(K-1\) para visualización o como entrada a otro clasificador.
- A diferencia del PCA (que maximiza la varianza total), el LDA maximiza la separación entre clases en el espacio reducido.
- Para \(K=2\): un único eje discriminante separa las dos clases. Representa la proyección 1D para visualizar la separabilidad.
- Para \(K=3\): dos ejes discriminantes dan un gráfico 2D que muestra la estructura de las clases.
⚠️ El LDA falla cuando el supuesto de covarianza igual se viola fuertemente
Cuando las clases tienen covarianzas muy distintas, la frontera lineal del LDA está mal especificada y la precisión se degrada. Señales de violación: dispersión o forma muy diferente de las nubes de puntos por clase, matrices de covarianza numéricamente muy distintas.
Comprueba con el test M de Box (biotools::boxM()) para la igualdad formal de matrices de covarianza. Si se rechaza, usa QDA. Ten en cuenta que el QDA necesita más datos: cada clase necesita al menos \(p+1\) observaciones para estimar su matriz de covarianza, e idealmente muchas más para estimaciones estables.
LDA vs QDA vs regresión logística
| LDA | QDA | Regresión logística | |
|---|---|---|---|
| Frontera de decisión | Lineal | Cuadrática | Lineal (estándar) |
| Supuesto | Gaussiana, \(\boldsymbol{\Sigma}\) igual | Gaussiana, \(\boldsymbol{\Sigma}\) distintas | Ninguno sobre \(P(\mathbf{x})\) |
| Parámetros | Pocos | Más (\(K\) covarianzas) | \(p+1\) |
| Estable con \(n\) pequeño | Sí | Necesita más datos | Sí |
| También hace red. dim. | Sí (\(K-1\) ejes) | No | No |
| Sensible a valores atípicos | Moderado | Más | Menos |
El LDA tiende a superar a la regresión logística cuando el supuesto gaussiano es aproximadamente correcto y \(n\) es pequeño. La regresión logística es más robusta ante características no gaussianas y valores atípicos. El QDA gana cuando las clases tienen genuinamente estructuras de covarianza distintas y hay suficientes datos para estimarlas de forma fiable.
💡 Análisis discriminante en R
library(MASS)
# LDA
fit_lda <- lda(y ~ ., data=df_train)
predict(fit_lda, newdata=df_test)$class # clases predichas
predict(fit_lda, newdata=df_test)$posterior # probabilidades a posteriori
predict(fit_lda, newdata=df_test)$x # puntuaciones LD (para graficar)
# QDA
fit_qda <- qda(y ~ ., data=df_train)
predict(fit_qda, newdata=df_test)$class
# Test de igualdad de covarianzas (test M de Box)
library(biotools)
boxM(df_train[,-1], df_train$y)
# LDA regularizado (para p cercano a n)
library(klaR)
fit_rda <- rda(y ~ ., data=df_train, gamma=0.05, lambda=0.2)
