Difference between Two Events (Set Difference)
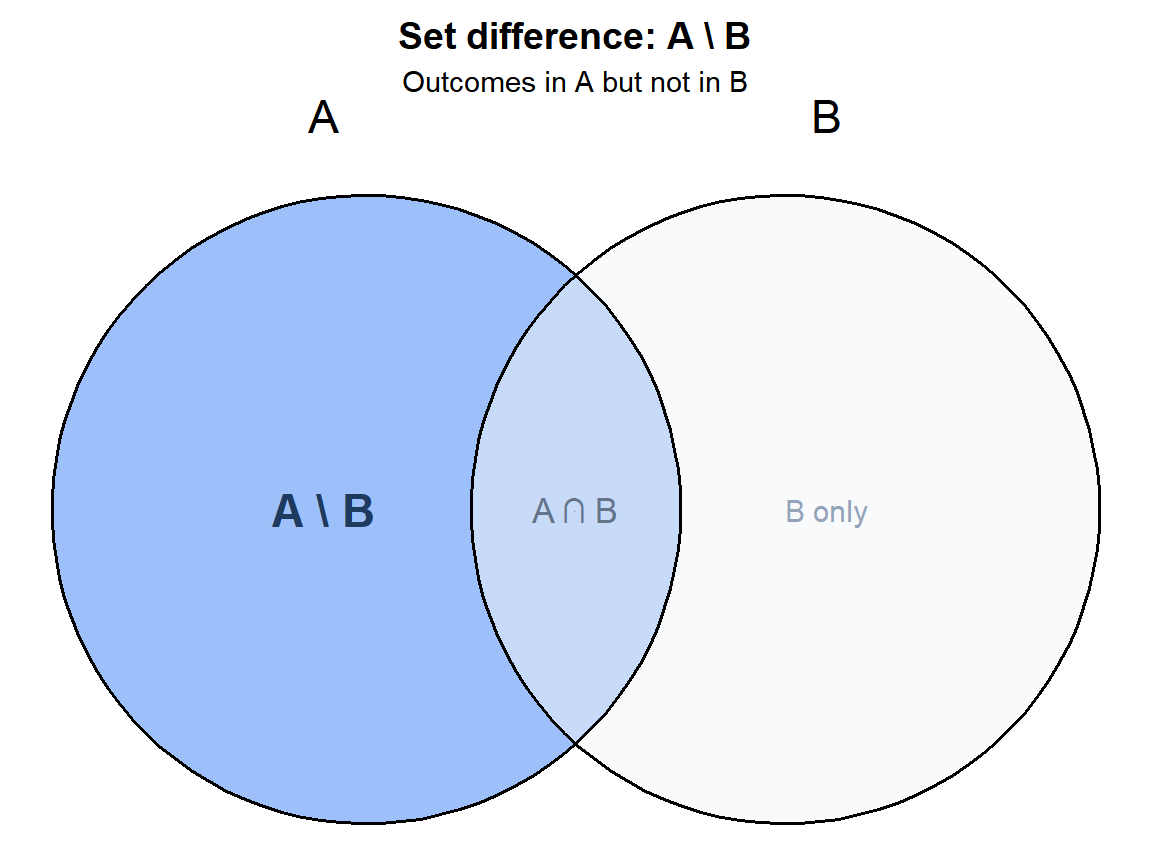
The difference \(A \setminus B\) is the event that \(A\) occurs but \(B\) does not. It isolates the part of \(A\) that has nothing to do with \(B\), and its probability is simply \(P(A) - P(A \cap B)\).
Definition
Let \(A\) and \(B\) be two events on the same sample space \(\Omega\). The set difference \(A \setminus B\) (also written \(A - B\)) is the event that \(A\) occurs and \(B\) does not:
\[A \setminus B = \{\omega \in \Omega : \omega \in A \text{ and } \omega \notin B\} = A \cap B^c\]
Its probability follows directly from this definition:
\[P(A \setminus B) = P(A) - P(A \cap B)\]
Subtracting \(P(A \cap B)\) removes the outcomes that \(A\) shares with \(B\), leaving only those exclusive to \(A\).
Relationship with other operations
The set difference connects naturally to the other operations:
- \(A \setminus B = A \cap B^c\): the difference is an intersection with the complement.
- \(A = (A \setminus B) \cup (A \cap B)\): event \(A\) is partitioned into what it shares with \(B\) and what it does not.
- \(P(A \setminus B) + P(A \cap B) = P(A)\): the two parts of \(A\) add up to \(P(A)\).
- \(A \setminus B\) and \(B \setminus A\) are always mutually exclusive.
- \((A \setminus B) \cup (B \setminus A) = A \triangle B\): the union of both differences is the symmetric difference.
⚠️ A \\ B and B \\ A are different events
The set difference is not symmetric: \(A \setminus B \neq B \setminus A\) in general. \(A \setminus B\) is “in \(A\) but not \(B\)”, while \(B \setminus A\) is “in \(B\) but not \(A\)”. Swapping the order gives a completely different event.
Examples
Example 1: customer segmentation
An e-commerce platform has 10,000 customers. Based on last month’s activity: - 4,200 made a purchase (\(A\)). - 3,500 visited the site but did not purchase (\(B\)). - 1,800 both made a purchase and visited the site multiple times (\(A \cap B\)… here \(B\) means “frequent visitor”).
Actually, let’s use a cleaner setup:
- \(A\) = customer made a purchase last month: \(P(A) = 0.42\)
- \(B\) = customer opened a promotional email: \(P(B) = 0.35\)
- \(A \cap B\) = purchased and opened the email: \(P(A \cap B) = 0.18\)
Event \(A \setminus B\): customers who purchased but did not open the promotional email (organic buyers).
\[P(A \setminus B) = P(A) - P(A \cap B) = 0.42 - 0.18 = 0.24\]
24% of customers purchased without engaging with the email campaign. These are worth targeting differently from the 18% who responded to the email.
Event \(B \setminus A\): customers who opened the email but did not purchase (interested but unconverted).
\[P(B \setminus A) = P(B) - P(A \cap B) = 0.35 - 0.18 = 0.17\]
17% of customers engaged with the email but did not convert. This is the re-targeting audience.
Example 2: quality control
In a manufacturing process, components are tested for two types of defects: - \(A\) = structural defect: \(P(A) = 0.08\) - \(B\) = surface defect: \(P(B) = 0.05\) - Both defects: \(P(A \cap B) = 0.02\)
Structural defect only (must be scrapped entirely):
\[P(A \setminus B) = 0.08 - 0.02 = 0.06\]
Surface defect only (can be reworked):
\[P(B \setminus A) = 0.05 - 0.02 = 0.03\]
The distinction matters operationally: 6% of components go to scrap, 3% go to rework, and 2% need both treatments.
In a batch of 1,000 components:
| Surface defect | No surface defect | Total | |
|---|---|---|---|
| Structural defect | 20 | 60 | 80 |
| No structural defect | 30 | 890 | 920 |
| Total | 50 | 950 | 1,000 |
\(A \setminus B\): structural defect only = 60 items → \(60/1000 = 0.06\) ✓
\(B \setminus A\): surface defect only = 30 items → \(30/1000 = 0.03\) ✓
\(A \cap B\): both defects = 20 items → \(20/1000 = 0.02\) ✓
Example 3: network security
A security team monitors two types of alerts: - \(A\) = intrusion detection alert triggered: \(P(A) = 0.12\) - \(B\) = firewall block triggered: \(P(B) = 0.20\) - Both triggered simultaneously: \(P(A \cap B) = 0.07\)
Intrusion alert without firewall block (potentially unblocked threat, high priority):
\[P(A \setminus B) = 0.12 - 0.07 = 0.05\]
Firewall block without intrusion alert (blocked before detection, lower priority):
\[P(B \setminus A) = 0.20 - 0.07 = 0.13\]
The 5% of incidents in \(A \setminus B\) represent the most dangerous scenario: something triggered the intrusion detector but was not caught by the firewall.
💡 When to use the set difference
Use \(A \setminus B\) when you want to isolate the part of \(A\) that is unrelated to \(B\). Common scenarios:
- Segmenting a population into non-overlapping groups (purchased but did not open email, opened but did not purchase, both, neither).
- Calculating the probability of exactly one of two events occurring: \(P(A \setminus B) + P(B \setminus A) = P(A) + P(B) - 2P(A \cap B)\).
- Decomposing an event into disjoint parts for easier calculation.

