Agrupamiento jerárquico
El agrupamiento jerárquico construye una secuencia anidada de clusters sin necesitar el número de clusters \(K\) de antemano. El resultado es un dendrograma: un árbol donde cada hoja es una observación y cada nodo interno registra cuándo se fusionaron dos clusters. Cortar el árbol a cualquier altura produce un agrupamiento plano. El método de enlace, que define la distancia entre clusters, tiene un impacto mayor en el resultado que casi cualquier otra elección.
Agrupamiento aglomerativo
La variante más común es el aglomerativo (ascendente):
- Comienza con \(n\) clusters, uno por observación.
- Calcula la matriz de disimilitud \(n \times n\).
- Fusiona los dos clusters más cercanos en uno.
- Actualiza la matriz de disimilitud (cómo se calculan las distancias del nuevo cluster depende del enlace).
- Repite los pasos 3-4 hasta que quede un cluster.
El historial de fusiones se almacena en el dendrograma. La altura a la que se fusionan dos observaciones (o clusters) refleja su disimilitud: fusiones bajas = similares, fusiones altas = disimilares.
El agrupamiento divisivo trabaja de arriba abajo: comienza con todas las observaciones en un cluster y lo divide recursivamente. Computacionalmente más costoso y menos utilizado.
Métodos de enlace
El método de enlace define la distancia \(d(A, B)\) entre dos clusters \(A\) y \(B\) basándose en las distancias entre sus puntos constituyentes:
| Enlace | Fórmula | Forma de los clusters |
|---|---|---|
| Simple | \(\min_{a \in A, b \in B} d(a,b)\) | Elongados, efecto cadena |
| Completo | \(\max_{a \in A, b \in B} d(a,b)\) | Compactos, aproximadamente esféricos |
| Promedio (UPGMA) | \(\frac{1}{|A||B|}\sum_{a,b} d(a,b)\) | Entre simple y completo |
| Centroide | \(d(\bar{a}, \bar{b})\) | Puede invertirse (no monótono) |
| Ward | Aumento de la WCSS total al fusionar \(A\) y \(B\) | Compactos, de tamaño similar |
El enlace de Ward fusiona el par de clusters que minimiza el aumento en la suma de cuadrados intra-cluster total. Tiende a producir clusters compactos y de tamaño aproximadamente igual, y es la elección predeterminada para la mayoría de aplicaciones con datos continuos.
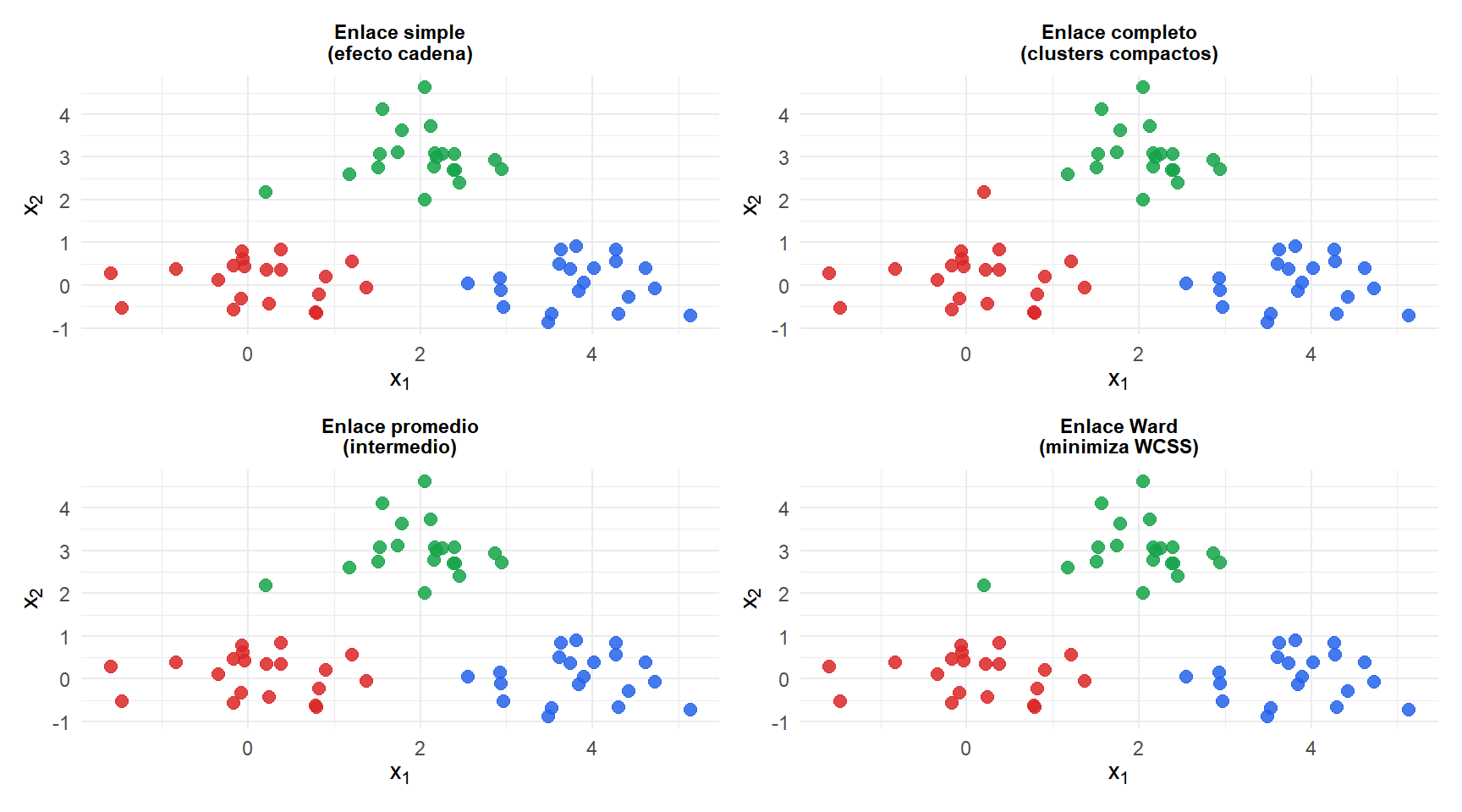
El enlace simple (arriba izquierda) encadena clusters, produciendo a menudo grupos elongados. El enlace completo produce clusters compactos. El promedio es intermedio. Ward (abajo derecha) produce los clusters más equilibrados y compactos, y generalmente se ajusta mejor a la agrupación visual.
Leer el dendrograma
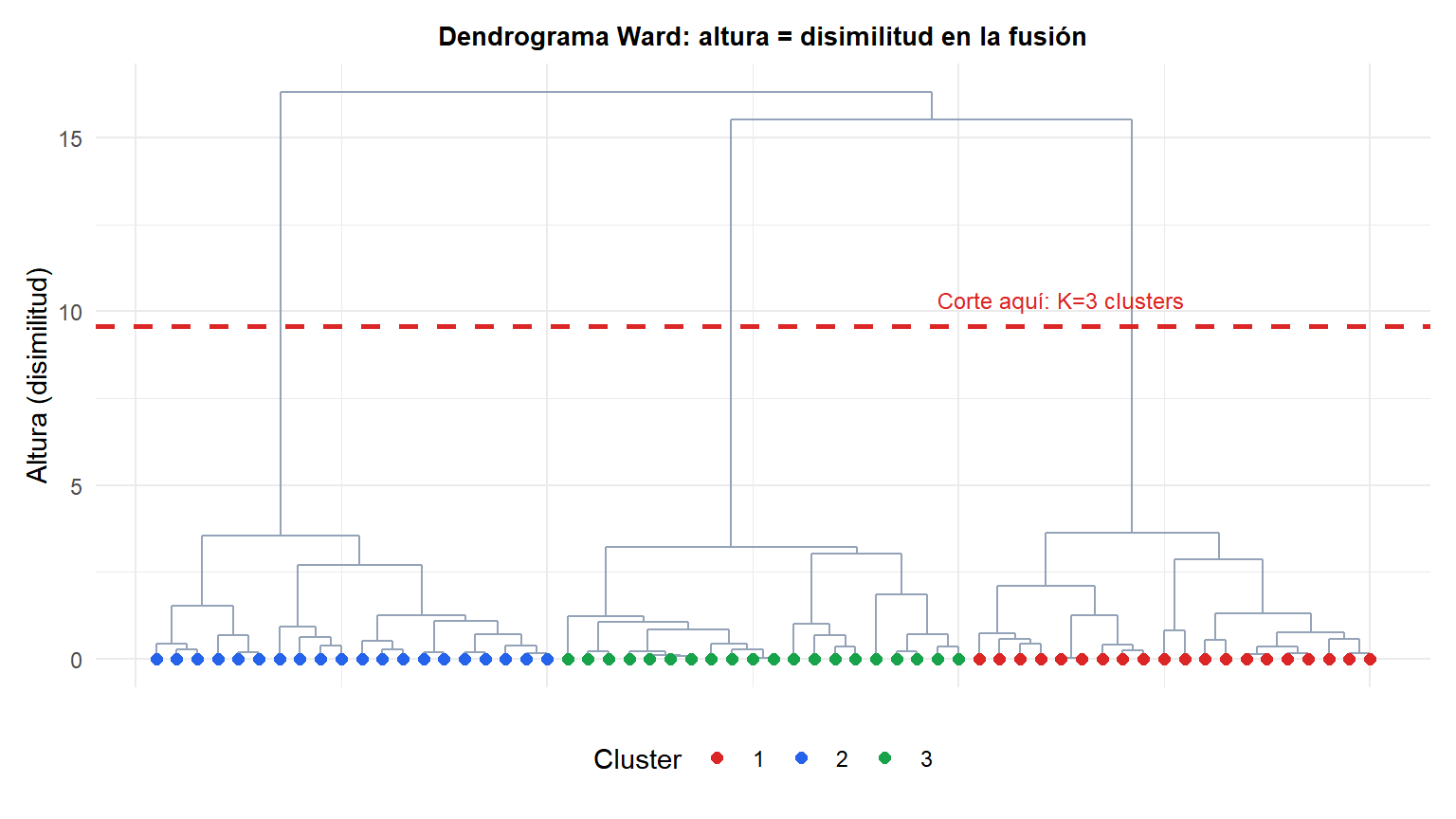
La línea roja discontinua corta el árbol a una altura elegida. Cada línea vertical que cruza se convierte en un cluster. Aquí, cortar a esta altura da tres clusters (coincidiendo con la estructura real). El eje de altura representa la disimilitud: las fusiones bajas en el árbol unen observaciones similares; las fusiones cerca de la cima unen grupos muy diferentes.
Elegir la altura de corte: busca el mayor salto entre alturas de fusión consecutivas. Un salto grande significa que los dos niveles de la jerarquía son muy diferentes: el corte justo por debajo del salto es un número natural de clusters.
Matrices de distancia y datos no euclídeos
El agrupamiento jerárquico funciona con cualquier matriz de disimilitud, no solo con la distancia euclídea. Esto lo hace aplicable a tipos de datos donde la distancia euclídea carece de sentido:
- Texto: distancia coseno o de edición entre documentos.
- Datos categóricos: distancia de Gower (maneja tipos mixtos).
- Secuencias: distancia de edición (Levenshtein) para secuencias de ADN o proteínas.
- Series temporales: distancia de deformación temporal dinámica (DTW).
- Basada en correlación: \(1 - r_{ij}\) donde \(r_{ij}\) es la correlación de Pearson. Ampliamente usada en genómica para agrupar genes con perfiles de expresión similares.
K-medias requiere calcular medias (centroides) y por tanto solo funciona con distancia euclídea sobre datos continuos. El agrupamiento jerárquico funciona con cualquier disimilitud personalizada.
Agrupamiento jerárquico vs k-medias
| Jerárquico | K-medias | |
|---|---|---|
| Requiere K de antemano | No | Sí |
| Resultado | Jerarquía completa (dendrograma) | Partición plana |
| Determinista | Sí | No (init. aleatoria) |
| Escalabilidad | \(O(n^2)\) a \(O(n^3)\) | \(O(nKI)\), rápido |
| Datos no euclídeos | Sí (cualquier disimilitud) | No |
| Formas de cluster | Flexibles (depende del enlace) | Solo esféricas |
| Sensibilidad a valores atípicos | Alta (especialmente enlace simple) | Moderada |
Usa agrupamiento jerárquico cuando: no conoces \(K\), quieres explorar la jerarquía, los datos no son euclídeos, o \(n\) es suficientemente pequeño para la complejidad cuadrática (\(n < 10{,}000\) típicamente).
Usa k-medias cuando: \(K\) se conoce o puede estimarse, los datos son grandes y los clusters son aproximadamente esféricos.
⚠️ El enlace simple casi nunca es la elección correcta
El enlace simple es notorio por el efecto cadena: un único punto puente conectando dos clusters hace que se fusionen prematuramente, creando clusters largos en forma de cadena que no reflejan la estructura real. A menos que los clusters verdaderos sean genuinamente filamentosos (raro), comienza siempre con Ward, completo o promedio y solo considera el enlace simple si hay una razón específica.
💡 Agrupamiento jerárquico en R
# Calcular la matriz de disimilitud
d <- dist(X, method="euclidean") # o "manhattan", "maximum"
# Ajustar el agrupamiento jerárquico
hc <- hclust(d, method="ward.D2") # o "complete", "average", "single"
# Visualizar el dendrograma
plot(hc, labels=FALSE, hang=-1)
rect.hclust(hc, k=3, border="red") # dibuja K clusters
# Cortar a K clusters
clusters <- cutree(hc, k=3)
# O cortar a una altura específica
clusters <- cutree(hc, h=5)
# No euclídeo: distancia de Gower para datos mixtos
library(cluster)
d_gower <- daisy(df_mixed, metric="gower")
hc_g <- hclust(d_gower, method="ward.D2")
# Dendrogramas elegantes
library(ggdendro)
ggdendrogram(hc, rotate=FALSE, labels=FALSE)
